UNDO
DB CAFE
(UNDO REDO에서 넘어옴)
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
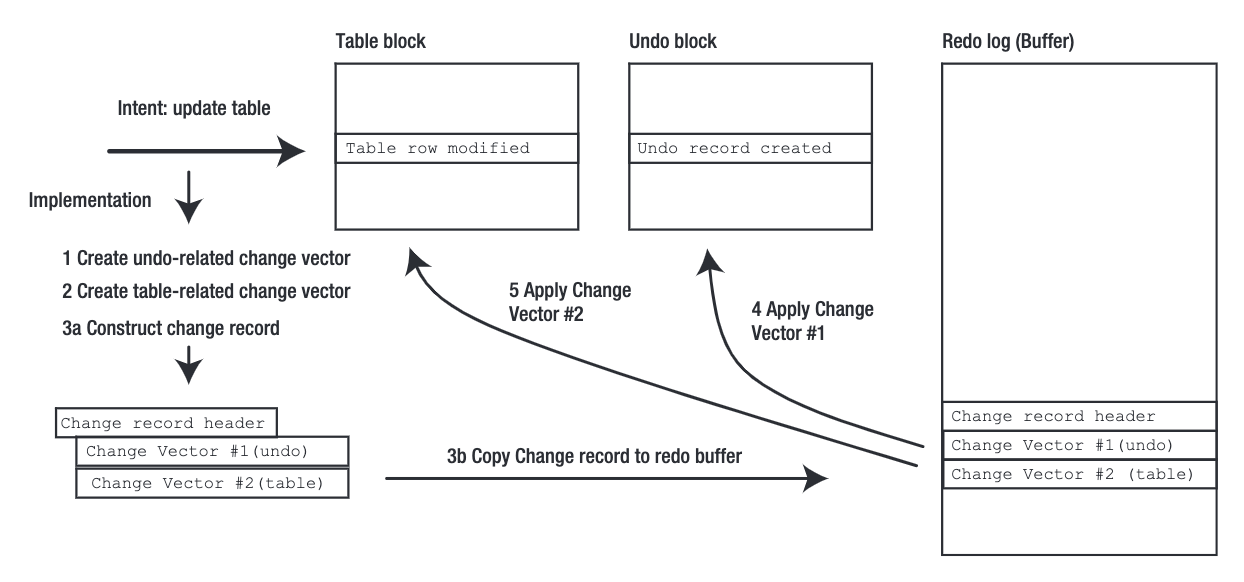
1 Undo 와 Redo[편집]
filter_1 Undo
: 롤백(RollBack)을 위해서 UNDO 테이블스페이스( DISK )에 기록
filter_2 Redo
: 시스템 복구를 위해 시스템에 로그를 기록(redo log buffer,리두로그버퍼- MEMORY)
2 UNDO ?[편집]
- Undo = Rollback,롤백
- Undo Data
- - 원본 데이터
- Undo Tablespace
- - 사용자가 DML을 수행할 경우 Undo Data들을 저장해 두는 특별한 Tablespace
- - 서버 프로세스가 Undo Tablespace에 Undo Segment를 생성해, 각 사용자별로 Undo Segment를 할당에서 Undo Data를 관리
- - Instance 별로 적어도 하나 이상의 Undo Tablespace가 있어야함 (RAC 2노드면 각각 Undo Tablespace 존재)
- Undo Segment
- Undo Segment Header 구조
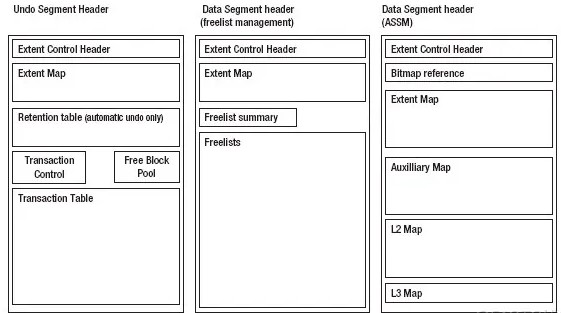
- Undo Segment
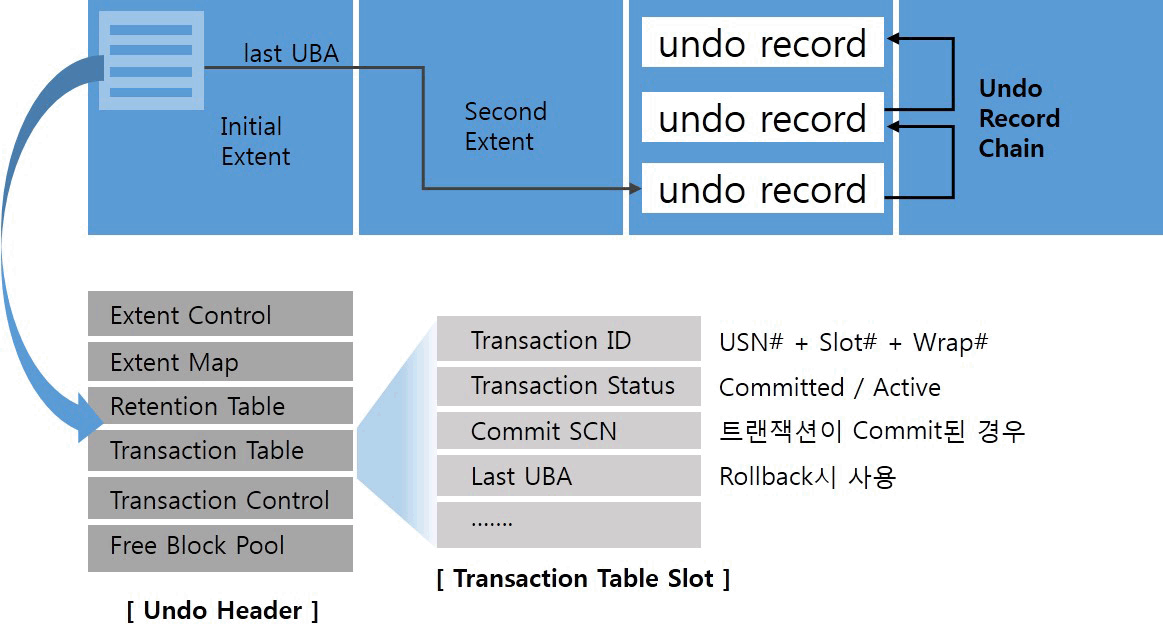
- - Undo Data를 저장하고 있는 테이블
- - 종류: System, Non-System, Deferred(만들수없음, 알아서 생성됨, 작업후 자동 삭제)
- Undo 블럭 과 테이블 블럭 구조 비교
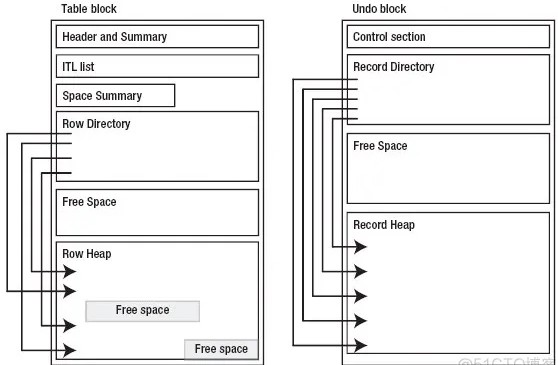
2.1 목적[편집]
2.1.1 Transaction Rollback[편집]
- 특정 작업을 수행한 후 커밋을 수행하지 않은 작업에 롤백을 수행하게 되면 작업 수행 전의 데이터로 복구되는 기능
2.1.2 읽기 일관성(Read Consistency) 유지[편집]
- Transaction이 진행되는 동안 다른 사용자는 이 Consistent Read에 의해 Commit되지 않은 변경 사항을 볼 수 없는 기능( A-> B 값 변경시 COMMIT 하기 전까지 다른 세션에서 변경 전인 A로 조회 됨)
2.1.3 Transaction Recovery[편집]
- Transaction이 진행되는 동안 Instance가 실패한 경우 Database가 다시 열릴 때 Commit 되지 않은 사항은 Rollback 되어야 하는데 이때 Undo Segment 정보가 사용됨
2.3 Undo Segment 조회[편집]
attach_file - 주의사항
- Undo 테이블스페이스 의 특징 - "Undo Data File의 크기는 증가만 가능 하고 , 줄일 수는 없다"
- 서버 프로세스가 Undo Segment를 확보하려고 할 때 무조건 신규 Undo Segment를 할당 받는 것이 아니라
- 기존에 만들어져 있던 Undo Segment 중 트랜잭션이 완료된 것(commit이나 rollback된 트랜잭션)이 있는지 확인 후
- 트랜잭션이 완료된 Undo Segment가 있으면 그 Undo Segment를 덮어쓰게 됨.
- 하지만 트랜잭션이 완료된 Undo Segment가 없을 경우 새로운 Undo Segment를 생성해서 기록하게 된다.
- 이런식으로 계속 늘어나게 되는 것임
- commit을 수행해도 해당 Undo Segment 안에 있는 Undo Data는 delete 되는것이 아니라 남아있기 때문에 다시 줄일 수 없는 것.
select segment_name, tablespace_name, status
from dba_rollback_segs;
2.4 UNDO 테이블스페이스[편집]
2.4.1 RAC 에서의 UNDO 테이블 스페이스[편집]
- RAC 시스템의 각 인스턴스는 한 서버에 하나의 UNDO 테이블스페이스 만 사용할 수 있음.
- 즉, 인스턴스는 UNDO 테이블스페이스를 공유 할 수 없음.
- 자동 실행 취소 관리 또는 롤백 세그먼트 실행 취소를 사용하여 실행 취소 공간을 관리 할 수 있음.
- 자동 롤백 방법을 사용할 경우 서버 매개 변수 파일에서 전역 매개 변수 undo_management를 auto로 설정하고 undo_tablespace 매개 변수를 설정하여 인스턴스에 실행 취소 테이블 스페이스를 할당 함.
- 인스턴스가 시작되면 사용 가능한 첫 번째 UNDO 테이블스페이스를 사용 함.
- 두 번째 인스턴스는 두번째 UNDO 테이블스페이스를 사용함.
- 따라서 RAC 시스템의 각 인스턴스는 주어진 시간에 특정 UNDO 테이블스페이스에 배타적으로 액세스 할 수 있음.
2.6 Undo Tablespace 줄이기[편집]
attach_file - 언두 테이블스페이스 줄이는 방법
- 새로운 작은 크기의 Undo Tablespace를 신규로 만들고,
- 쓰고 있던 Undo Tablespace를 새로운 Undo Tablespace로 변경 한 후
- 기존의 Undo Tablespace를 삭제해 주면 된다.
2.7 Undo Tablespace 확장[편집]
- 확장
alter database datafile 'filename' resize 20M;* 추가할때는 tablespace 단위, 확장시에는 database 단위
2.8 UNDO Tablespace 삭제[편집]
drop tablespace [언두 T/S명] including contents and datafiles;
여기서 drop이 안될때는 누군가가 DML을 하고 commit이나 rollback을 안하고 있음.
2.9 UNDO Tablespace 사용하고 있는 세션 찾기[편집]
2.9.1 현재 사용중인 세그먼트[편집]
select segment_name, tablespace_name, status
from dba_rollback_segs
where status='ONLINE' order by 2;2.9.2 현재 사용중인 세션 조회[편집]
찾아서 kill 후 UNDO T/S drop 처리
SELECT TO_CHAR (s.sid) || ',' || TO_CHAR (s.serial#) sid_serial,
NVL (s.username, 'None') orauser,
s.program, s.osuser, s.machine, s.terminal,RS.TABLESPACE_NAME,
r.name undoseg,
t.used_ublk * TO_NUMBER (x.VALUE) /1024 || 'K' "Undo",t.start_time
FROM sys.v_$rollname r,
sys.v_$session s,
sys.v_$transaction t,
sys.v_$parameter x,
sys.dba_rollback_segs rs
WHERE s.taddr = t.addr
AND r.usn = t.xidusn(+)
AND x.name = 'db_block_size'
AND rs.segment_name = r.name;
-- and r.name = '원하는 세그먼트 이름'
-- and ts.tablespace_name='언두이름'
;2.10 undo_retention 파라메터[편집]
- 언두 리텐션이란 지정된 수치(오라클 9i까지는 UNDO_RETENTION 파라미터의 설정 값) 동안은 트랜잭션이 종료된 후에라도,트랜잭션과 관련되었던 언두 세그먼트를 재사용하지 못하도록 하는 기능이다.
- 파라메터의 본래 의미는 commit 된 정보에 대해서도 undo 이미지를 유지하기 위한 시간.
- Oracle Database 10g부터는 긴 쿼리를 수행하는 경우 ORA-1555 에러(snapshot too old)의 빈도를 줄이기 위해서 undo_retention 파라미터를 자동으로 할당하는 기능을 제공.
- *12c 경우 ,
- undo_management = auto => rollback segment를 자동관리함
- undo table space 는 autoextend on
- undo_retention = 900
- Undo Table space의 여유가 있다면 더 오랜시간동안 Undo를 보관하기 때문에 Undo Table space의 사용율은 지속적으로 증가할수 있으며,
- UNDO_RETENTION 파라미터는 현재 Undo 테이블스페이스에UNDO_RETENTION 기간 동안 발생하는 모든 트랜잭션을 수용할 수 있을 만큼 충분한 커야한다.
- 하지만 Undo-Table Space가 더이상 확장을 할수 없다면 Default 설정인 노개런티 모드에 의해 시간이 초과하지 않은 Unexpire undo 또한 사용될수 있다.
- 이런식으로 Undo table space가 확장되지 않고 Unexpired undo를 다 소진하고도 부족할 경우,ORA-30036(unable to extend segment by # in undo tablespace XXXX) 발생한다
- ora-1555 나 dml 에러 발생 시
- undo_management = auto
- tbs auto exetend on
- tbs maxsize를 늘려주거나 , 가용공간이 없드면 dml을 분산하여 수행,dml시 오래토록 수행해야하는 쿼리 지양
- 12c 에서 temp_undo_enabled를 true로 설정하여,temporary 테이블 관련 undo를 temp t/s 에서 수행 하여 undo/redo 부하를 줄일수 있음.
2.11 undo extent 할당 순서[편집]
attach_file Extent stealing
- 자기 자신의 Extent의 프리 블록을 찾는다.
- 다음 Extent가 만료된 Extent인지 확인한다.
- 언두 테이블스페이스에서 새로운 Extent를 할당한다.
- 오프라인 트랜잭션 테이블에서 expired Extent를 가져온다(steal).
- 온라인 트랜잭션 테이블에서 expired Extent를 가져온다(steal).
- autoextend가 가능하다면 파일을 확장하여 Extent를 할당한다.
- 자신의 트랜잭션 테이블에서 unexpired Extent를 재사용한다.
- 오프라인 트랜잭션 테이블에서 unexpired Extent를 가져온다(steal).
- 에러(ORA-30036)를 발생한다.
- expired extent : undo_retention 시간을 초과한 Extent.사용 중인 트랜잭션이 없고 undo retention 도 완료되어서 언제든지 트랜잭션에 할당될 수 있는 상태
- unexpired extent : undo_retention 시간을 초과하지 않은 Extent. 사용 중인 트랜잭션이 없으나, 언두 유지 시간이 완료되지 않아서 트랜잭션에 할당되지 않고 보존되어 있는 상태
- active extent :트랜잭션에 할당되어 언두 데이터를 기록하고 있는 상태
- free extent : 생성 이후 트랜잭션에 한 번도 할당되지 않았거나, SMON에 의한 주기적 정리가 완료되어 있는 상태
각각의 언두 Extent의 Expired, Unexpired 상태는 dba_undo_extents에서 확인할 수 있다.
3 UNDO 테이블스페이스 상태 조회[편집]
sd_storage
딕셔너리
-- 개런티 모드 확인 : UNEXPIRED 상태의 공간을 더 사용 할수 있도록 허용함.즉, 자동 리텐션을 보장하지 않음.
SELECT TABLESPACE_NAME
, RETENTION
FROM DBA_TABLESPACES
WHERE TABLESPACE_NAME = 'UNDOTBS1';3.1 현재 운영중인 DB UNDO 사용량 조회[편집]
3.1.1 Undo 테이블 사용 현황(퍼센트) 조회[편집]
- DBA_UNDO_EXTENTS
- DBA_DATA_FILES
SELECT A.TABLESPACE_NAME,A.STATUS, B.TOTAL_MB, A.USE_MB,
ROUND(RATIO_TO_REPORT(A.USE_MB) OVER(PARTITION BY A.TABLESPACE_NAME) * 100)||'%' AS PCT
FROM (SELECT TABLESPACE_NAME, STATUS,
ROUND(SUM(BYTES/1024/1024)) USE_MB
FROM DBA_UNDO_EXTENTS
GROUP BY TABLESPACE_NAME,STATUS
)A,
(SELECT TABLESPACE_NAME, ROUND(SUM(BYTES)/1024/1024) TOTAL_MB
FROM DBA_DATA_FILES
WHERE TABLESPACE_NAME LIKE 'UNDO%'
GROUP BY TABLESPACE_NAME
)B
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME
ORDER BY 1,23.1.2 사용중인 사이즈 와 재활용 가능한 사이즈[편집]
WITH FREE_SZ AS (SELECT TABLESPACE_NAME
, SUM(F.BYTES)/1048576/1024 FREE_GB
FROM DBA_FREE_SPACE F
GROUP BY TABLESPACE_NAME ),
------
A AS (SELECT TABLESPACE_NAME
, SUM( CASE WHEN STATUS = 'EXPIRED' THEN BLOCKS END)*8/1048576 REUSABLE_SPACE_GB -- 재사용 가능한 공간
, SUM(CASE WHEN STATUS IN ('ACTIVE','UNEXPIRED') THEN BLOCKS END)*8/1048576 ALLOCATED_GB -- 할당되어 사용중인 공간
FROM DBA_UNDO_EXTENTS
WHERE STATUS IN ('ACTIVE','EXPIRED','UNEXPIRED')
GROUP BY TABLESPACE_NAME ) ,
------
UNDO_SZ AS (SELECT TABLESPACE_NAME,
DF.USER_BYTES/1048576/1024 USER_SZ_GB
FROM DBA_TABLESPACES TS JOIN DBA_DATA_FILES DF USING (TABLESPACE_NAME)
WHERE TS.CONTENTS = 'UNDO'
AND TS.STATUS = 'ONLINE' )
------
SELECT TABLESPACE_NAME,
ROUND(USER_SZ_GB,1) AS USER_SZ_GB,
ROUND(FREE_GB,1) AS FREE_GB,
ROUND(REUSABLE_SPACE_GB,1) AS REUSABLE_SPACE_GB,
ROUND(ALLOCATED_GB,1) AS ALLOCATED_GB ,
ROUND(FREE_GB + REUSABLE_SPACE_GB + ALLOCATED_GB,1) AS TOTAL
FROM UNDO_SZ
JOIN FREE_SZ USING (TABLESPACE_NAME)
JOIN A USING (TABLESPACE_NAME);
- 활성 상태가 아닌 Expired Extent 및 Unexpired Extent가 많이 남아 있다면, 언두 테이블스페이스의 여유 공간이 얼마 남아 있지 않더라도 트랜잭션에 별 영향을 주지 않음
- 하지만, ORA-1555 에러 발생의 우려가 있기 때문에 v$undostat의 tuned_undoretention 값을 참조하여 적정한 언두 테이블스페이스 크기를 조정해 주는 것이 좋다.
- (ORA-1555 :사용자가 필요로 하는 롤백 세그먼트의 정보가 다른 트랜잭션에 의해 overwrite되어, 존재하지 않을 때 발생)
3.2 Automatic Undo Retention[편집]
- 초기 파라미터에 정의 한 UNDO_RETENTION(초)은 트랜잭션이 진행하는 동안 일정량의 UNDO 정보를 유지할 수 있도록 함으로써 Long-running query시 발생 할 수 있는 ORA-1555(snapshot too old) 오류를 만날 가능성을 줄여주었다.
- 10g 부터 Oracle 이 자동 관리 방식으로 변경됨
- 자동 언두 리텐션 기능의 동작 방식은 오라클 10gR1과 오라클 10gR2간에도 차이가 나며,언두 테이블스페이스의 “undo guarantee" 사용 여부와 언두 데이터 파일의 “autoextend" 사용 여부에 따라 다르게 동작한다.
- Retention Gurantee = YES 의 경우
- Undo 공간부족으로 인해 트랜잭션이 commit된 정보에 덮어쓰는 작업을 막아 Undo Retention의 설정값 만큼 보장.
- => 언두 테이블스페이스의 공간 부족 현상이 발생할 경우에도, UNEXPIRED된 언두 익스텐트를 재사용하는 것을 방지함으로써, 언두 리텐션을 보장하는 것.
- Retention Gurantee = NO 의 경우
- Undo 공간 부족으로 인해 트랜잭션이 실패 하도록 하기보다는 커밋된 Undo 정보를 덮어쓴다.
- => TUNED_UNDORETENTION 값은 장시간의 쿼리를 감지한 직후에는 대략 MAXQUERYLEN + 300초로 증가한다.
- Retention Gurantee = YES 의 경우
autoextend 모드라면,언두 테이블스페이스가 확장 가능하므로, 쿼리의 수행시간에 근거하여 언두 리텐션을 튜닝한다.
- Prerequisite
undo_management = auto
undo_retention = 0 (10g: 이 파라미터 값을 0으로 해야 자동 활성화됨)3.2.1 Automatic Undo Retention 튜닝 방법[편집]
- UNDO_RETENTION을 0으로 셋팅하면 UNDO_RETENTION의 최소값은 900초(15분)가 된다.
- MMON process가 매 30초마다 query duration을 계산하며, MAXQUERYLEN(데이터 수집 구간 중 가장 오래 수행된 SQL의 수행시간) 이라는 값을 계산하는데 이 값에 따라서 MMON은 TUNED_UNDORETENTION 이라는 수치를 결정한다.
- 이때 UNDO RETENTION 값이 TUNED_UNDORETENTION 로 셋팅이 된다.
select tuned_undoretention, maxquerylen, maxqueryid from v$undostat;- MAXQUERYLEN : 데이터 수집 구간 중 가장 오래 수행된 SQL의 수행시간(단위: 초)
- TUNED_UNDORETENTION : 오라클이 인스턴스에서 최적으로 설정한 언두 유지 시간
- 이와 같은 Automatic Undo Retention의 튜닝으로 ORA-1555 ERROR 예방이 가능하게 된다.
- 그러나, undo tablespace가 autoextend off 이면 DML 수행 시 UNDO SPACE 부족현상이 발생할 수 있으므로 충분한 Undo tablespace 공간이 확보되어야 한다.
3.3 현재 사용중인 세션 과 블럭[편집]
- V$SESS_IO 와 V$SESSION 를 조인
- V$SESS_IO 의 BLOCK_CHANGES 라는 컬럼은 얼마나 많은 block들이 그 session에 의해서 변화되었는지를 보여준다.
- 이 값이 높으면 session이 많은 양의 redo를 생성시켰음을 알 수 있다.
3.3.1 많은 양의 redo를 발생한 세션,사용자,program을 확인 하는 쿼리[편집]
SELECT s.sid
, s.serial#
, s.username
, s.program
, i.block_changes
FROM v$session s
, v$sess_io i
WHERE s.sid = i.sid
ORDER BY 5 desc, 1, 2, 3, 4;
- V$TRANSACTION 뷰를 조회하면 해당 transaction에 의하여 액세스된 undo block과 undo record들의 양에 대한 정보를 알 수 있다.
- USED_UBLK 컬럼과 USED_UREC 컬럼을 보고 알 수 있다.
3.3.2 많은 양의 redo를 생성한 특정 transaction을 찾을 때 조회하는 쿼리[편집]
SELECT s.sid
, s.serial#
, s.username
, s.program
, t.used_ublk
, t.used_urec
, s.module
, s.action
, S.SQL_ID
FROM v$session s
, v$transaction t
WHERE s.taddr = t.addr
-- AND SQL_ID ='7u69zymppwnss'
ORDER BY 5 desc, 6 desc, 1, 2, 3, 4;- USED_UBLK 컬럼과 USED_UREC 컬럼의 각 발생 사이의 delta 값을 비교 하여 그 값이 클 수록 그 session이 많은 양의 redo를 생성 하였다고 판단.
4 REDO ?[편집]

- 리두 로그 버퍼는 데이터베이스에서 일어난 모든 변화를 저장하는 메모리 공간
- 리두 로그 버퍼에 저장된 리두 항목들은 LGWR에 의해 데이터베이스 복구에 사용되는 온라인 리두 로그 파일에 저장
- LOG_BUFFER 파라미터로 Redo Log Buffer의 크기를 결정
- 리두 정보는 항상 실제 변경작업보다 먼저 보관되어야 어떤 상황에서도 복구가 가능해집니다.
- 트랜잭션을 수행하는(데이터베이스 블록에 변경을 가하는) 프로세스는 우선 자신의 메모리 영역 내에서 수행하고자 하는 작업에 대한 리두 레코드를 생성
- 이를 먼저 로그버퍼에 기록하고 난 후에 실제 버퍼블록에도 리두 레코드에 담긴 내용을 따라 적용하게 됩니다.
- 오라클은 변경된 버퍼 캐쉬 블록을 디스크에 기록하기 전에 먼저 관련된 로그버퍼를 로그파일에 기록하는 작업을 처리
4.1 REDO LOG[편집]
- 오라클은 'Data Files'과 'Control File'에 가해지는 모든 변경사항을 하나의 Redo Log에 기록함.
- Redo Log는 'Online Redo Log'와 'Offline Redo Log(Archived)'로 구성된다.
4.1.1 Online Redo Log[편집]
- :Redo Log Buffer에 버퍼링된 로그 엔트리를 기록하는 파일로, 최소 두 개 이상의 파일로 구성
- 현재 사용장인 Redo Log File이 꽉 차면 다음 Redo Log File로 Log Switching을 하고 모든 Redo Log File이 꽉 차면 다시 첫 번째 Redo Log File부터 재사용되는 'Round-Roin' 방식 사용
4.1.3 리두로그 파일 사이징[편집]
- 데이터베이스 writer 및 archiver 프로세스의 동작은 리두 로그 크기에 따라 달라지므로 리두 로그 파일의 크기는 성능에 영향을 미칠 수 있습니다.
- 일반적으로 리두 로그 파일이 클수록 성능이 더 좋습니다. 크기가 작은 로그 파일은 체크포인트 활동을 증가시키고 성능을 저하시킵니다.
- 리두 로그 파일의 크기는 LGWR 성능에 영향을 미치지 않지만 DBWR 및 체크포인트 동작에 영향을 줄 수 있습니다.
- 체크포인트 빈도는 로그 파일 크기, FAST_START_MTTR_TARGET 초기화 매개변수 설정 등 여러 요소의 영향을 받습니다.
- FAST_START_MTTR_TARGET 매개변수가 인스턴스 복구 시간을 제한하도록 설정된 경우 Oracle은 자동으로 필요한 만큼 자주 체크포인트를 시도합니다.
- 이 조건에서는 로그 파일 크기가 부족하여 로그 파일이 추가로 검사되는 것을 방지할 수 있을 만큼 충분히 커야 합니다.
- 최적의 크기는 V$INSTANCE_RECOVERY 뷰에서 OPTIMAL_LOGFILE_SIZE 컬럼을 쿼리하여 얻을 수 있습니다.
- Oracle Enterprise Manager의 Redo Log Groups 페이지에서 크기 조정에 대한 조언을 얻을 수도 있습니다.
- 리두 로그 파일에 대한 특정 크기 권장 사항을 제공하는 것이 항상 가능하지는 않지만 수백 메가바이트에서 몇 기가바이트 범위의 리두 로그 파일이 합리적인 것으로 간주됩니다.
- 시스템이 생성하는 리두 양에 따라 온라인 리두 로그 파일의 크기를 조정합니다. 대략적인 지침은 최대 20분마다 한 번씩 로그를 전환하는 것입니다.
The size of the redo log files can influence performance, because the behavior of the database writer and archiver processes depend on the redo log sizes. Generally, larger redo log files provide better performance. Undersized log files increase checkpoint activity and reduce performance.
Although the size of the redo log files does not affect LGWR performance, it can affect DBWR and checkpoint behavior. Checkpoint frequency is affected by several factors, including log file size and the setting of the FAST_START_MTTR_TARGET initialization parameter. If the FAST_START_MTTR_TARGET parameter is set to limit the instance recovery time, Oracle automatically tries to checkpoint as frequently as necessary. Under this condition, the size of the log files should be large enough to avoid additional checkpointing due to under sized log files. The optimal size can be obtained by querying the OPTIMAL_LOGFILE_SIZE column from the V$INSTANCE_RECOVERY view. You can also obtain sizing advice on the Redo Log Groups page of Oracle Enterprise Manager.
It may not always be possible to provide a specific size recommendation for redo log files, but redo log files in the range of a hundred megabytes to a few gigabytes are considered reasonable. Size your online redo log files according to the amount of redo your system generates. A rough guide is to switch logs at most once every twenty minutes.