"Oracle DBA 명령어"의 두 판 사이의 차이
DB CAFE
(→산술 명령어) |
(→예시s) |
||
| (사용자 2명의 중간 판 57개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
= 오라클 DBA 작업 명령어 = | = 오라클 DBA 작업 명령어 = | ||
| − | + | {{:오라클 시퀀스}} | |
| − | + | ---- | |
| − | + | {{:오라클 시노님}} | |
| − | + | ---- | |
| − | + | ==테이블 작업== | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | ==테이블== | ||
=== INSERT === | === INSERT === | ||
INSERT 문 | INSERT 문 | ||
| 66번째 줄: | 11번째 줄: | ||
https://docs.oracle.com/database/121/SQLRF/img/single_table_insert.gif | https://docs.oracle.com/database/121/SQLRF/img/single_table_insert.gif | ||
| − | + | ==== INSERT ~ VALUES ==== | |
<source lang=plsql> | <source lang=plsql> | ||
| − | + | -- 컬럼 생략 | |
| + | INSERT INTO table_name VALUES ('Value1', 'Value2', ... ); | ||
| − | + | INSERT INTO table_name( Column1, Column2, ... ) | |
VALUES ( 'Value1', 'Value2', ... ); | VALUES ( 'Value1', 'Value2', ... ); | ||
</source> | </source> | ||
| − | + | ==== INSERT ~ SELECT ==== | |
<source lang=plsql> | <source lang=plsql> | ||
INSERT INTO table_name( SELECT Value1, Value2, ... from table_name ); | INSERT INTO table_name( SELECT Value1, Value2, ... from table_name ); | ||
| − | + | -- | |
| − | + | INSERT INTO table_name | |
( Column1, Column2, ... ) | ( Column1, Column2, ... ) | ||
( SELECT Value1, Value2, ... from table_name ); | ( SELECT Value1, Value2, ... from table_name ); | ||
| + | </source> | ||
| + | |||
| + | ==== INSERT ALL INTO ~ VALUES ==== | ||
| + | * 조건에 따라서 여러개의 테이블에 INSERT 할 경우 사용 | ||
| + | <source lang=plsql> | ||
| + | INSERT ALL | ||
| + | WHEN sal >= 3000 THEN | ||
| + | INTO emp_sal1 VALUES (empno, name, sal) | ||
| + | WHEN sal >= 2000 THEN | ||
| + | INTO emp_sal2 VALUES (empno, name, sal) | ||
| + | ELSE | ||
| + | INTO emp_sal3 VALUES (empno, name, sal) | ||
| + | SELECT a.empno | ||
| + | , a.name | ||
| + | , a.sal | ||
| + | FROM emp a | ||
| + | WHERE a.empno = 11 | ||
| + | </source> | ||
| + | |||
| + | ==== INSERT FIRST ==== | ||
| + | * 조건에 만족하는 첫 번째 WHEN~THEN의 테이블에만 INSERT | ||
| + | <source lang=plsql> | ||
| + | INSERT FIRST | ||
| + | WHEN sal >= 3000 THEN | ||
| + | INTO table1 VALUES (empno, ename, sal) | ||
| + | WHEN sal >= 2000 THEN | ||
| + | INTO table2 VALUES (empno, ename, sal) | ||
| + | ELSE | ||
| + | INTO table3 VALUES (empno, ename, sal) | ||
| + | SELECT a.empno | ||
| + | , a.ename | ||
| + | , a.sal | ||
| + | FROM emp a | ||
| + | WHERE a.empno = 7788 | ||
</source> | </source> | ||
| 96번째 줄: | 76번째 줄: | ||
; | ; | ||
</source> | </source> | ||
| + | {{:SQL MERGE|MERGE INTO}} | ||
---- | ---- | ||
| − | + | {{:오라클 테이블 생성}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
=== ALTER TABLE === | === ALTER TABLE === | ||
https://docs.oracle.com/database/121/SQLRF/img/alter_table.gif | https://docs.oracle.com/database/121/SQLRF/img/alter_table.gif | ||
| − | + | {{:오라클 컬럼 추가 삭제 변경}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
====Constraints 제약조건 ==== | ====Constraints 제약조건 ==== | ||
| 188번째 줄: | 121번째 줄: | ||
|} | |} | ||
| − | =====constraints | + | ===== 제약조건(constraints) 조회===== |
| − | ''' | + | ''' 모든 제약 조건 조회 뷰:''' |
<source lang=sql> | <source lang=sql> | ||
| − | SELECT | + | SELECT table_name, |
| − | |||
constraint_name, | constraint_name, | ||
constraint_type | constraint_type | ||
| − | FROM | + | FROM dba_constraints; |
</source> | </source> | ||
| − | =====FK | + | =====FK (외래키) 제약조건 ===== |
| − | ''' | + | ''' 모든 외래키 제약 조건 원본과 참조 테이블/컬럼 조회 :''' |
<source lang=sql> | <source lang=sql> | ||
SELECT c_list.CONSTRAINT_NAME as NAME, | SELECT c_list.CONSTRAINT_NAME as NAME, | ||
| 219번째 줄: | 151번째 줄: | ||
</source> | </source> | ||
| − | ==== | + | ==== 테이블 제약 조건 설정 ==== |
| − | ''' | + | ''' 테이블 생성시 제약 조건 추가 :''' |
<source lang=sql> | <source lang=sql> | ||
CREATE TABLE table_name | CREATE TABLE table_name | ||
| 229번째 줄: | 161번째 줄: | ||
CONSTRAINT constraint_name CHECK (column_name condition) [DISABLE] | CONSTRAINT constraint_name CHECK (column_name condition) [DISABLE] | ||
); | ); | ||
| + | </source> | ||
| − | ''' | + | '''예시:''' |
| − | + | <source lang=sql> | |
CREATE TABLE suppliers | CREATE TABLE suppliers | ||
( | ( | ||
| 241번째 줄: | 174번째 줄: | ||
</source> | </source> | ||
| − | ====Unique | + | ==== Unique 인덱스 추가 ==== |
| − | ''' | + | '''테이블 생성시 Unique 인덱스 추가 :''' |
<source lang="sql"> | <source lang="sql"> | ||
| 265번째 줄: | 198번째 줄: | ||
</source> | </source> | ||
| − | ==== | + | ==== Unique 제약 조건 추가 ==== |
| − | |||
| − | |||
<source lang="sql"> | <source lang="sql"> | ||
| 273번째 줄: | 204번째 줄: | ||
ADD CONSTRAINT [constraint name] UNIQUE( [column name] ) USING INDEX [index name]; | ADD CONSTRAINT [constraint name] UNIQUE( [column name] ) USING INDEX [index name]; | ||
</source> | </source> | ||
| − | ''' | + | |
| + | ''' 예시:''' | ||
<source lang="sql"> | <source lang="sql"> | ||
| 280번째 줄: | 212번째 줄: | ||
</source> | </source> | ||
| − | ==== | + | ==== 제약조건 삭제 ==== |
| − | + | <ref>http://www.psoug.org/reference/constraints.html</ref> | |
<source lang="sql"> | <source lang="sql"> | ||
| 294번째 줄: | 226번째 줄: | ||
</source> | </source> | ||
| − | == | + | ==인덱스== |
| − | + | 기본적으로 Oracle은 B-tree 인덱스를 만듭니다. | |
| − | === | + | ===인덱스 생성=== |
https://docs.oracle.com/database/121/SQLRF/img/create_index.gif | https://docs.oracle.com/database/121/SQLRF/img/create_index.gif | ||
| 334번째 줄: | 266번째 줄: | ||
</source> | </source> | ||
| − | === | + | === 함수 인덱스 생성=== |
In Oracle, you are not restricted to creating indexes on only columns. You can create function-based indexes. | In Oracle, you are not restricted to creating indexes on only columns. You can create function-based indexes. | ||
| 360번째 줄: | 292번째 줄: | ||
ORDER BY UPPER(customer_name); | ORDER BY UPPER(customer_name); | ||
</source> | </source> | ||
| − | |||
| − | + | ===인덱스명 변경=== | |
<source lang="sql"> | <source lang="sql"> | ||
| 374번째 줄: | 305번째 줄: | ||
RENAME TO new_customer_id; | RENAME TO new_customer_id; | ||
</source> | </source> | ||
| − | + | 예시, '''customer_id''' renamed to '''new_customer_id'''. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | ===인덱스 통계 정보 수집=== | ||
| + | {{틀:고지상자 | ||
| + | |제목= 인덱스 통계 정보 수집 | ||
| + | |내용= | ||
| + | # 인덱스가 처음 작성된 후 통계를 수집해야하거나 통계를 업데이트하려는 경우 | ||
| + | #: 항상 '''ALTER INDEX' ''명령을 사용하여 통계를 수집 할 수 있습니다. | ||
| + | # 오라클이 효과적인 방식으로 인덱스를 사용할 수 있도록 통계를 수집합니다. | ||
| + | #:오라클이 실행 계획을 선택하는 동안 데이터를 효과적으로 사용할 수 있도록 | ||
| + | #: 테이블 크기, 행 수, 블록, 세그먼트를 다시 계산하고 사전 테이블을 업데이트합니다. | ||
| + | }} | ||
'''인덱스에서 통계를 수집하는 구문은 다음과 같습니다.''' | '''인덱스에서 통계를 수집하는 구문은 다음과 같습니다.''' | ||
| 398번째 줄: | 331번째 줄: | ||
예시, '''customer_idx'''라는 인덱스에 대한 통계가 수집됩니다. | 예시, '''customer_idx'''라는 인덱스에 대한 통계가 수집됩니다. | ||
| − | === | + | ===인덱스 삭제=== |
| − | |||
| − | |||
<source lang="sql"> | <source lang="sql"> | ||
DROP INDEX index_name; | DROP INDEX index_name; | ||
</source> | </source> | ||
| − | + | {{:ORACLE 사용자 롤 생성 삭제 관리|롤 생성/권한부여/관리}} | |
| − | + | ---- | |
| − | |||
| − | |||
| − | |||
| − | |||
{{:ORACLE_테이블스페이스}} | {{:ORACLE_테이블스페이스}} | ||
| 420번째 줄: | 347번째 줄: | ||
====산술 명령어==== | ====산술 명령어==== | ||
{{틀:타이틀 투명 | {{틀:타이틀 투명 | ||
| − | |제목=* 더하기: + | + | |제목= |
| + | * 더하기: + | ||
* 빼기: - | * 빼기: - | ||
* 곱하기: * | * 곱하기: * | ||
* 나누기: / | * 나누기: / | ||
* Power (PL/SQL only): ** | * Power (PL/SQL only): ** | ||
| + | |아이콘=error | ||
}} | }} | ||
| − | ===== | + | =====예시===== |
<source lang="sql"> | <source lang="sql"> | ||
UPDATE employee SET salary = salary * 1.05 | UPDATE employee SET salary = salary * 1.05 | ||
| 539번째 줄: | 468번째 줄: | ||
* 컬렉션, 동등성을위한 컬렉션 비교 및 중첩 테이블에 대한 집합 연산 지원 등을 포함하도록 개선되었습니다. | * 컬렉션, 동등성을위한 컬렉션 비교 및 중첩 테이블에 대한 집합 연산 지원 등을 포함하도록 개선되었습니다. | ||
| + | |||
| + | ==== 묵시적 커서 와 커서 속성 ==== | ||
| + | |||
| + | INSERT, UPDATE, DELETE문을 수행했을 때 몇 건의 데이터가 영향을 받았는지, 즉 몇 건의 데이터가 새로 입력되고 갱신되고 삭제되었는지 알 수 있다. | ||
| + | |||
| + | 예를 들어, 사원 테이블에서 80번 부서에 속한 사원은 총 34명인데, 이를 UPDATE 하는 경우 | ||
| + | |||
| + | <source lang=sql> | ||
| + | DECLARE | ||
| + | vn_department_id employees.department_id%TYPE := 80; | ||
| + | BEGIN | ||
| + | -- 80번 부서의 사원이름을 자신의 이름으로 갱신 | ||
| + | UPDATE employees | ||
| + | SET emp_name = emp_name | ||
| + | WHERE department_id = vn_department_id; | ||
| + | |||
| + | -- 몇 건의 데이터가 갱신됐는지 출력 | ||
| + | DBMS_OUTPUT.PUT_LINE(SQL%ROWCOUNT); | ||
| + | |||
| + | COMMIT; | ||
| + | END; | ||
| + | |||
| + | -- 결과 : 34 | ||
| + | </source> | ||
| + | |||
| + | 정확히 34건이 갱신됐음을 알 수 있다. | ||
| + | |||
| + | SQL%ROWCOUNT 커서 속성을 사용해서 해당 SQL문으로 인해 실제 처리된 결과 로우 수를 참조한 것. | ||
| + | SQL%ROWCOUNT에서 %ROWCOUNT가 커서 속성이며 앞에 붙은 SQL은 커서 이름. | ||
| + | 묵시적 커서의 정보를 참조할 때는 SQL로 시작되는 속성명을 사용해 참조할 수 있어 묵시적 커서를 SQL 커서라고도 한다. | ||
| + | |||
| + | * 묵시적 커서 정보 참조용 커서 속성 | ||
| + | |||
| + | SQL%FOUND 결과 집합의 패치 로우 수가 1개 이상이면 TRUE, 아니면 FALSE를 반환 | ||
| + | SQL%NOTFOUND 결과 집합의 패치 로우 수가 0이면 TRUE, 아니면 FALSE를 반환 | ||
| + | SQL%ROWCOUNT 영향 받은 결과 집합의 로우 수 반환, 없으면 0을 반환 | ||
| + | SQL%ISOPEN 묵시적 커서는 항상 FALSE를 반환(이 속성으로 참조할 때는 이미 해당 묵시적 커서는 닫힌 상태 이후이기 때문) | ||
== 참고 레퍼런스 == | == 참고 레퍼런스 == | ||
| 888번째 줄: | 854번째 줄: | ||
16-JUL-69 | 16-JUL-69 | ||
</source> | </source> | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
== 참조 == | == 참조 == | ||
| − | |||
* http://www.psoug.org/reference/ | * http://www.psoug.org/reference/ | ||
| − | |||
[[Category:oracle]] | [[Category:oracle]] | ||
2024년 7월 12일 (금) 15:48 기준 최신판
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
- 1 오라클 DBA 작업 명령어
- 1.1 시퀀스
- 1.2 시노님 SYNONYM
- 1.3 테이블 작업
- 1.4 인덱스
- 1.5 롤 생성 삭제 관리
- 1.6 롤 조회 딕셔너리 뷰
- 1.7 테이블 스페이스 (TABLESPACE)
- 1.7.1 TABLESPACE 목록 조회
- 1.7.2 TABLESPACE 종류
- 1.7.3 현재 유저의 DEFAULT TABLESPACE 확인
- 1.7.4 TABLESPACE 생성 구문
- 1.7.5 UNDO TABLESPACE 생성
- 1.7.6 TABLESPACE 변경
- 1.7.7 테이블의 TABLESPACE MOVE
- 1.7.8 운영중인 테이블 TABLESPACE ONLINE MOVE
- 1.7.9 TABLESPACE 사이즈 변경(RESIZE)
- 1.7.10 TABLESPACE 이름 변경
- 1.7.11 인덱스의 TABLESPACE 변경
- 1.7.12 인덱스의 TABLESPACE 변경 스크립트
- 1.7.13 인덱스/테이블 TABLESPACE 변경 스크립트
- 1.7.14 TABLESPACE 자동증가/최대 사이즈 변경
- 1.7.15 데이터파일 사이즈 변경
- 1.7.16 데이터파일 추가
- 1.7.17 데이터/템프파일 삭제
- 1.7.18 데이터 파일 삭제 후 OS 디스크 사이즈가 줄지 않을경우
- 1.7.19 TABLESPACE 삭제
- 1.7.20 TABLESPACE 수정이나 삭제시 ONLINE/OFFLINE 설정
- 1.7.21 템프 TABLESPACE
- 1.7.21.1 TEMPORARY TABLESPACE 정보
- 1.7.21.2 TEMPORARY TABLESPACE 생성
- 1.7.21.3 TEMPORARY TABLESPACE를 DEFAULT TABLESPACE로 변경
- 1.7.21.4 TEMPORARY TABLESPACE 사이즈 증가
- 1.7.21.5 TEMPORARY TABLESPACE 사이즈 추가
- 1.7.21.6 TEMPORARY TABLESPACE 삭제
- 1.7.21.7 TEMPORARY TABLESPACE DATA FILE 삭제
- 1.7.21.8 TEMPORARY TABLESPACE 사용율 조회 쿼리
- 1.7.21.9 템프테이블 TABLESPACE sort 사용 현황
- 1.8 TABLESPACE 오브젝트별 정보
- 1.9 UNDO TABLESPACE
- 1.10 TABLESPACE 장애 처리
- 1.11 LOB포함된 TABLESPACE 용량 축소/REORG
- 1.12 DATAPUMP 데이터펌프
- 1.13 IMPDP (Import Datapump) 사용법
- 1.13.1 IMPORT 사용 예시
- 1.13.2 DBLINK로 IMPORT PUMP 처리 방법
- 1.13.3 1.DB 링크 생성
- 1.13.4 2.IMPDP 파라미터 파일로 실행
- 1.13.5 IMPORT 파라미터 샘플
- 1.13.6 테이블만 IMPORT(테이블 존재시 TRUNCATE)
- 1.13.7 Package, Function, Procedure 만 import 하기
- 1.13.8 IMPORT DP 파라미터
- 1.13.9 통계정보를 제외
- 1.13.10 스키마 선택
- 1.13.11 IMPORT DP 상세 파라미터
- 1.13.12 IMPORT API
- 1.13.13 IMPORT 스키마/테이블 API
- 1.13.14 IMPORT 개별 TABLE (복구시)
- 1.14 EXPDP (Export Datapump) 사용법
- 1.15 데이터펌프 작업 관리 및 모니터링
- 1.16 데이터펌프(DATAPUMP) JOB 중지
- 1.17 EXPORT API
- 1.18 데이터펌프 로그파일 읽기 API
- 1.19 파일 복사(ASM등)
- 1.20 DATAPUMP API 상세 정보
- 1.21 DB LINK를 이용한 파일 복사
- 1.22 PL/SQL
- 1.23 기본 프로시져
- 1.24 프로시져 실행 옵션
- 1.25 커서 활용 샘플
- 1.26 참고 레퍼런스
- 1.27 참조
1 오라클 DBA 작업 명령어[편집]
1.1 시퀀스[편집]
 시퀀스 : 순차번호 생성
시퀀스 : 순차번호 생성
1.1.1 CREATE SEQUENCE[편집]
시퀀스 생성
CREATE SEQUENCE sequence_name
MINVALUE value
MAXVALUE value
START WITH value
INCREMENT BY value
CACHE value;예시:
CREATE SEQUENCE supplier_seq
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;1.1.2 ALTER SEQUENCE[편집]
시퀀스 수정:
ALTER SEQUENCE <sequence_name> INCREMENT BY <integer>;
ALTER SEQUENCE seq_inc_by_ten INCREMENT BY 10;시퀀스 최대값 변경:
ALTER SEQUENCE <sequence_name> MAXVALUE <integer>;
ALTER SEQUENCE seq_maxval MAXVALUE 10;시퀀스 순환/비순환 변경 :
ALTER SEQUENCE <sequence_name> <CYCLE | NOCYCLE>;
ALTER SEQUENCE seq_cycle NOCYCLE;시퀀스 캐시/비캐시 변경:
ALTER SEQUENCE <sequence_name> CACHE <integer> | NOCACHE;
ALTER SEQUENCE seq_cache NOCACHE;RAC에서 두서버간 정렬순 시퀀스 채번
ALTER SEQUENCE <sequence_name> <ORDER | NOORDER>;
ALTER SEQUENCE seq_order NOORDER;
ALTER SEQUENCE seq_order;1.2 시노님 SYNONYM[편집]
- 별명(ALIAS)
- 시노님(Synonym)은 테이블/뷰/프로시져/함수등의 이름을 같거나 혹은 다른 별칭으로 지정할수 있음.
- 보통 다른 유저의 객체(테이블, 뷰, 프로시저, 함수, 패키지, 시퀀스 등)를 참조할 때 많이 사용.
- 현업에서는 테이블 오너로 테이블을 생성하고 APP사용자에게 시노님을 생성하고 권한을 부여하여 통제/관리하고 있음
예시) SCOTT.EMP : SCOTT 유저에 EMP 테이블을 생성하고, APP유저에게 APP.EMP 시노님을 생성 한후 C/R/U/D 권한 부여
- 실제로 SYNONYM을 이용하는 이유는 다른 유저의 객체를 사용할 때 유저의 이름과 객체의 실제 이름을 사용하는데, 그 두 개를 감춤으로써 데이터베이스의 보안을 개선하기 위해 사용
1.2.1 시노님(Synonym) 생성[편집]
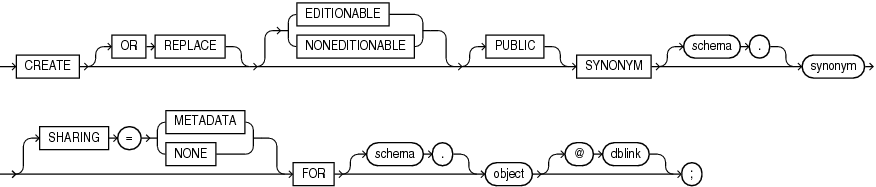
CREATE [ PUBLIC ] SYNONYM [ OWNER.시노님 이름 ]
FOR [ OWNER.객체 이름 ];- PUBLIC은 모든 사용자가 접근이 가능하도록 설정
- PUBLIC을 선언해주지 않으면 기본값으로 PRIVATE가 선언
1.2.2 시노님 생성 후 권한 부여[편집]
-- SCOTT 유저의 EMP테이블의 모든 권한을 APP유저에게 부여함
GRANT ALL ON SCOTT.EMP
TO APP;
-- OR
GRANT SELECT,INSERT,UPDATE,DELETE -- 개별적으로 사용 가능
ON SCOTT.EMP
TO APP;1.2.3 시노님(Synonym) 삭제[편집]
DROP SYNONYM [ OWNER.시노님 이름 ] ;1.3 테이블 작업[편집]
1.3.1 INSERT[편집]
INSERT 문

1.3.1.1 INSERT ~ VALUES[편집]
-- 컬럼 생략
INSERT INTO table_name VALUES ('Value1', 'Value2', ... );
INSERT INTO table_name( Column1, Column2, ... )
VALUES ( 'Value1', 'Value2', ... );1.3.1.2 INSERT ~ SELECT[편집]
INSERT INTO table_name( SELECT Value1, Value2, ... from table_name );
--
INSERT INTO table_name
( Column1, Column2, ... )
( SELECT Value1, Value2, ... from table_name );1.3.1.3 INSERT ALL INTO ~ VALUES[편집]
- 조건에 따라서 여러개의 테이블에 INSERT 할 경우 사용
INSERT ALL
WHEN sal >= 3000 THEN
INTO emp_sal1 VALUES (empno, name, sal)
WHEN sal >= 2000 THEN
INTO emp_sal2 VALUES (empno, name, sal)
ELSE
INTO emp_sal3 VALUES (empno, name, sal)
SELECT a.empno
, a.name
, a.sal
FROM emp a
WHERE a.empno = 111.3.1.4 INSERT FIRST[편집]
- 조건에 만족하는 첫 번째 WHEN~THEN의 테이블에만 INSERT
INSERT FIRST
WHEN sal >= 3000 THEN
INTO table1 VALUES (empno, ename, sal)
WHEN sal >= 2000 THEN
INTO table2 VALUES (empno, ename, sal)
ELSE
INTO table3 VALUES (empno, ename, sal)
SELECT a.empno
, a.ename
, a.sal
FROM emp a
WHERE a.empno = 77881.3.2 UPDATE[편집]
1.3.2.1 다중 UPDATE[편집]
UPDATE TB_MIG_SEQ_MGR A
SET A.TABLE_HAN_NAME = (
SELECT COMMENTS FROM DBA_TAB_COMMENTS B
WHERE B.TABLE_NAME = A.TABLE_NAME
AND B.OWNER = A.OWNER
)
;1.3.3 MERGE INTO 절[편집]
attach_file - 주의사항
- ON(조인) 조건절에 사용한 컬럼은 UPDATE 불가
- 트리거 발생되지 않음
1.3.4 MERGE 문법[편집]

MERGE [ hint ]
-- 1.MERGE 대상 테이블
INTO [ schema. ] { table | view } [ t_alias ]
-- 2.비교 대상 조회
USING { [ schema. ] { table | view }
| subquery
} [ t_alias ]
-- 3.조인 조건
ON ( condition )
-- 4.데이터 존재시 --
WHEN MATCHED THEN
UPDATE SET column = { expr | DEFAULT }
[, column = { expr | DEFAULT } ]...
[ DELETE where_clause ]
-- 4.데이터 미존재시 --
WHEN NOT MATCHED THEN
INSERT [ (column [, column ]...) ]
VALUES ({ expr [, expr ]... | DEFAULT })
;- - INTO : DATA가 UPDATE되거나 INSERT 될 테이블 또는 뷰를 지정.
- - USING : 비교할 SOURCE 테이블 또는 뷰나 서브쿼리를 지정, INTO절의 테이블과 동일하거나 다를 수 있다.
- - ON : UPDATE나 INSERT를 하게 될 조건으로, 해당 조건을 만족하는 DATA가 있으면 WHEN MATCHED 절을 실행하게 되고, 없으면 WHEN NOT MATCHED 이하를 실행하게 된다.
- - WHEN MATCHED : ON 조건절이 TRUE인 ROW에 수행 할 내용 (UPDATE, DELETE포함 될 수 있음)
- - WHEN NOT MATCHED : ON 조건절에 맞는 ROW가 없을 때 수행할 내용 (INSERT)
1.3.4.1 샘플1[편집]
MERGE INTO emp_merge_test m
--------------------------------
USING emp e
--------------------------------
ON (m.empno = e.empno)
--------------------------------
WHEN MATCHED THEN
UPDATE SET m.sal = ROUND(m.sal*1.1)
DELETE WHERE (m.deptno = 20) -- 부서번호 20의 사원정보는 삭제.
--------------------------------
WHEN NOT MATCHED THEN
INSERT (m.empno, m.deptno, m.sal)
VALUES (e.empno, e.deptno, ROUND(e.sal*1.2))
;
--------------------------------
COMMIT;1.3.4.2 샘플2[편집]
MERGE INTO TB_TUNE_SQL_STATS T
USING (SELECT 1 SNAP_ID
, SQL_TEXT, SQL_FULLTEXT, SQL_ID, LAST_ACTIVE_TIME, LAST_ACTIVE_CHILD_ADDRESS
, PLAN_HASH_VALUE, PARSE_CALLS, DISK_READS, DIRECT_WRITES, BUFFER_GETS
, ROWS_PROCESSED, SERIALIZABLE_ABORTS, FETCHES, EXECUTIONS, END_OF_FETCH_COUNT
, LOADS, VERSION_COUNT, INVALIDATIONS, CPU_TIME
, ELAPSED_TIME, AVG_HARD_PARSE_TIME, APPLICATION_WAIT_TIME, CONCURRENCY_WAIT_TIME
, USER_IO_WAIT_TIME, PLSQL_EXEC_TIME, JAVA_EXEC_TIME, SORTS, SHARABLE_MEM, TOTAL_SHARABLE_MEM
, TYPECHECK_MEM, IO_INTERCONNECT_BYTES, PHYSICAL_READ_REQUESTS, PHYSICAL_READ_BYTES
, PHYSICAL_WRITE_REQUESTS, PHYSICAL_WRITE_BYTES
FROM V$SQLSTATS
WHERE LAST_ACTIVE_TIME BETWEEN SYSDATE-1/24/60*10 AND SYSDATE -- 10분전 ([TODO] SNAPID 시간으로 변경)
) S
ON (T.SQL_ID = S.SQL_ID
)
WHEN MATCHED THEN
-- SQL_ID가 같으면 업데이트
UPDATE SET T.SQL_TEXT = S.SQL_TEXT , T.SQL_FULLTEXT = S.SQL_FULLTEXT , T.LAST_ACTIVE_TIME = S.LAST_ACTIVE_TIME , T.LAST_ACTIVE_CHILD_ADDRESS = S.LAST_ACTIVE_CHILD_ADDRESS , T.PLAN_HASH_VALUE = S.PLAN_HASH_VALUE , T.PARSE_CALLS = S.PARSE_CALLS , T.DISK_READS = S.DISK_READS , T.DIRECT_WRITES = S.DIRECT_WRITES , T.BUFFER_GETS = S.BUFFER_GETS , T.ROWS_PROCESSED = S.ROWS_PROCESSED , T.SERIALIZABLE_ABORTS = S.SERIALIZABLE_ABORTS , T.FETCHES = S.FETCHES , T.EXECUTIONS = S.EXECUTIONS , T.END_OF_FETCH_COUNT = S.END_OF_FETCH_COUNT , T.LOADS = S.LOADS , T.VERSION_COUNT = S.VERSION_COUNT , T.INVALIDATIONS = S.INVALIDATIONS , T.CPU_TIME = S.CPU_TIME , T.ELAPSED_TIME = S.ELAPSED_TIME , T.APPLICATION_WAIT_TIME = S.APPLICATION_WAIT_TIME , T.CONCURRENCY_WAIT_TIME = S.CONCURRENCY_WAIT_TIME , T.USER_IO_WAIT_TIME = S.USER_IO_WAIT_TIME , T.PLSQL_EXEC_TIME = S.PLSQL_EXEC_TIME , T.JAVA_EXEC_TIME = S.JAVA_EXEC_TIME , T.SORTS = S.SORTS
WHEN NOT MATCHED THEN
-- SQL_ID가 없으면 인서트
INSERT (SNAP_ID,SQL_TEXT ,SQL_FULLTEXT ,SQL_ID ,LAST_ACTIVE_TIME ,LAST_ACTIVE_CHILD_ADDRESS ,PLAN_HASH_VALUE ,PARSE_CALLS ,DISK_READS ,DIRECT_WRITES ,BUFFER_GETS ,ROWS_PROCESSED ,SERIALIZABLE_ABORTS ,FETCHES ,EXECUTIONS ,END_OF_FETCH_COUNT ,LOADS ,VERSION_COUNT ,INVALIDATIONS ,CPU_TIME ,ELAPSED_TIME ,APPLICATION_WAIT_TIME ,CONCURRENCY_WAIT_TIME ,USER_IO_WAIT_TIME ,PLSQL_EXEC_TIME ,JAVA_EXEC_TIME ,SORTS)
VALUES (S.SNAP_ID,S.SQL_TEXT ,S.SQL_FULLTEXT ,S.SQL_ID ,S.LAST_ACTIVE_TIME ,S.LAST_ACTIVE_CHILD_ADDRESS ,S.PLAN_HASH_VALUE ,S.PARSE_CALLS ,S.DISK_READS ,S.DIRECT_WRITES ,S.BUFFER_GETS ,S.ROWS_PROCESSED ,S.SERIALIZABLE_ABORTS ,S.FETCHES ,S.EXECUTIONS ,S.END_OF_FETCH_COUNT ,S.LOADS ,S.VERSION_COUNT ,S.INVALIDATIONS ,S.CPU_TIME ,S.ELAPSED_TIME ,S.APPLICATION_WAIT_TIME ,S.CONCURRENCY_WAIT_TIME ,S.USER_IO_WAIT_TIME ,S.PLSQL_EXEC_TIME ,S.JAVA_EXEC_TIME ,S.SORTS)
;1.3.4.3 ORA-30926 에러[편집]
ORA-30926 : unable to get a stable set of rows in the source tables (원본 테이블의 고정 행 집합을 가져올 수 없습니다.)
- INSERT 또는 UPDATE 할 때 1개의 레코드를 대상으로 작업이 가능
- 하지만 SELECT의 결과가 2개 이상이 리턴되었기 때문에 오류 발생
- INSERT 구문에서 중복이 발생하거나 UPDATE 에 MULTI ROW가 UPDATE되는 경우 오류
- ON 구문에서 UPDATE되는 ROW가 1개 이상일 경우 오류
- (해결방법) ON 절의 Join 조건에 USING() 에서 좋회하는 결과가 중복된 값이 없으면 된다.
1.3.4.4 ORA-00600 에러 발생(12c)[편집]
A SQL MERGE statement fails with next error on sqlplus and in the alert log:
ORA-00600: internal error code, arguments: [upsRowVec4]1.3.4.4.1 해결 방안[편집]
- 패치
- alter session 명령
alter session set "_optimizer_eliminate_filtering_join"=false;or
alter session set optimizer_features_enable='11.1.0.7';1.3.5 오라클 테이블 생성 , CREATE TABLE[편집]
The syntax to create a table is:
CREATE TABLE [table name]
( [column name] [datatype], ... )
TABLESPACE TS_XXX
PCTUSED 40
PCTFREE 10
INITRANS 1
MAXTRANS 255
STORAGE (...)
LOGGING
MONITORING
;예시:
CREATE TABLE "SYS"."TB_BIG"
( "COLA" VARCHAR2(20 BYTE),
"COLB" NUMBER,
"COLC" NUMBER,
"COLD" VARCHAR2(30 BYTE),
"COLE" VARCHAR2(30 BYTE),
"COLF" VARCHAR2(30 BYTE),
"COLG" NUMBER,
"COLH" VARCHAR2(30 BYTE),
"COLI" VARCHAR2(30 BYTE)
)
PCTFREE 10
PCTUSED 40
INITRANS 1
MAXTRANS 255
NOCOMPRESS LOGGING
STORAGE( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT
)
TABLESPACE USERS
;1.3.5.1 BLOCK SIZE[편집]
- 32K
- 평균 row size가 커서 8K사용중인 테이블에서 row migration , row chaining이 자주발생할경우
- 한번에 대량 i/o가 발생 하는 테이블인 경우
1.3.5.2 PCTFREE[편집]
- 디폴트는 10 퍼센트 - 블록의 10 퍼센트를 데이터 갱신을위한 빈 영역으로 남겨둠.
- default, 기본 => 10
- DML이 발생되지 않는 테이블, 백업용 압축테이블 => 0
- Update/Delete 가 빈번하게 발생되는 테이블 => 20
- 채번 테이블 => 90
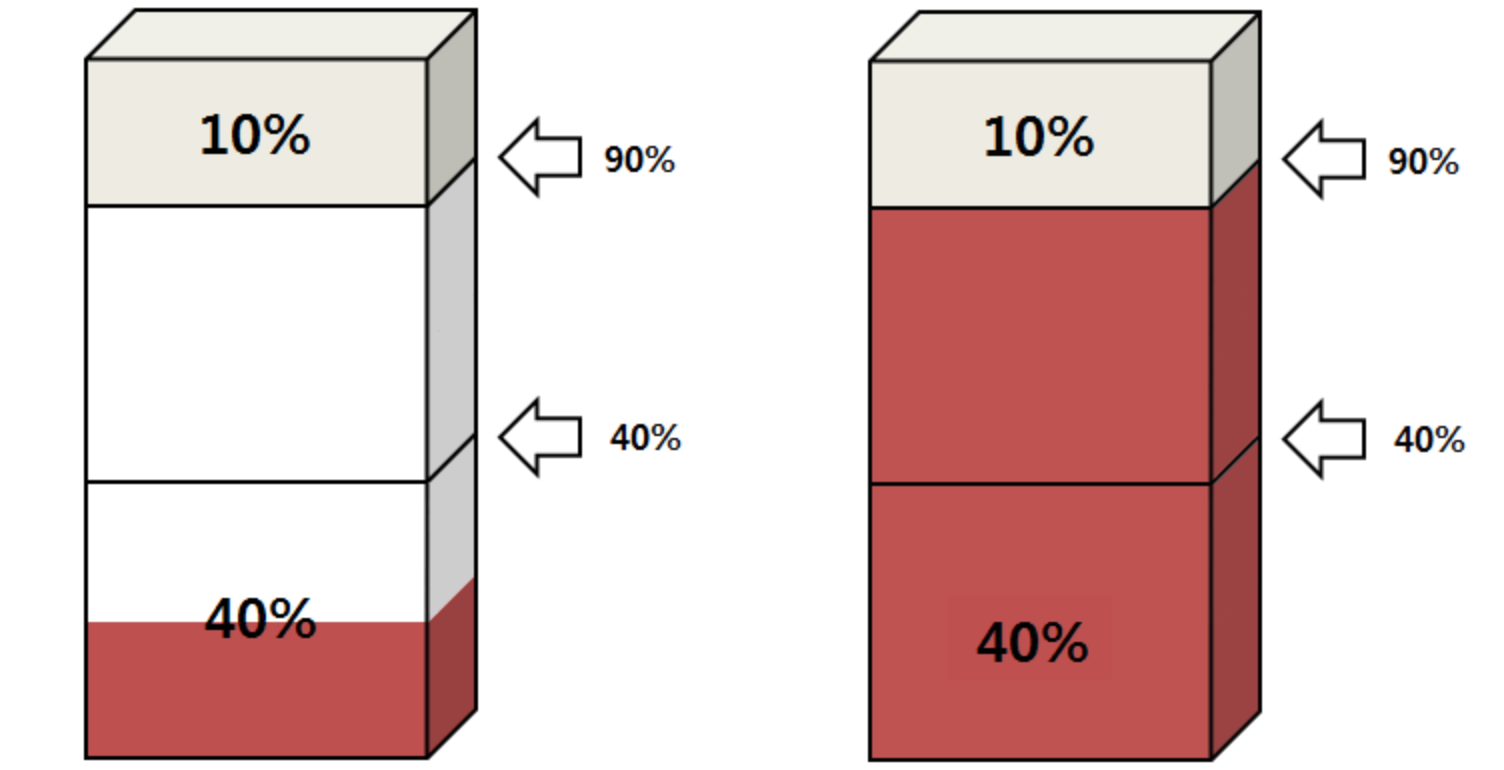
- PCTFREE 10% , PCTUSED 40%
1.3.5.3 PCTUSED[편집]
- 재사용 되기 위해 필요한 블럭의 퍼센트
- 디폴트 40 - 사용된 영역이 40% 보다 작아져야 새로운 행을 삽입 가능.
- 입력/삭제가 자주 발생하지 않으면 => 90
- 수정이 자주 발생되면 => 40
1.3.5.4 FREELIST[편집]
- FREE 블럭을 리스트 형태로 관리.
- INSERT 작업이 많이 발생하는 테이블,인덱스에 이값을 증가 시켜 빈 블럭을 할당받기 위해서 대기 하는일이 없도록 해야함.
1.3.5.5 INITRANS 와 MAXTRANS[편집]
- INITRANS
- 데이터 블록에 동시에 접근 가능한 트랜잭션의 처리 갯수를 의미(미리 확보할 ITL entry수)
- 트랜잭션이 많이 발생하는 경우 MAXTRANS 까지 늘어나며, PCTFREE 로 확보된 영역에 추가 확장 됨
- MAXTRANS
- 데이터 블록에 접근 가능한 최대 트랜잭션 수를 의미
- 접근하는 트랜잭션 수가 MAXTRNAS 값을 초과하는 경우, 앞의 트랜잭션이 COMMIT 혹은 ROLLBACK 을 해야 다음 트랜잭션이 접근 가능
- 최대 255개
- INITRANS 을 위한 슬롯도 블록에 공간을 차지하며, 트랜잭션이 많지 않은 경우 낭비를 하게 되므로 굳이 크게 설정할 필요 없음
2 -- 기본
10 ~ 20 -- 트랜잭션이 빈번하게 발생할것으로 예상되는 테이블
15 -- 로그성 테이블
30 -- 채번테이블
1.3.5.6 INITRANS 와 MAXTRANS[편집]
- 데이터 블럭을 처음 사용하기 위해 포맷시 블럭헤더에 있는 itl slot을 몇개를 할당할지 지정하는 값
- 테이블 과 인덱스 생성시 지정 함.
- 초기값은 INITRANS의 값으로 정의되며 미리 확보할 ITL entry수를 의미한다.(테이블 생성시 initttans 기본값은 2 임)
- 최대값은 MAXTRANS 값으로 ITL Entry의 최대 수를 의미한다. (기본 255)
- 만약 모든 가용한 ITL이 사용중이고 새로운 ITL 슬롯을 동적으로 할당하기위한 PCTFREE 영역의 공간이 충분하지 않을때는 엔트리를 할당받지 못하여 TX Lock 경합이 발생하게 된다.
- - 이때는 ITL entry를 차지한 다른 트랜잭션이 커밋이나 롤백을 수행하여 ITL 슬롯을 재사용할 수 있을때까지 대기함
- - enq:TX allocate itl entry 대기 이벤트 발생
- 오라클은 row단위의 lock을 걸지만 일단 데이터의 Access시 블럭 단위로 엑세스 하므로 결국 block 단위의 lock이 필요하다.
- 블럭헤더에 미리 할당한 itl slot 이 모두 사용중이라면 maxtrans로 지정된 개수 만큼 추가 itl slot을 할당 할수 있음.
1.3.6 ALTER TABLE[편집]

1.3.7 컬럼 추가 변경 삭제 관리[편집]
1.3.7.1 컬럼 추가[편집]
컬럼 추가 :
ALTER TABLE [table name]
ADD ( [column name] [datatype], ... );For 예시:
ALTER TABLE employee
ADD (id int)1.3.7.2 컬럼 수정[편집]
컬럼명(rename) 변경:
ALTER TABLE [table name]
RENAME COLUMN [column name] TO [new column name] );예시:
ALTER TABLE employee
RENAME COLUMN col_01 TO col_02;
컬럼 속성(modify) 변경:
ALTER TABLE [table name]
MODIFY ( [column name] [new datatype] );예시:
ALTER TABLE employee
MODIFY( sickHours float );1.3.7.3 컬럼 삭제[편집]
컬럼 삭제 :
ALTER TABLE [table name]
DROP COLUMN [column name];예시:
ALTER TABLE employee
DROP COLUMN vacationPay;- 항목
1.3.7.4 Constraints 제약조건[편집]
1.3.7.5 Constraint types and codes[편집]
| Type Code | Type Description | Acts On Level |
| C | Check on a table | Column |
| O | Read Only on a view | Object |
| P | Primary Key | Object |
| R | Referential AKA Foreign Key | Column |
| U | Unique Key | Column |
| V | Check Option on a view | Object |
1.3.7.5.1 제약조건(constraints) 조회[편집]
모든 제약 조건 조회 뷰:
SELECT table_name,
constraint_name,
constraint_type
FROM dba_constraints;1.3.7.5.2 FK (외래키) 제약조건[편집]
모든 외래키 제약 조건 원본과 참조 테이블/컬럼 조회 :
SELECT c_list.CONSTRAINT_NAME as NAME,
c_src.TABLE_NAME as SRC_TABLE,
c_src.COLUMN_NAME as SRC_COLUMN,
c_dest.TABLE_NAME as DEST_TABLE,
c_dest.COLUMN_NAME as DEST_COLUMN
FROM ALL_CONSTRAINTS c_list,
ALL_CONS_COLUMNS c_src,
ALL_CONS_COLUMNS c_dest
WHERE c_list.CONSTRAINT_NAME = c_src.CONSTRAINT_NAME
AND c_list.R_CONSTRAINT_NAME = c_dest.CONSTRAINT_NAME
AND c_list.CONSTRAINT_TYPE = 'R'
GROUP BY c_list.CONSTRAINT_NAME,
c_src.TABLE_NAME,
c_src.COLUMN_NAME,
c_dest.TABLE_NAME,
c_dest.COLUMN_NAME;1.3.7.6 테이블 제약 조건 설정[편집]
테이블 생성시 제약 조건 추가 :
CREATE TABLE table_name
(
column1 datatype null/not null,
column2 datatype null/not null,
...
CONSTRAINT constraint_name CHECK (column_name condition) [DISABLE]
);예시:
CREATE TABLE suppliers
(
supplier_id numeric(4),
supplier_name varchar2(50),
CONSTRAINT check_supplier_id
CHECK (supplier_id BETWEEN 100 and 9999)
);1.3.7.7 Unique 인덱스 추가[편집]
테이블 생성시 Unique 인덱스 추가 :
CREATE TABLE table_name
(
column1 datatype null/not null,
column2 datatype null/not null,
...
CONSTRAINT constraint_name UNIQUE (column1, column2, column_n)
);For 예시:
CREATE TABLE customer
(
id integer not null,
name varchar2(20),
CONSTRAINT customer_id_constraint UNIQUE (id)
);1.3.7.8 Unique 제약 조건 추가[편집]
ALTER TABLE [table name]
ADD CONSTRAINT [constraint name] UNIQUE( [column name] ) USING INDEX [index name];예시:
ALTER TABLE employee
ADD CONSTRAINT uniqueEmployeeId UNIQUE(employeeId) USING INDEX ourcompanyIndx_tbs;1.4 인덱스[편집]
기본적으로 Oracle은 B-tree 인덱스를 만듭니다.
1.4.1 인덱스 생성[편집]

The syntax for creating an index is:
CREATE [UNIQUE] INDEX index_name
ON table_name (column1, column2, . column_n)
[ COMPUTE STATISTICS ];UNIQUE 인덱싱 된 열의 값 조합이 고유해야 함을 나타냅니다.
COMPUTE STATISTICS 인덱스 작성 중에 통계를 수집하도록 Oracle에 지시합니다. 그런 다음 명령문이 실행될 때 옵티마이저가 통계를 사용하여 최적의 실행 계획을 선택합니다.
For 예시:
CREATE INDEX customer_idx
ON customer (customer_name);예시, customer_idx라는 고객 테이블에 인덱스가 작성되었습니다. customer_name 필드로만 구성됩니다.
The following creates an index with more than one field:
CREATE INDEX customer_idx
ON supplier (customer_name, country);
'''The following collects statistics upon creation of the index:'''CREATE INDEX customer_idx
ON supplier (customer_name, country)
COMPUTE STATISTICS;1.4.2 함수 인덱스 생성[편집]
In Oracle, you are not restricted to creating indexes on only columns. You can create function-based indexes.
The syntax that creates a function-based index is:
CREATE [UNIQUE] INDEX index_name
ON table_name (function1, function2, . function_n)
[ COMPUTE STATISTICS ];For 예시:
CREATE INDEX customer_idx
ON customer (UPPER(customer_name));An index, based on the uppercase evaluation of the customer_name field, has been created.
To assure that the Oracle optimizer uses this index when executing your SQL statements, be sure that UPPER(customer_name) does not evaluate to a NULL value. To ensure this, add UPPER(customer_name) IS NOT NULL to your WHERE clause as follows:
SELECT customer_id, customer_name, UPPER(customer_name)
FROM customer
WHERE UPPER(customer_name) IS NOT NULL
ORDER BY UPPER(customer_name);1.4.3 인덱스명 변경[편집]
ALTER INDEX index_name
RENAME TO new_index_name;For 예시:
ALTER INDEX customer_id
RENAME TO new_customer_id;예시, customer_id renamed to new_customer_id.
1.4.4 인덱스 통계 정보 수집[편집]
인덱스에서 통계를 수집하는 구문은 다음과 같습니다.
ALTER INDEX index_name
REBUILD COMPUTE STATISTICS;예시:
ALTER INDEX customer_idx
REBUILD COMPUTE STATISTICS;예시, customer_idx라는 인덱스에 대한 통계가 수집됩니다.
1.4.5 인덱스 삭제[편집]
DROP INDEX index_name;1.5 롤 생성 삭제 관리[편집]
1.5.1 ROLE 생성[편집]
CREATE ROLE RL_MANAGER;1.5.2 ROLE에 권한 부여[편집]
GRANT create session, create table
TO RL_MANAGER;1.5.3 권한이 부여된 ROLE을 USER나 ROLE에 부여[편집]
GRANT RL_MANAGER
TO scott, test;1.5.4 롤에 부여된 권한 회수[편집]
REVOKE RL_MANAGER
FROM 유저명1.5.5 디폴트 롤 (default role, 부여된 롤에 대한 일시 정지 )[편집]
alter user 유저명
default role 롤1, 롤2;
-- or
-- 해당 유저에게 부여된 모든 롤을 사용하되 롤3은 제외한다.
alter user 유저명
default role all except 롤3;- 유저에게 롤1, 롤2, 롤3이 부여되어 있다고 할 때, 위 명령 실행시 유저는 롤1과 롤2만 쓰고 나머지 롤3은 일시적으로 안쓴다.
- 해당 유저에게 부여된 모든 롤을 사용한다.
alter user 유저명
default role all;- 해당 유저에게 부여된 모든 롤을 사용하지 않는다.
SQL> alter user 유저명
default role none;1.5.6 셋 롤(set role)[편집]
- 유저가 일시적으로 자기가 부여받은 롤 범위 내에서 사용과 미사용을 제어 가능.
SQL>
set role 롤1; -- 해당 유저는 롤1을 사용함.
set role all; -- 해당 유저는 부여받은 롤을 모두 사용함.1.5.7 롤 생성 후 바로 적용이 되지 않을때[편집]
- 일단 현재 세션을 종료 후 재접속 해본다.
1.5.7.1 현재 세션에 활성화 된 롤 체크[편집]
-- Check active roles in the current session
SELECT * FROM SESSION_ROLES;1.5.8 롤 삭제[편집]
DROP ROLE RL_MANAGER1.5.9 (예제) 롤 생성 / 테이블 권한 부여 / 확인[편집]
- DBCAFE 유저에 테이블 생성
- RL_DBCAFE_ALL 롤을 생성
- DBCAFE 유저에 생성된 테이블의 CRUD 권한을 RL_DBCAFE_ALL롤에 부여
- RL_DBCAFE_ALL롤을 CYKIM 유저에게 부여
- CYKIM 유저가 DBCAFE 유저 테이블 CRUD 처리 확인
-- 1. DBCAFE 유저에 테이블 생성
CREATE TABLE DBCAFE.TB_DBCAFE (A NUMBER);
INSERT INTO DBCAFE.TB_DBCAFE VALUES (1);
COMMIT;
-- 2. 롤 생성
CREATE ROLE RL_DBCAFE_ALL;
-- 세션 생성권한 부여
GRANT CREATE SESSION TO RL_DBCAFE_ALL;
-- 3.DBCAFE.TB_DBCAFE 테이블 CRUD 권한을 RL_DBCAFE_ALL 에게 부여
GRANT SELECT,INSERT,UPDATE,DELETE ON DBCAFE.TB_DBCAFE TO RL_DBCAFE_ALL ;
-- 4. 일반사용자 CYKIM 에게 RL_DBCAFE_ALL 롤 부여
GRANT RL_DBCAFE_ALL TO CYKIM;
-- 5.일반사용자 CYKIM유저가 DBCAFE.TB_DBCAFE 테이블에 CRUD 되는지 확인
INSERT INTO DBCAFE.TB_DBCAFE
VALUES (2);
COMMIT;
SELECT * FROM DBCAFE.TB_DBCAFE;
1.5.9.1 롤/시스템권한/테이블권한 조회[편집]
-- Check the roles granted to the user
SELECT * FROM DBA_ROLE_PRIVS WHERE GRANTEE = 'MY_NEW_USER';
-- Check the privileges granted to the role
SELECT * FROM DBA_SYS_PRIVS WHERE GRANTEE = 'MY_NEW_ROLE';
SELECT * FROM DBA_TAB_PRIVS WHERE GRANTEE = 'MY_NEW_ROLE';1.5.9.2 롤 활성화[편집]
-- Set the role to be active
SET ROLE my_new_role;1.6 롤 조회 딕셔너리 뷰[편집]
| 딕셔너리 뷰 | 설명 |
|---|---|
| DBA_ROLES | 롤 목록 조회 |
| ROLE_ROLE_PRIVS | 롤에게 부여된 롤 권한 조회 |
| ROLE_SYS_PRIVS | 롤에게 부여된 시스템 권한 조회 |
| ROLE_TAB_PRIVS | 롤에게 부여된 테이블 권한 조회 |
| DBA_ROLE_PRIVS | 조회가능한 롤 목록 |
| USER_TAB_PRIVS_RECD | 유저에게 부여된 오브젝트 권한 |
| USER_COL_PRIVS_MADE | 유저 오브젝트 컬럼에 부여된 오브젝트 권한 |
| USER_COL_PRIVS_RECD | 특정 컬럼에 대해 유저에게 부여된 오브젝트 권한
Object privileges granted to the user on specific columns |
| SESSION_ROLES | 현재 세션에 활성화 된 롤 조회 |
1.6.2 롤에 부여된 시스템 권한조회[편집]
- - ROLE_SYS_PRIVS 롤에 부여된 시스템 권한 조회
- SELECT ANY DICTIONARY ....
- CREATE SEQUENCE / ANY SYNONYM ....
- DROP ....
- ALTER SESSION .....
SELECT *
FROM DBA_SYS_PRIVS
WHERE GRANTEE IN('롤이름')1.6.3 롤에 부여된 테이블 권한 조회[편집]
SELECT *
FROM ROLE_TAB_PRIVS
WHERE ROLE IN('롤이름')1.7 테이블 스페이스 (TABLESPACE)[편집]
1.7.1 TABLESPACE 목록 조회[편집]
SELECT A.TABLESPACE_NAME
, FILE_NAME
, BYTES / 1024 / 1024
, MAXBYTES / 1024 / 1024
, AUTOEXTENSIBLE
, B.BLOCK_SIZE
, INCREMENT_BY * B.BLOCK_SIZE / 1024 / 1024
FROM DBA_DATA_FILES A
, DBA_TABLESPACES B
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME
ORDER BY B.BLOCK_SIZE, A.TABLESPACE_NAME, A.FILE_ID;1.7.2 TABLESPACE 종류[편집]
1.7.3 현재 유저의 DEFAULT TABLESPACE 확인[편집]
SELECT * FROM USER_USERS ;-- DEFAUT TABLESPACE로 설정된 부분을 확인1.7.3.1 유저의 DEFAULT TABLESPACE 변경[편집]
ALTER USER [유저명] DEFAULT TABLESPACE [테이블 스페이스명]1.7.4 TABLESPACE 생성 구문[편집]


CREATE [BIGFILE/SMALLFILE] TABLESPACE TABLESPACE명
DATAFILE '파일경로1' SIZE integer [M/K], '파일경로2' SIZE integer [M/K]
[ MINIMUM EXTENT integer [M/K]]
[ BLOCKSIZE integer [K]]
[ DEFAULT STORAGE (
INITIAL integer [M/K]
NEXT integer [M/K]
MAXEXTENTS integer
MINEXTENTS integer
PCTINCREASE integer)]
[ ONLINE | OFFLINE ]
[ PERMANENT | TEMPORARY ]
[ EXTENT MANAGEMENT [ DICTIONARY | LOCAL
[ AUTOALLOCATE | UNIFORM [ SIZE integer [M/K]]]]]
[ SEGMENT SPACE MANAGEMENT [ MANUAL | AUTO]]
;
-- AUTOEXTEND ON NEXT 10M ==> (옵션)데이타 파일 용량초과시 자동증가설정
-- MAXSIZE 100M ==> (옵션)데이타파일 최대크기지정
-- EXTENT MANAGEMENT LOCAL ==> (옵션)
-- UNIFORM SIZE 1M ==> (옵션)
-- DEFAULT STORAGE(
: INITIAL 80K ==> 테이블 스페이스의 맨 첫번째 EXTENTS의 크기
: NEXT 80K ==> 다음 EXTENTS의 크기
: MINNEXTENTS 1 ==> 생성할 EXTENTS의 최소값
: MAXNEXTENTS 121 ==> 생성할 EXTENTS의 최대값
: PCTINCREASE 80 ==> EXTENTS의 증가율,(DEFAULT값은 50%)
: )1.7.4.1 BIGFILE 테이블스페이스[편집]
- 8K 블록 - bigfile 테이블 스페이스에는 최대 32TB
- 32K 블록 - bigfile 파일 테이블 스페이스에는 최대 128TB
1.7.4.1.1 BIGFILE 테이블스페이스 장점[편집]
1.7.4.1.2 자동 수행 뷰 목록[편집]
android 장점
- CREATE DATABASE 및 CREATE CONTROLFILE 문의 DB_FILES 초기화 매개 변수와 MAXDATAFILES 매개 변수를 조정하여 데이터 파일 정보에 필요한 SGA 공간의 양과 제어 파일의 크기를 줄일 수 있다.
- Bigfile 테이블 스페이스는 데이터 파일 투명성을 제공하여 데이터베이스 관리를 단순화합니다.
- ALTER TABLESPACE 문의 SQL 구문을 사용하면 기본 개별 데이터 파일이 아닌 테이블 스페이스에서 작업을 수행 할 수 있다.
- 빅파일 테이블 스페이스는 자동 세그먼트 공간 관리가있는 로컬 관리 테이블 스페이스에 대해서만 가능함. (언두,템프,시스템 테이블스페이스는 지원 안함)
1.7.4.1.3 BIGFILE 테이블스페이스 단점[편집]
android BIGFILE 테이블스페이스 단점
- 병렬 쿼리 실행 및 RMAN 백업 병렬화에 부정적인 영향을 미치므로 스트라이핑을 지원하지 않는 시스템에서 빅 파일 테이블 스페이스를 생성하지 마십시오.
- 큰 파일 크기를 지원하지 않는 OS 플랫폼에서 bigfile 테이블 스페이스를 사용하는 것은 권장되지 않으며 테이블 스페이스 용량을 제한 할 수 있습니다.
- Bigfile 테이블 스페이스는 ASM (Automatic Storage Management) 또는 스트라이핑 또는 RAID를 지원하는 기타 논리 볼륨 관리자 및 동적으로 확장 가능한 논리 볼륨과 함께 사용하기위한 것입니다.
1.7.5 UNDO TABLESPACE 생성[편집]
CREATE UNDO TABLESPACE [테이블 스페이스명] ==> 이부분만 다름.
DATAFILE '\경로\TEST_UNDO.DBF'
SIZE 10M
AUTOEXTEND ON NEXT 10M
MAXSIZE 100M
-- UNDO_MANAGEMENT와 UNDO_TABLESPACE, UNDO_RETENTION PARAMETER를 제공
-- 지역적으로 관리되는 익스텐트만 사용가능
-- 시스템에 의해 관리되는 익스텐트 할당만 사용가능하다.
-- (UNIFORMSIZE를 할당 할 수 없고 AUTOALLOCATE만 가능)1.7.6 TABLESPACE 변경[편집]
1.7.6.1 TABLESPACE 읽기/쓰기 모드 변경[편집]
- 읽기 전용 모드
alter tablespace <TABLESPACE명> read only;- 읽기 쓰기 모드
alter tablespace <TABLESPACE명> read ,write;1.7.6.2 OPEN 상태에서 DATAFILE 이동[편집]
alter tablespace TABLESPACE명 offline;1.7.6.2.1 offline 된 T/S에 대해 복사/이동[편집]
cp /data1/xxx.dbf /data2/xxx.dbf
or
mv /data1/xxx.dbf /data2/xxx.dbf1.7.6.2.2 OFFLINE 상태에서 DATAFILE 이동[편집]
alter tablespace TABLESPACE명 rename datafile '파일경로1/xxx.dbf' to '파일경로2/xxx.dbf';
alter tablespace TABLESPACE명 online;1.7.7 테이블의 TABLESPACE MOVE[편집]
ALTER TABLE [테이블명]
MOVE TABLESPACE [테이블 스페이스명]- -테이블스페이스 이동시 인덱스 리빌드 필요
ALTER INDEX [인덱스명] REBUILD ;- 인덱스 리빌드 동시 수행 시
ALTER TABLE [테이블명]
MOVE TABLESPACE [테이블 스페이스명]
UPDATE INDEXES;1.7.7.1 파티션닝 테이블 TABLESPACE MOVE[편집]
ALTER TABLE [테이블명]
MOVE PARTITION [파티션명] TABLESPACE [테이블 스페이스명]- 파티셔닝 테이블 인덱스 REBUILD
ALTER INDEX [인덱스명]
REBUILD PARTITION [파티션명]1.7.8 운영중인 테이블 TABLESPACE ONLINE MOVE[편집]
ALTER TABLE [테이블명]
MOVE TABLESPACE [테이블 스페이스명]
ONLINE -- online 옵션
;
- 인덱스 리빌드 동시 수행 시
ALTER TABLE [테이블명]
MOVE TABLESPACE [테이블 스페이스명]
UPDATE INDEXES
ONLINE -- online 옵션
;1.7.8.1 운영중인 파티션닝 테이블 TABLESPACE ONLINE MOVE[편집]
ALTER TABLE [테이블명]
MOVE PARTITION [파티션명] TABLESPACE [테이블 스페이스명]
ONLINE
- Move 작업 중 다른 세션의 DML 작업이 가능함
- 파티션의 로컬인덱스는 USABLE 상태로 바로 사용가능함(unusable 되지 않음)
- 도메인 인덱스가 포함된 테이블은 사용불가
- 온라인 Move 작업시 parallel DML , Direct Path Insert 가 안됨(즉,성능은 좋지않다)
1.7.9 TABLESPACE 사이즈 변경(RESIZE)[편집]
ALTER TABLESPACE ts_txxxx
RESIZE 500G;1.7.10 TABLESPACE 이름 변경[편집]
ALTER TABLESPACE [asis-TABLE] RENAME TO [tobe-TABLE]1.7.11 인덱스의 TABLESPACE 변경[편집]
ALTER INDEX 인덱스명 REBUILD TABLESPACE [테이블 스페이스명]
[ PARALLEL parallel_num ]
[ LOGGING or NOLOGGING ]
;1.7.12 인덱스의 TABLESPACE 변경 스크립트[편집]
SELECT 'ALTER INDEX '||index_name||' REBUILD TABLESPACE TS_OO_'||substr(a.index_name,4,2)||'_I;'
FROM user_indexes a
WHERE a.index_name NOT IN (SELECT index_name from user_part_indexes)
AND substr(a.index_name,4,2) IN (SELECT SUBJECT_CD FROM TB_DBA_SUBJECT_CD);1.7.13 인덱스/테이블 TABLESPACE 변경 스크립트[편집]
SELECT DECODE (segment_type, 'TABLE', segment_name, table_name) order_col1
, DECODE (segment_type, 'TABLE', 1, 2) order_col2
, 'alter '
|| segment_type
|| ' '
|| segment_name
|| DECODE (segment_type, 'TABLE', ' MOVE ', ' REBUILD ')
|| CHR (10)
|| ' TS_오너_01 '
|| CHR (10)
|| ' storage ( initial '
|| initial_extent
|| ' next '
|| next_extent
|| CHR (10)
|| ' minextents '
|| min_extents
|| ' maxextents '
|| max_extents
|| CHR (10)
|| ' pctincrease '
|| pct_increase
|| ' freelists '
|| freelists
|| ');'
FROM user_segments, (SELECT table_name, index_name FROM user_indexes)
WHERE segment_type IN ('TABLE', 'INDEX') AND segment_name = index_name(+)
ORDER BY 1, 2;
1.7.14 TABLESPACE 자동증가/최대 사이즈 변경[편집]
ALTER TABLESPACE ts_txxxx
AUTOEXTEND ON
NEXT 100M
MAXSIZE 500G;-- 최대사이즈 , UNLIMITED => 무제한 증가
- 최대 TABLESPACE 사이즈 변경
ALTER TABLESPACE [테이블 스페이스명]
ADD DATAFILE 'C:\경로\TEST2.DBF' SIZE 10M
AUTOEXTEND ON NEXT 100M
MAXSIZE 100G;
==> 10M씩 자동증가1.7.15 데이터파일 사이즈 변경[편집]
ALTER DATABASE DATAFILE 'C:\경로\TEST1.DBF'
RESIZE 10M;1.7.16 데이터파일 추가[편집]
ALTER TABLESPACE [테이블 스페이스명]
ADD DATAFILE 'C:\경로\TEST2.DBF' SIZE 10M;1.7.17 데이터/템프파일 삭제[편집]
ALTER TABLESPACE [테이블 스페이스명]
DROP DATAFILE 'data파일';
-- 템프TS DROP TEMPFILE 'data파일';1.7.18 데이터 파일 삭제 후 OS 디스크 사이즈가 줄지 않을경우[편집]
attach_file 1) 테이블스페이스 사이즈를 줄인 (shrink) 후 데이터파일 삭제
2) DB 리부팅 하면 공간 확보 됨(DBWR 이 데이터파일을 사용중이기 때문에 공간이 줄지 않음)
1.7.19 TABLESPACE 삭제[편집]
1.7.19.1 TABLESPACE에 포함된 모든 세그먼트 삭제[편집]
DROP TABLESPACE [테이블 스페이스명]
INCLUDING CONTENTS;-- TABLESPACE의 모든 세그먼트를 삭제한다.
-- 단, 데이타가 있는 TABLESPACE는 삭제할수 없다.1.7.19.2 TABLESPACE에 포함된 테이블의 참조/제약 조건 삭제[편집]
DROP TABLESPACE [테이블 스페이스명]
CASCADE CONSTRAINTS; -- 삭제된 TABLESPACE 내의 테이블의 기본키와 유일키를 참조하는
-- 다른 TABLESPACE의 테이블로부터 참조무결성 제약 조건을 삭제한다.1.7.19.3 TABLESPACE의 데이터파일 삭제[편집]
DROP TABLESPACE [테이블 스페이스명]
INCLUDING CONTENTS AND DATAFILES; -- 물리적파일까지 삭제한다.
1.7.20 TABLESPACE 수정이나 삭제시 ONLINE/OFFLINE 설정[편집]
ALTER TABLESPACE [테이블 스페이스명] ONLINE
ALTER TABLESPACE [테이블 스페이스명] OFFLINE1.7.21 템프 TABLESPACE[편집]
1.7.21.1 TEMPORARY TABLESPACE 정보[편집]
SELECT d.TABLESPACE_NAME
, d.FILE_NAME
, d.BYTES / 1024 / 1024 SIZE_MB
, d.AUTOEXTENSIBLE
, d.MAXBYTES / 1024 / 1024 MAXSIZE_MB
, d.INCREMENT_BY * (v.BLOCK_SIZE / 1024) / 1024 INCREMENT_BY_MB
FROM dba_temp_files d, v$tempfile v
WHERE d.FILE_ID = v.FILE#
ORDER BY d.TABLESPACE_NAME, d.FILE_NAME1.7.21.1.1 템프테이블 사이즈 조정[편집]
ALTER DATABASE TEMPFILE 'D:\APP\ORADATA\ORCL\TEMP01.DBF'
RESIZE 304M;1.7.21.2 TEMPORARY TABLESPACE 생성[편집]
- . 신규생성만 가능.
: 사용중인 TEMP TABLESPACE 는 삭제가 안되므로 신규로 템프 TABLESPACE를 생성
CREATE TEMPORARY TABLESPACE [테이블 스페이스명]
TEMPFILE '\경로\TEST_TEMP.DBF'
SIZE 10M
AUTOEXTEND ON
NEXT 100M
MAXSIZE 300G
EXTENT MANAGEMENT LOCAL
UNIFORM SIZE 512K -- LOCALY MANAGED TABLESPACE UNIFORM SIZE만 생성가능하다.
-- (주의)AUTOALLOCATE, EXTENT MANAGEMENT DICIONARY OPTION을 사용하면 ORA-25319 ERROR 발생한다.
-- RENAME 이 불가능하다.1.7.21.3 TEMPORARY TABLESPACE를 DEFAULT TABLESPACE로 변경[편집]
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE [테이블 스페이스명];1.7.21.4 TEMPORARY TABLESPACE 사이즈 증가[편집]
ALTER TABLESPACE TEMP
AUTOEXTEND ON
NEXT 100M
MAXSIZE 500G;1.7.21.5 TEMPORARY TABLESPACE 사이즈 추가[편집]
ALTER TABLESPACE TEMP
ADD TEMPFILE '+DATA' SIZE 10G
AUTOEXTEND ON
NEXT 100M
MAXSIZE 32767M;1.7.21.6 TEMPORARY TABLESPACE 삭제[편집]
DROP TABLESPACE TEMP2;1.7.21.7 TEMPORARY TABLESPACE DATA FILE 삭제[편집]
ALTER TABLESPACE TEMP DROP TEMPFILE '+DATA/temp.368.1013282149';- +DATA/temp.368.1013282149 은 ASM 사용시
1.7.21.8 TEMPORARY TABLESPACE 사용율 조회 쿼리[편집]
/* TEMP 사용 쿼리 확인 */
select a.username, a.sid, a.serial#, b.blocks, a.program, a.module, a.action, a.machine, a.status, a.event, d.sql_Text ,
b.blocks*8192/1024/1024 mb
from v$session a,
v$sort_usage b,
v$process c,
v$sqlarea d
where a.saddr = b.session_addr
and a.paddr = c.addr
and a.sql_hash_value= d.hash_value
and b.tablespace like 'TEMP%'
--and a.username ='MIG_ADM'
ORDER BY A.MACHINE, SQL_TEXT1.7.21.9 템프테이블 TABLESPACE sort 사용 현황[편집]
SELECT
A.tablespace_name tablespace,
D.mb_total,
SUM (A.used_blocks * D.block_size) / 1024 / 1024 mb_used,
D.mb_total - SUM (A.used_blocks * D.block_size) / 1024 / 1024 mb_free
FROM
v$sort_segment A,
(
SELECT
B.name,
C.block_size,
SUM (C.bytes) / 1024 / 1024 mb_total
FROM
v$tablespace B,
v$tempfile C
WHERE
B.ts#= C.ts#
GROUP BY
B.name,
C.block_size
) D
WHERE
A.tablespace_name = D.name
GROUP by
A.tablespace_name,
D.mb_total1.8 TABLESPACE 오브젝트별 정보[편집]
1.8.1 TABLESPACE/파일 확인(딕셔너리)[편집]
SELECT * FROM DBA_DATA_FILES ;
SELECT * FROM DBA_TABLESPACES ;
SELECT * FROM DBA_SEGMENTS;1.8.2 TABLESPACE별 정보[편집]
SELECT A.TABLESPACE_NAME AS "TABLESPACE"
, A.INITIAL_EXTENT / 1024 AS "INIT(K)"
, A.NEXT_EXTENT / 1024 AS "NEXT(K)"
, A.MIN_EXTENTS AS "MIN"
, A.MAX_EXTENTS AS "MAX"
, A.PCT_INCREASE AS "PCT_INC(%)"
, B.FILE_NAME AS "FILE_NAME"
, B.BLOCKS * C.VALUE / 1024 / 1024 AS "SIZE(M)"
, B.STATUS AS "STATUS"
FROM DBA_TABLESPACES A
, DBA_DATA_FILES B
, V$PARAMETER C
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME
AND C.NAME = 'db_block_size'
ORDER BY 1, 2;1.8.3 TABLESPACE별 파일 목록[편집]
SELECT SUBSTRB(TABLESPACE_NAME, 1, 10) AS "TABLESPACE"
, SUBSTRB(FILE_NAME, 1, 50) AS "파일명"
, TO_CHAR(BLOCKS, '999,999,990') AS "블럭수"
, TO_CHAR(BYTES, '99,999,999') AS "크기"
FROM DBA_DATA_FILES ORDER BY TABLESPACE_NAME, FILE_NAME;1.8.4 TABLESPACE 사이즈 정보[편집]
1.8.4.1 TABLESPACE별 전체 오브젝트(테이블/인덱스/LOB) 사이즈[편집]
-- OBJECT별 테이블 사이즈 (UNDO,TEMP T/S 제외)
-- SELECT TABLESPACE_NAME
-- , SUM(SIZE_MB)
-- FROM (
SELECT A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024) "SIZE_MB"
FROM DBA_SEGMENTS A
, DBA_TABLES B
WHERE A.SEGMENT_NAME = B.TABLE_NAME
AND A.SEGMENT_TYPE IN ('TABLE','TABLE PARTITION')
-- AND A.OWNER = '유저아이디'
GROUP BY A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
UNION ALL
-- INDEX SIZE
SELECT A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024) "SIZE_MB"
FROM DBA_SEGMENTS A
, DBA_INDEXES B
WHERE A.SEGMENT_NAME = B.INDEX_NAME
AND A.SEGMENT_TYPE IN ('INDEX','INDEX PARTITION')
-- AND A.OWNER = '유저아이디'
GROUP BY A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
-- ORDER BY 2 DESC;
UNION ALL
-- LOB
SELECT A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024) "SIZE_MB"
FROM DBA_SEGMENTS A
, DBA_LOBS B
WHERE A.segment_name = B.segment_name
AND A.SEGMENT_TYPE LIKE 'LOB%'
GROUP BY A.TABLESPACE_NAME
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
ORDER BY SEGMENT_TYPE,TABLESPACE_NAME DESC
-- )
-- GROUP BY TABLESPACE_NAME
;1.8.4.2 TABLESPACE별 사이즈[편집]
SELECT Substr(df.tablespace_name,1,20) "Tablespace Name",
Substr(df.file_name,1,80) "File Name",
Round(df.bytes/1024/1024,0) "Size (M)",
decode(e.used_bytes,NULL,0,Round(e.used_bytes/1024/1024,0)) "Used (M)",
decode(f.free_bytes,NULL,0,Round(f.free_bytes/1024/1024,0)) "Free (M)",
decode(e.used_bytes,NULL,0,Round((e.used_bytes/df.bytes)*100,0)) "% Used"
FROM DBA_DATA_FILES DF,
(SELECT file_id,
sum(bytes) used_bytes
FROM dba_extents
GROUP by file_id) E,
(SELECT sum(bytes) free_bytes,
file_id
FROM dba_free_space
GROUP BY file_id) f
WHERE e.file_id (+) = df.file_id
AND df.file_id = f.file_id (+)
ORDER BY df.tablespace_name,
df.file_name1.8.4.3 테이블 TABLESPACE 사이즈[편집]
-- 테이블 사이즈
SELECT A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024/1024) "SIZE_GB"
FROM DBA_SEGMENTS A
, DBA_TABLES B
WHERE A.SEGMENT_NAME = B.TABLE_NAME
AND A.SEGMENT_TYPE IN ('TABLE','TABLE PARTITION')
-- AND A.OWNER = '유저아이디'
GROUP BY A.SEGMENT_NAME
, A.SEGMENT_TYPE1.8.4.4 인덱스 TABLESPACE 사이즈[편집]
-- INDEX SIZE
SELECT A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024/1024) "SIZE_GB"
FROM DBA_SEGMENTS A
, DBA_INDEXES B
WHERE A.SEGMENT_NAME = B.INDEX_NAME
AND A.SEGMENT_TYPE IN ('INDEX','INDEX PARTITION')
-- AND A.OWNER = '유저아이디'
GROUP BY A.SEGMENT_NAME
, A.SEGMENT_TYPE
ORDER BY 2 DESC;1.8.4.5 LOB TABLESPACE 사이즈[편집]
-- LOB 사이즈
SELECT TABLE_NAME
, sum(bytes)
FROM (SELECT B.table_name AS table_name
, A.bytes
FROM DBA_SEGMENTS A
, DBA_LOBS B
WHERE A.segment_name = B.segment_name
)
group by table_name;1.8.4.6 데이터파일 별 테이블스페이스 사이즈 조회[편집]
SELECT A.TABLESPACE_NAME "테이블스페이스명",
A.FILE_NAME "파일경로",
(A.BYTES - B.FREE) "사용공간",
B.FREE "여유 공간",
A.BYTES "총크기",
TO_CHAR( (B.FREE / A.BYTES * 100) , '999.99')||'%' "여유공간"
FROM
(
SELECT FILE_ID,
TABLESPACE_NAME,
FILE_NAME,
SUBSTR(FILE_NAME,1,200) FILE_NM,
SUM(BYTES) BYTES
FROM DBA_DATA_FILES
GROUP BY FILE_ID,TABLESPACE_NAME,FILE_NAME,SUBSTR(FILE_NAME,1,200)
) A,
(
SELECT TABLESPACE_NAME,
FILE_ID,
SUM(NVL(BYTES,0)) FREE
FROM DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME,FILE_ID
) B
WHERE A.TABLESPACE_NAME=B.TABLESPACE_NAME
AND A.FILE_ID = B.FILE_ID;
1.8.4.7 TABLESPACE별 사용하는 파일의 크기 합[편집]
SELECT SUBSTRB(TABLESPACE_NAME, 1, 10) AS TABLESPACE
, TO_CHAR(SUM(BYTES), '9,999,999,999,990') AS BYTES
, TO_CHAR(SUM(BLOCKS), '9,999,999,990') AS BLOCKS
FROM DBA_DATA_FILES GROUP BY TABLESPACE_NAME
UNION ALL
SELECT '총계', TO_CHAR(SUM(BYTES), '9,999,999,999,990') AS BYTES, TO_CHAR(SUM(BLOCKS), '9,999,999,990') AS BLOCKS
FROM DBA_DATA_FILES;1.8.4.8 TABLESPACE별 디스크 사용량[편집]
SELECT A.TABLESPACE_NAME AS "TABLESPACE"
, A.INIT AS "INIT(K)"
, A.NEXT AS "NEXT(K)"
, A.MIN AS "MIN"
, A.MAX AS "MAX"
, A.PCT_INC AS "PCT_INC(%)"
, TO_CHAR(B.TOTAL, '999,999,999,990') AS "총량(바이트)"
, TO_CHAR(C.FREE, '999,999,999,990') AS "남은량(바이트)"
, TO_CHAR(B.BLOCKS, '9,999,990') AS "총블럭"
, TO_CHAR(D.BLOCKS, '9,999,990') AS "사용블럭"
, TO_CHAR(100 * NVL(D.BLOCKS, 0) / B.BLOCKS, '999.99') AS "사용율%"
FROM (SELECT TABLESPACE_NAME
, INITIAL_EXTENT / 1024 AS INIT
, NEXT_EXTENT / 1024 AS NEXT
, MIN_EXTENTS AS MIN
, MAX_EXTENTS AS MAX
, PCT_INCREASE AS PCT_INC
FROM DBA_TABLESPACES) A
, (SELECT TABLESPACE_NAME, SUM(BYTES) AS TOTAL, SUM(BLOCKS) AS BLOCKS
FROM DBA_DATA_FILES
GROUP BY TABLESPACE_NAME) B
, (SELECT TABLESPACE_NAME, SUM(BYTES) AS FREE
FROM DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) C
, (SELECT TABLESPACE_NAME, SUM(BLOCKS) AS BLOCKS
FROM DBA_EXTENTS
GROUP BY TABLESPACE_NAME) D
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME(+)
AND A.TABLESPACE_NAME = C.TABLESPACE_NAME(+)
AND A.TABLESPACE_NAME = D.TABLESPACE_NAME(+)
ORDER BY A.TABLESPACE_NAME;1.8.4.9 공간의 90% 이상을 사용하고 있는 TABLESPACE[편집]
SELECT X.TABLESPACE_NAME
, TOTAL_SIZE / 1024 / 1024 TOTAL_SIZE
, USED_SIZE / 1024 / 1024 USED_SIZE
, (ROUND(USED_SIZE / TOTAL_SIZE, 2)) * 100 USED_RATIO
FROM (SELECT TABLESPACE_NAME, SUM(BYTES) TOTAL_SIZE
FROM DBA_DATA_FILES
GROUP BY TABLESPACE_NAME) X
, (SELECT TABLESPACE_NAME, SUM(BYTES) USED_SIZE
FROM DBA_EXTENTS
GROUP BY TABLESPACE_NAME) Y
WHERE X.TABLESPACE_NAME = Y.TABLESPACE_NAME(+) AND Y.USED_SIZE > .9 * X.TOTAL_SIZE;1.8.5 TABLESPACE에 포함된 테이블 명 보기[편집]
SELECT TABLESPACE_NAME
, TABLE_NAME
FROM DBA_TABLES
WHERE TABLESPACE_NAME = UPPER('&TABLESPACE명')
ORDER BY TABLESPACE_NAME
, TABLE_NAME;1.8.6 오브젝트별 TABLESPACE 및 데이터파일[편집]
SELECT DISTINCT E.SEGMENT_NAME, E.TABLESPACE_NAME, F.FILE_NAME
FROM DBA_EXTENTS E
, DBA_DATA_FILES F
WHERE E.FILE_ID = F.FILE_ID
AND E.SEGMENT_TYPE = 'TABLE'
AND E.TABLESPACE_NAME NOT IN ('SYSTEM', 'TOOLS');1.8.7 TABLESPACE별 Table, Index 개수[편집]
SELECT OWNER
, TABLESPACE_NAME
, SUM(DECODE(SEGMENT_TYPE, 'TABLE', 1, 0)) TAB
, SUM(DECODE(SEGMENT_TYPE, 'INDEX', 1, 0)) IDX
, SUM(DECODE(SEGMENT_TYPE, 'LOBINDEX', 1, 0)) LOB_IDX
, SUM(DECODE(SEGMENT_TYPE, 'LOBSEGMENT', 1, 0)) LOB_SEG
FROM DBA_SEGMENTS
WHERE SEGMENT_TYPE IN ('TABLE', 'INDEX', 'LOBINDEX','LOBSEGMENT')
GROUP BY OWNER, TABLESPACE_NAME;1.8.8 파일위치별 TABLESPACE 아는 방법[편집]
SELECT SUBSTRB(A.FILE_NAME, 1, 40) AS FILE_NAME
, A.FILE_ID
, B.FREE_BYTES / 1024 AS FREE_BYTES
, B.MAX_BYTES / 1024 AS MAX_BYTES
FROM DBA_DATA_FILES A
, (SELECT FILE_ID, SUM(BYTES) AS FREE_BYTES, MAX(BYTES) AS MAX_BYTES
FROM DBA_FREE_SPACE
GROUP BY FILE_ID) B
WHERE A.FILE_ID = B.FILE_ID
AND A.TABLESPACE_NAME = UPPER('&TABLESPACE명')
ORDER BY A.FILE_NAME;1.8.9 현재 Extension 횟수가 MaxExtents의 80% 이상인 경우[편집]
SELECT TABLESPACE_NAME
, OWNER
, SEGMENT_NAME
, SEGMENT_TYPE
, EXTENTS
, MAX_EXTENTS
FROM SYS.DBA_SEGMENTS S
WHERE EXTENTS / MAX_EXTENTS > .8 AND MAX_EXTENTS > 0
ORDER BY TABLESPACE_NAME, OWNER, SEGMENT_NAME;1.8.10 테이블의 익스텐트 정보 조회[편집]
SELECT B.SEGMENT_NAME
, B.MAX_EXTENTS
, MAX(C.EXTENT_ID) AS EXTENT_ID
, B.MAX_EXTENTS - MAX(C.EXTENT_ID) AS DIFF
FROM USER_TABLESPACES A
, USER_SEGMENTS B
, USER_EXTENTS C
WHERE A.EXTENT_MANAGEMENT = 'DICTIONARY'
AND B.TABLESPACE_NAME = A.TABLESPACE_NAME
AND C.SEGMENT_NAME = B.SEGMENT_NAME
GROUP BY B.SEGMENT_NAME, B.MAX_EXTENTS
HAVING B.MAX_EXTENTS - MAX(C.EXTENT_ID) <= 50
ORDER BY B.MAX_EXTENTS - MAX(C.EXTENT_ID);1.9 UNDO TABLESPACE[편집]
- UNDO Segment를 저장하고 있는 TABLESPACE , 관리자가 생성/관리 가능
- Instance당 여러 개가 동시에 존재할 수 있지만 사용은 한번에 1개만
1.9.1 현재 UNDO 상태 확인[편집]
SELECT A.TABLESPACE_NAME,A.STATUS, B.TOTAL_MB, A.USE_MB,
ROUND(RATIO_TO_REPORT(A.USE_MB) OVER(PARTITION BY A.TABLESPACE_NAME) * 100)||'%' AS PCT
FROM (SELECT TABLESPACE_NAME, STATUS,
ROUND(SUM(BYTES/1024/1024)) USE_MB
FROM DBA_UNDO_EXTENTS
GROUP BY TABLESPACE_NAME,STATUS
)A,
(SELECT TABLESPACE_NAME, ROUND(SUM(BYTES)/1024/1024) TOTAL_MB
FROM DBA_DATA_FILES
WHERE TABLESPACE_NAME LIKE 'UNDO%'
GROUP BY TABLESPACE_NAME
)B
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME
ORDER BY 1,21.9.2 UNDO 테이블 스페이스 삭제[편집]
DROP TABLESPACE UNDO_T1 INCLUDING CONTENTS AND DATAFILES;
1.9.3 ROLLBACK SEGMENT의 사용상황 보기[편집]
--: EXTENTS = 현재 할당된 EXTENT의 수 --: EXTENDS = 마지막 트랜잭션에 의해 할당된 EXTENT의 수
SELECT SUBSTRB(A.SEGMENT_NAME, 1, 10) AS SEGMENT_NAME
, SUBSTRB(A.TABLESPACE_NAME, 1, 10) AS TABLESPACE_NAME
, TO_CHAR(A.SEGMENT_ID, '99,999') AS SEG_ID
, TO_CHAR(A.MAX_EXTENTS, '999,999') AS MAX_EXT
, TO_CHAR(B.EXTENTS, '999,999') AS EXTENTS
, TO_CHAR(B.EXTENDS, '999,999') AS EXTENDS
, TO_CHAR((A.INITIAL_EXTENT + (B.EXTENTS - 1) * A.NEXT_EXTENT) / 1000000, '9,999.999') AS "ALLOC(MB)"
, TO_CHAR(XACTS, '9,999') AS XACTS
FROM DBA_ROLLBACK_SEGS A
, V$ROLLSTAT B
WHERE A.SEGMENT_ID = B.USN(+) ORDER BY 1;1.10 TABLESPACE 장애 처리[편집]
1.10.1 TABLESPACE 용량 부족으로 에러 발생시[편집]
- 방법 1) Data file을 크게 늘려줌(자동 증가/수동증가)
- 방법 2) Data file을 하나 더 추가
1.10.1.1 Tablespace Offline[편집]
- 사용자가 더 이상 해당 Tablespace에 접근하지 못한다는 의미
- 데이터파일의 위치를 이동하거나 특정 Tablespace가 장애가 나서 복구해야 할 때 사용
1.10.1.2 TABLESPACE 를 Offline하는 방법 3가지[편집]
1) Normal Mode
SQL> alter TABLESPACE TS_TEST offline ;2) Temporary Mode
Normal이 수행되지 못할 때(Tablespace의 Data file 이상) 사용하는 방법
3) Immediate Mode
- 반드시 Archive Log Mode일 경우에만 사용. - Data file에 장애가 나서 데이터를 내려쓰지 못하는 상황에서 TABLESPACE 를 offline해야 할 경우 사용
1.10.1.3 TABLESPACE 이동하기[편집]
1) Offline되는 Tablespace의 Data file 이동하기
- 해당 Tablespace Offline 하기
ALTER TABLESPACE TS_TEST OFFLINE;
- Data file을 대상 위치로 복사
- Control file 내의 해당 Data file 위치 변경
- 해당 Tablespace Online
ALTER TABLESPACE TS_TEST ONLINE;
2) Offline 안 되는 TABLESPACE 의 Data file 이동하기
- DB 종료
- Mount 상태로 시작
- Data file 복사
- Control file의 내용 변경
- DB Open
1.11 LOB포함된 TABLESPACE 용량 축소/REORG[편집]
1.11.1 해당 테이블스페이스를 사용중인 테이블/인덱스/LOB 조회[편집]
SELECT *
FROM DBA_SEGMENTS
WHERE TABLESPACE_NAME ='TS_TEST_D01';1.11.2 테이블에서 사용중인 테이블스페이스 신규테이블스페이스로 이동[편집]
SELECT OWNER
, TABLE_NAME
, TABLESPACE_NAME
, 'ALTER TABLE '||OWNER||'.'||TABLE_NAME||' MOVE TABLESPACE TS_TEST_D11;' -- 임시로 생성된 T/S로 이동
, 'ALTER TABLE '||OWNER||'.'||TABLE_NAME||' MOVE TABLESPACE '||TABLESPACE_NAME||';' MV_TS -- 다시 원래 테이블스페이스로 이동
FROM DBA_TABLES
WHERE TABLESPACE_NAME ='TS_TEST_D01'; -- TS_TEST_D01을 사용하는 테이블1.11.3 인덱스 T/S 이동(INDEX REBUILD)[편집]
SELECT OWNER
, TABLE_NAME
, INDEX_NAME
, TABLESPACE_NAME
, 'ALTER INDEX '||OWNER||'.'||INDEX_NAME||' REBUILD TABLESPACE TS_TEST_I11;' RBD_TS
FROM DBA_INDEXES
WHERE TABLESPACE_NAME ='TS_TEST_I01'; -- TS_TEST_I01을 사용하는 인덱스1.11.4 LOB T/S 이동[편집]
-- LOB 테이블 이동하기
select owner,table_name
, 'alter table '||owner||'.'||table_name||' move lob('||col||') store as (tablespace TS_TEST_D01);' mv_lob_ts
from (
select a.owner,a.table_name
, listagg(a.column_name,',') within group (order by 1) col
from dba_lobs a where table_name in
(
SELECT DISTINCT TABLE_NAME
FROM DBA_TAB_COLUMNS
WHERE OWNER = 'TEST'
AND DATA_TYPE LIKE '%LOB'
)
group by a.owner,a.table_name
)
--order by 1,2
;1.11.5 원래 T/S명으로 변경[편집]
ALTER TABLESPACE [asis-TABLE] RENAME TO [tobe-TABLE]1.12 DATAPUMP 데이터펌프[편집]
- 권한 생성
- 디렉토리 권한 부여
- 디비링크 생성 후 디비링크를 통한 데이터 펌프 실행
1.13 IMPDP (Import Datapump) 사용법[편집]
1.13.1 IMPORT 사용 예시[편집]
1.13.2 DBLINK로 IMPORT PUMP 처리 방법[편집]
1.13.3 1.DB 링크 생성[편집]
1.13.4 2.IMPDP 파라미터 파일로 실행[편집]
1.13.5 IMPORT 파라미터 샘플[편집]
1.13.6 테이블만 IMPORT(테이블 존재시 TRUNCATE)[편집]
1.13.8 IMPORT DP 파라미터[편집]
1.13.11 IMPORT DP 상세 파라미터[편집]
1.13.12 IMPORT API[편집]
1.13.13 IMPORT 스키마/테이블 API[편집]
1.13.14 IMPORT 개별 TABLE (복구시)[편집]
1.14 EXPDP (Export Datapump) 사용법[편집]
1.14.1 EXPORT 파라미터 작성[편집]
1.14.2 병렬처리 parallel 파라미터[편집]
1.14.3 tables 파라미터[편집]
1.14.4 QUERY 파라미터[편집]
1.14.5 sqlfile 파라미터[편집]
1.14.7 EXPORT DP 파라미터[편집]
1.14.9 ASM환경에서 EXPDP 실행 방법[편집]
1.15 데이터펌프 작업 관리 및 모니터링[편집]
1.15.1 ExportDP JOB 확인[편집]
1.15.1.1 터미널에서 JOB Attach 모드[편집]
expdp 아이디/비밀번호@db명 attach=JOB이름
expdp>status1.15.1.2 SQL로 확인[편집]
- dba_datapump_jobs
SELECT owner_name, job_name, operation, job_mode, state
FROM dba_datapump_jobs;- sys.v_$sqlarea
select substr(sql_text,instr(sql_text,'INTO "'),30) table_name
, rows_processed
, round((sysdate-to_date(first_load_time,'yyyy-mm-dd hh24:mi:ss'))*24*60,1) minutes
, trunc(rows_processed/((sysdate-to_date(first_load_time,'yyyy-mm-dd hh24:mi:ss'))*24*60)) rows_per_min
from sys.v_$sqlarea
where sql_text like 'INSERT %INTO "%'
and command_type = 2
and open_versions > 0;1.15.2 Datapump 작업 진행사항[편집]
SELECT X.JOB_NAME
, B.STATE
, B.JOB_MODE
, B.DEGREE
, X.OWNER_NAME
, Z.SQL_TEXT
, P.MESSAGE
, P.TOTALWORK
, P.SOFAR
, ROUND ( (P.SOFAR / P.TOTALWORK) * 100, 2) DONE
, P.TIME_REMAINING
FROM DBA_DATAPUMP_JOBS B
LEFT JOIN DBA_DATAPUMP_SESSIONS X ON (X.JOB_NAME = B.JOB_NAME)
LEFT JOIN V$SESSION Y ON (Y.SADDR = X.SADDR)
LEFT JOIN V$SQL Z ON (Y.SQL_ID = Z.SQL_ID)
LEFT JOIN V$SESSION_LONGOPS P ON (P.SQL_ID = Y.SQL_ID)
-- WHERE Y.MODULE = 'Data Pump Worker' AND P.TIME_REMAINING > 0
;1.16 데이터펌프(DATAPUMP) JOB 중지[편집]
SELECT * FROM DBA_DATAPUMP_JOBS;1.16.1 IMPDP ATTACH=JOB 접속 후[편집]
$>IMPDP SCOTT/TIGER@DB ATTACH=JOB명
KILL_JOB
STOP_JOB #STOP_JOB = IMMEDIATE 즉시 종료1.16.2 API 이용 정지[편집]
- 주의) 즉시 정지 하지 않음
DECLARE
h1 NUMBER;
BEGIN
h1:=DBMS_DATAPUMP.ATTACH(JOB_NAME => '"MIG_CHANGED_TABLE"', JOB_OWNER => 'RTIS_MIG');
DBMS_DATAPUMP.STOP_JOB(h1,1,0);
END;1.17 EXPORT API[편집]
1.17.1 스키마 EXPORT[편집]
DECLARE
hndl NUMBER;
TAG_NAME VARCHAR2(30) := 'EXP_MIG_TEST01';
BEGIN
hndl := DBMS_DATAPUMP.OPEN( operation => 'EXPORT'
, job_mode => 'SCHEMA' -- FULL, SCHEMA, TABLE, TABLESPACE, TRANSPORTABLE
, job_name=>'JOB_'||TAG_NAME
--, remote_link => 'DBLINK_NAME', version => 'LATEST'
);
DBMS_DATAPUMP.ADD_FILE( handle => hndl, filename => TAG_NAME||'.dmp', directory => 'DATA_PUMP_DIR', filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_DUMP_FILE, reusefile=>1);
DBMS_DATAPUMP.ADD_FILE( handle => hndl, filename => TAG_NAME||'.log', directory => 'DATA_PUMP_DIR', filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_LOG_FILE);
-- DBMS_DATAPUMP.SET_PARAMETER(handle=> hndl, name=> 'INCLUDE_METADATA', value=> 1); -- META 포함여부
DBMS_DATAPUMP.DATA_FILTER(handle=> hndl, name=> 'INCLUDE_ROWS', value=> 0); -- DATA 포함 여부 0,
DBMS_DATAPUMP.METADATA_FILTER(handle=> hndl, name=> 'SCHEMA_EXPR', value=>'IN (''FED40'',''TTT'')');
-- DBMS_DATAPUMP.METADATA_FILTER(handle=> hndl, name=> 'NAME_EXPR', value=>'IN (''FED40'', ''TEST'')');
-- DBMS_DATAPUMP.METADATA_FILTER(handle=> hndl, name=> 'NAME_LIST', value=>'''EMP'',''DEPT''');
DBMS_DATAPUMP.START_JOB(hndl);
END;1.17.2 테이블 EXPORT API[편집]
-- 1.테이블 DUMP EXPORT 스크립트
DECLARE
hdnl NUMBER;
BEGIN
hdnl := DBMS_DATAPUMP.OPEN( operation => 'EXPORT', job_mode => 'SCHEMA', job_name=>'JOB_EXP_TB_RC_JEJU_14');
DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'INIT_BK_TB_RC_JEJU_14_20190910.EXP', directory => 'DATAPUMP2', filetype => dbms_datapump.ku$_file_type_dump_file ,reusefile=>1);
DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'INIT_BK_TB_RC_JEJU_14_20190910.LOG', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file ,reusefile=>1);
-- 스키마 정보
DBMS_DATAPUMP.METADATA_FILTER(handle => hdnl,
name => 'SCHEMA_EXPR',
value => ' IN (''유저명'')'
);
-- 테이블 정보
DBMS_DATAPUMP.METADATA_FILTER(handle => hdnl
,name => 'NAME_EXPR'
,value => ' IN (''테이블명'')'
,object_type => 'TABLE'
);
DBMS_DATAPUMP.START_JOB(hdnl);
END;1.18 데이터펌프 로그파일 읽기 API[편집]
DECLARE
V1 VARCHAR2(200); --32767
F1 UTL_FILE.FILE_TYPE;
BEGIN
F1 := UTL_FILE.FOPEN('DATA_PUMP_DIR','INIT_BK_TB_RC_JEJU_12_20190910.LOG','R');
Loop
BEGIN
UTL_FILE.GET_LINE(F1,V1);
dbms_output.put_line(V1);
EXCEPTION WHEN No_Data_Found THEN EXIT;
END;
end loop;
IF UTL_FILE.IS_OPEN(F1) THEN
dbms_output.put_line('File is Open');
end if;
UTL_FILE.FCLOSE(F1);
END;1.19 파일 복사(ASM등)[편집]
attach_file OS상의 파일복사 명령를 DB에서 직접 수행이 가능.
- DBMS_FILE_TRANSFER.COPY_FILE 패키지/함수
- 소스 디렉토리에서 파일을 읽고 대상 디렉토리에 복사
- ASM 과 로컬 디스크간 복사
- 소스 및 대상 디렉토리는 로컬 파일 시스템에 있거나 ASM (Automatic Storage Management) 디스크 그룹에 있거나
로컬 파일 시스템과 ASM간에 어느 방향 으로든 복사 할 수 있음.
BEGIN
DBMS_FILE_TRANSFER.COPY_FILE(
source_directory_object => 'SOURCEDIR' -- 소스 디렉토리
, source_file_name => 't_xdbtmp.f' -- 소스 파일
, destination_directory_object => 'DGROUP' -- 타켓 디렉토리
, destination_file_name =>'t_xdbtmp.f' -- 타겟 파일
);
END;
/1.19.1 DB LINK를 이용한 파일 복사(밀어 넣기)[편집]
attach_file DBMS_FILE_TRANSFER.PUT_FILE 패키지/함수
- 소스 에서 프로시져 실행 해야 함.
- 소스 => 타겟으로 복사
- 로컬 파일 또는 ASM을 읽고 원격 데이터베이스에 접속하여 원격 파일 시스템에 파일 사본을 작성합니다.
- DB링크 간의 DUMP파일 복사가 가능(.log파일은 복사 안됨,12c)
BEGIN
DBMS_FILE_TRANSFER.PUT_FILE(
source_directory_object => 'DATA_PUMP_DIR', -- 패키지 실행하는 DB
source_file_name => 'sample.dmp', -- 패키지 실행하는 DIRECTORY의 덤프파일명
destination_directory_object => 'DATA_PUMP_DIR2', -- DB링크 원격지 디렉토리
destination_file_name => 'sample_copied.dmp',-- DB링크 원격지에 저장될 파일명
destination_database => '디비링크명'
);
END;
/1.19.2 파일 복사(가져오기)[편집]
attach_file DBMS_FILE_TRANSFER.GET_FILE
- 원격 데이터베이스에 접속하여 원격 파일을 로컬 파일 시스템 또는 ASM에 파일 복사.
- 절차가 성공적으로 완료 될 때까지 대상 파일이 닫히지 않음.
BEGIN
DBMS_FILE_TRANSFER.GET_FILE(
source_directory_object => 'DATA_PUMP_DIR',
source_file_name => 'sample.dmp',
source_database => '디비링크명',
destination_directory_object => 'DATA_PUMP_DIR2',
destination_file_name => 'sample_copied.dmp'
);
END;
/1.20 DATAPUMP API 상세 정보[편집]
https://www.morganslibrary.org/reference/pkgs/dbms_datapump.html
1.21 DB LINK를 이용한 파일 복사[편집]
BEGIN
DBMS_FILE_TRANSFER.PUT_FILE(
source_directory_object => 'DATA_PUMP_DIR',
source_file_name => 'sample.dmp',
destination_directory_object => 'DATA_PUMP_DIR',
destination_file_name => 'sample_copied.dmp',
destination_database => 'to_rds'
);
END;
/1.22 PL/SQL[편집]
1.23 기본 프로시져[편집]
DECLARE
--변수,상수 선언
BEGIN
--실행 가능 SQL문,PL/SQL문
EXCEPTION
--에러처리
END;
/* PL/SQL UPDATE예제(UPDATE,DELETE는 다중행처리 가능) */
Declare
v_sale number := 2000;
begin
update test set a = v_sale;
delete from test where a = v_sale;
commit;
end;
/* Procedure에서 Procedure를 호출하는 방법 */
A프로시져에서 "B프로시져명(변수, 변수2);"
PROCEDURE 리턴 여러개
FUNCTION 리턴 한개
SELECT * FROM USER_OBJECTS WHERE OBJECT_TYPE='PROCEDURE';
/* 프로시저나 함수 조회 */
SELECT * FROM USER_OBJECTS WHERE OBJECT_TYPE='FUNCTION';
/* PROCEDURE & FUNCTION 삭제하기 */
DROP FUNCTION lee2;
DROP PROCEDURE lee2;1.24 프로시져 실행 옵션[편집]
- DBA권한이 있는데도 ORA-00942 에러 발생
AUTHID DEFINER 실행 시 컴파일 할 때의 유저 사용(DEFAULT)
AUTHID CURRENT_USER 실행 시 현재 접속하고 있는 유저 사용.- PL/SQL내에서 EXECUTE IMEDIATE 실행 시 권한없음 에러가 발생하면 AUTHID CURRENT_USER 추가
- EXECUTE IMEDIATE DDL명령 실행시 DDL명령에 선언된 OWNER(예를들어 SCOTT.XXX) 가 프로시져를 실행한 유저(예를 들어 DBADM)가 아닐때 ORA-00942에러 발생
- EXCUTE IMMEDIATE 'SQL구문'; 실행시 'SQL구문' 내부에 세미콜론은 ';' 없어야 수행됨. (중요-삽질의 시작..)
1.25 커서 활용 샘플[편집]
CREATE OR REPLACE PROCEDURE RTIS_DBA.SP_OBJ_INVALID_TO_VALID
/*
*
*/
(
IN_DATE IN VARCHAR2 DEFAULT TO_CHAR(SYSDATE,'YYYYMMDD')
)
AUTHID CURRENT_USER
IS
CURSOR INVALID_OBJECT IS
SELECT A.GRANTEE, A.OWNER, A.TABLE_NAME, A.GRANTOR, A.PRIVILEGE,A.OBJECT_TYPE
FROM TB_MGR_GRANT A
;
-- V_SQL VARCHAR2(200);
V_G_SQL VARCHAR2(200);
-- V_L_SQL VARCHAR2(2000);
V_GRANTEE VARCHAR2(100);
V_OWNER VARCHAR2(100);
V_TABLE_NAME VARCHAR2(100);
V_GRANTOR VARCHAR2(100);
V_PRIVILEGE VARCHAR2(100);
V_OBJECT_TYPE VARCHAR2(100);
V_GRANT_REVOKE_GBN VARCHAR2(100);
V_MSG long;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR V_ROW IN INVALID_OBJECT
LOOP
-- 블록 에러 발생시에도 계속 실행토록
BEGIN
V_GRANTEE:= V_ROW.GRANTEE;
V_OWNER:= V_ROW.OWNER;
V_TABLE_NAME:= V_ROW.TABLE_NAME;
V_GRANTOR:= V_ROW.GRANTOR;
V_PRIVILEGE:= V_ROW.PRIVILEGE;
V_OBJECT_TYPE:= V_ROW.OBJECT_TYPE;
V_GRANT_REVOKE_GBN := 'GRANT TO USER';
-- 권한 추가
V_G_SQL := 'GRANT '||V_ROW.PRIVILEGE||' ON '||V_ROW.OWNER||'.'||V_ROW.TABLE_NAME||' TO '||V_ROW.GRANTEE;
EXECUTE IMMEDIATE V_G_SQL;
-- LOG 기록
INSERT INTO TB_MGR_GRANT_LOG
(GRANTEE , OWNER , TABLE_NAME , GRANTOR, PRIVILEGE,OBJECT_TYPE,GRANT_REVOKE_GBN)
VALUES (V_ROW.GRANTEE,V_ROW.OWNER,V_ROW.TABLE_NAME,V_ROW.GRANTOR,V_ROW.PRIVILEGE,V_ROW.OBJECT_TYPE,V_GRANT_REVOKE_GBN);
COMMIT;
EXCEPTION
WHEN OTHERS THEN
V_MSG := 'ERROR : ['|| to_char(SQLCODE) ||']'|| substr(SQLERRM,1,500);
INSERT INTO TB_MGR_GRANT_LOG
(GRANTEE , OWNER , TABLE_NAME , GRANTOR , PRIVILEGE ,OBJECT_TYPE ,GRANT_REVOKE_GBN,GRANT_REVOKE_SQL)
VALUES (V_GRANTEE,V_OWNER,V_TABLE_NAME,V_GRANTOR,V_PRIVILEGE,V_OBJECT_TYPE,V_GRANT_REVOKE_GBN,V_MSG);
COMMIT;
END;
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('ERR MESSAGE : ' || SQLERRM);
END;
/1.25.1 명령어[편집]
1.25.1.1 산술 명령어[편집]
error
- 더하기: +
- 빼기: -
- 곱하기: *
- 나누기: /
- Power (PL/SQL only): **
1.25.1.1.1 예시[편집]
UPDATE employee SET salary = salary * 1.05
WHERE customer_id = 5;SELECT wage - tax FROM employee;1.25.1.2 비교 연산자[편집]
* 보다 크다 : >
* 크거나 같다 : >=
* 보다 작다: <
* 작거나 같다: <=
* 같다: =
* 같지 않다: != ^= <> ¬= (depends on platform)1.25.1.2.1 예시[편집]
SELECT name, salary, email FROM employees WHERE salary > 40000;
SELECT name FROM customers WHERE customer_id < 6;1.25.1.3 문자 명령어[편집]
- 문자열 합치기(Concatenate): ||
create or replace procedure addtest(
a in varchar2(100),
b in varchar2(100), c out varchar2(200)
)
IS
begin
C:=concat(a,'-',b);1.25.1.4 날짜 명령어[편집]
- 더하기: +
- 빼기: -
1.25.2 타입(Types)[편집]
1.25.2.1 PL/SQL 기본 타입[편집]
스칼라타입(Scalar type) (패키지 안에 선언STANDARD): NUMBER, CHAR, VARCHAR2, BOOLEAN, BINARY_INTEGER, LONG\LONG RAW, DATE, TIMESTAM)
콤포지트(결합) 타입(Composite types) (사용자 선언 타입 ):
TABLE, RECORD, NESTED TABLE and VARRAY
LOB 타입(LOB datatypes) : 구조화되지 않은 대량의 데이터를 저장하는 데 사용
1.25.2.2 %TYPE - 고정형 변수 선언(anchored type variable declaration)[편집]
고정형 변수 선언 Syntax
<var_name> <obj>%type [not null][:= <init-val>];For 예시
name Books.title%type; / * name은 테이블 Books의 'title' 컬럼과 동일한 유형으로 정의됩니다. * /
commission number(5,2) := 12.5;
x commission%type; / * x는 변수 'commission'과 동일한 유형으로 정의됩니다. * /Note:
- 고정 변수를 사용하면 유형이 변경 될 때 고정 변수 유형을 유형과 자동으로 동기화 할 수 있습니다.
- 고정 된 유형은 컴파일시 평가되므로 앵커 된 변수에서 유형의 변경 사항을 반영하도록 프로그램을 다시 컴파일하십시오.
1.25.2.3 콜렉션(Collections)[편집]
컬렉션은 정렬 된 요소그룹이며 모두 같은 유형입니다.
목록, 배열 및 기타 친숙한 데이터 유형을 포함하는 일반적인 개념입니다.
각 요소에는 컬렉션에서 해당 위치를 결정하는 고유한 첨자가 있습니다.
--Define a PL/SQL record type representing a book:
TYPE book_rec IS RECORD
(title book.title%TYPE,
author book.author_last_name%TYPE,
year_published book.published_date%TYPE);
--define a PL/SQL table containing entries of type book_rec:
Type book_rec_tab IS TABLE OF book_rec
INDEX BY BINARY_INTEGER;
my_book_rec book_rec%TYPE;
my_book_rec_tab book_rec_tab%TYPE;
...
my_book_rec := my_book_rec_tab(5);
find_authors_books(my_book_rec.author);
...컬렉션을 사용해야하는 많은 이유가 있습니다.
- 새로운 최적화 컴파일러, 더 나은 통합 네이티브 컴파일 및 숫자 처리 응용 프로그램에 도움이되는 새로운 데이터 유형을 포함하여 투명한 성능 향상 덕분에 훨씬 빠른 실행 속도.
- FORALL 문은 더욱 유연하고 유용합니다.
예를 들어, FORALL은 이제 비 연속 인덱스를 지원합니다.
- 정규 표현식은 PL/SQL에서 세 가지 새로운 함수 (REGEXP_INSTR, REGEXP_REPLACE 및 REGEXP_SUBSTR)와 REGEXP_LIKE 연산자를 사용하여 비교할 수 있습니다
<ref>이 문제에 대한 자세한 내용은 Jonathan Gennick의 "첫 번째 표현식"</ ref> .
- 컬렉션, 동등성을위한 컬렉션 비교 및 중첩 테이블에 대한 집합 연산 지원 등을 포함하도록 개선되었습니다.
1.25.2.4 묵시적 커서 와 커서 속성[편집]
INSERT, UPDATE, DELETE문을 수행했을 때 몇 건의 데이터가 영향을 받았는지, 즉 몇 건의 데이터가 새로 입력되고 갱신되고 삭제되었는지 알 수 있다.
예를 들어, 사원 테이블에서 80번 부서에 속한 사원은 총 34명인데, 이를 UPDATE 하는 경우
DECLARE
vn_department_id employees.department_id%TYPE := 80;
BEGIN
-- 80번 부서의 사원이름을 자신의 이름으로 갱신
UPDATE employees
SET emp_name = emp_name
WHERE department_id = vn_department_id;
-- 몇 건의 데이터가 갱신됐는지 출력
DBMS_OUTPUT.PUT_LINE(SQL%ROWCOUNT);
COMMIT;
END;
-- 결과 : 34정확히 34건이 갱신됐음을 알 수 있다.
SQL%ROWCOUNT 커서 속성을 사용해서 해당 SQL문으로 인해 실제 처리된 결과 로우 수를 참조한 것. SQL%ROWCOUNT에서 %ROWCOUNT가 커서 속성이며 앞에 붙은 SQL은 커서 이름. 묵시적 커서의 정보를 참조할 때는 SQL로 시작되는 속성명을 사용해 참조할 수 있어 묵시적 커서를 SQL 커서라고도 한다.
- 묵시적 커서 정보 참조용 커서 속성
SQL%FOUND 결과 집합의 패치 로우 수가 1개 이상이면 TRUE, 아니면 FALSE를 반환 SQL%NOTFOUND 결과 집합의 패치 로우 수가 0이면 TRUE, 아니면 FALSE를 반환 SQL%ROWCOUNT 영향 받은 결과 집합의 로우 수 반환, 없으면 0을 반환 SQL%ISOPEN 묵시적 커서는 항상 FALSE를 반환(이 속성으로 참조할 때는 이미 해당 묵시적 커서는 닫힌 상태 이후이기 때문)
1.26 참고 레퍼런스[편집]
1.26.1 함수/프로시져/익명블럭..[편집]
1.26.1.1 Functions[편집]
함수는 호출자에게 값을 반환해야합니다.
Syntax
CREATE [OR REPLACE] FUNCTION function_name [ (parameter [,parameter]) ]
RETURN [return_datatype]
IS
[declaration_section]
BEGIN
executable_section
return [return_value]
[EXCEPTION
exception_section]
END [function_name];예시:
CREATE OR REPLACE FUNCTION to_date_check_null(dateString IN VARCHAR2, dateFormat IN VARCHAR2)
RETURN DATE IS
BEGIN
IF dateString IS NULL THEN
return NULL;
ELSE
return to_date(dateString, dateFormat);
END IF;
END;1.26.1.2 Procedures[편집]
프로시저는 호출자에게 값을 리턴 안된다는 점에서 함수와 다릅니다.
Syntax:
CREATE [OR REPLACE] PROCEDURE procedure_name [ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_name];프로시저 또는 함수를 작성할 때 파라미터를 정의 할 수 있습니다.
선언 할 수있는 세 가지 유형의 매개 변수가 있습니다.
파라미터는 프로시저 나 함수에 의해 참조 될 수 있습니다.
프로시저 나 함수는 파라미터 값을 겹쳐 쓸 수 없습니다.
DEFAULT 값 선언 가능
CREATE [OR REPLACE] PROCEDURE procedure_name [ (parameter [IN|OUT|IN OUT] [DEFAULT ''value''] [,parameter]) ]The following is a simple 예시 of a procedure:
/* purpose:
목적 : courseId로 지정된 학습과정의 학생들을 보여줍니다.
*/
CREATE OR REPLACE Procedure GetNumberOfStudents
( courseId IN number, numberOfStudents OUT number )
IS
/* 학생 수를 계산하는 더 좋은 방법이 있지만
이것은 커서를 실제로 보여줄 수있는 좋은 기회입니다 */
cursor student_cur is
select studentId, studentName
from course
where course.courseId = courseId;
student_rec student_cur%ROWTYPE;
BEGIN
OPEN student_cur;
LOOP
FETCH student_cur INTO student_rec;
EXIT WHEN student_cur%NOTFOUND;
numberOfStudents := numberOfStudents + 1;
END LOOP;
CLOSE student_cur;
EXCEPTION
WHEN OTHERS THEN
raise_application_error(-20001,'An error was encountered - '||SQLCODE||' -ERROR- '||SQLERRM);
END GetNumberOfStudents;1.26.1.3 anonymous block[편집]
DECLARE
x NUMBER(4) := 0;
BEGIN
x := 1000;
BEGIN
x := x + 100;
EXCEPTION
WHEN OTHERS THEN
x := x + 2;
END;
x := x + 10;
dbms_output.put_line(x);
EXCEPTION
WHEN OTHERS THEN
x := x + 3;
END;1.26.1.4 프로시져에 파라미터 지정 방법[편집]
스토어드 프로시저에서 파라미터를 전달하기위한 세 가지 기본 구문인
- 위치 표기법,
- 명명 표기법,
- 혼합 표기법
이 있습니다.
다음 예는 매개 변수 전달에 대한 각 기본 구문에 대한 프로 시저를 호출합니다.
CREATE OR REPLACE PROCEDURE create_customer( p_name IN varchar2,
p_id IN number,
p_address IN varchar2,
p_phone IN varchar2 ) IS
BEGIN
INSERT INTO customer ( name, id, address, phone )
VALUES ( p_name, p_id, p_address, p_phone );
END create_customer;1.26.1.4.1 위치 표기법[편집]
프로시저에서 선언 된 것과 동일한 순서로 동일한 매개 변수 지정.
간결하지만 매개 변수 (특히 리터럴)를 잘못된 순서로 지정하면 버그를 감지하기 어려울 수 있습니다.
프로 시저의 매개 변수 목록이 변경되면 코드를 변경해야합니다.
begin
create_customer('James Whitfield'
, 33
, '301 Anystreet'
, '251-222-3154');
end;1.26.1.4.2 명명 표기법[편집]
각 파라미터의 이름과 해당 값을 지정하십시오.
화살표 (=>)는 연결 연산자로 사용됩니다. 파라미터의 순서는 중요하지 않습니다. 이 표기법은 좀 더 장황하지만 코드를보다 쉽게 읽고 관리 할 수 있습니다.
프로 시저의 파라미터 목록이 변경되면 매개 변수가 재정렬되거나 새로운 선택적 파라미터가 추가되는 경우 코드 변경을 피할 수 있습니다.
명명 된 표기법은 다른 사람의 API를 호출하거나 다른 사람이 사용할 API를 정의하는 코드에 사용하는 것이 좋습니다.
begin
create_customer(p_address => '301 Anystreet'
, p_id => 33
, p_name => 'James Whitfield'
, p_phone => '251-222-3154');
end;1.26.1.4.3 혼합 표기법[편집]
위치 표기법으로 첫 번째 매개 변수를 지정한 다음 마지막 매개 변수에 대해 명명 표기법으로 전환하십시오.
이 표기법을 사용하여 일부 필수 매개 변수가있는 프로 시저를 호출하고 일부 선택적 매개 변수를 호출 할 수 있습니다.
begin
create_customer(v_name -- 위치 지정법
, v_id -- 상동
, p_address=> '301 Anystreet' -- 명명 표기법
, p_phone => '251-222-3154' -- 상동
);
end;1.26.1.5 Table functions[편집]
CREATE TYPE object_row_type as OBJECT (
object_type VARCHAR(18),
object_name VARCHAR(30)
);
CREATE TYPE object_table_type as TABLE OF object_row_type;
CREATE OR REPLACE FUNCTION get_all_objects
RETURN object_table_type PIPELINED AS
BEGIN
FOR cur IN (SELECT * FROM all_objects)
LOOP
PIPE ROW(object_row_type(cur.object_type, cur.object_name));
END LOOP;
RETURN;
END;
SELECT * FROM TABLE(get_all_objects);1.26.2 흐름제어 관리[편집]
1.26.2.1 Conditional Operators[편집]
- and: AND
- or: OR
- not: NOT
1.26.2.2 예시[편집]
IF salary > 40000 AND salary <= 70000
THEN()
ELSE IF salary>70000 AND salary<=100000
THEN()
ELSE()1.26.2.3 If/then/else[편집]
IF [condition] THEN
[statements]
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSEIF [condition] THEN
[statements}
ELSE
[statements}
END IF;1.26.3 Arrays[편집]
1.26.3.1 Associative arrays[편집]
인-메모리 테이블로 유용한 강력한 Type의 배열
1.26.3.2 예시[편집]
- 매우 간단한 예, 인덱스는 배열에 액세스하는 KEY이므로 배열의 모든 행에서 데이터를 사용하지 않는 한 전체 테이블을 반복 할 필요가 없습니다.
- 인덱스는 숫자 값일 수도 있습니다.
DECLARE
-- Associative array indexed by string:
-- Associative array type
TYPE population IS TABLE OF NUMBER
INDEX BY VARCHAR2(64);
-- Associative array variable
city_population population;
i VARCHAR2(64);
BEGIN
-- Add new elements to associative array:
city_population('Smallville') := 2000;
city_population('Midland') := 750000;
city_population('Megalopolis') := 1000000;
-- Change value associated with key 'Smallville':
city_population('Smallville') := 2001;
-- Print associative array by looping through it:
i := city_population.FIRST;
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT_LINE
('Population of ' || i || ' is ' || TO_CHAR(city_population(i)));
i := city_population.NEXT(i);
END LOOP;
-- Print selected value from a associative array:
DBMS_OUTPUT.PUT_LINE('Selected value');
DBMS_OUTPUT.PUT_LINE('Population of');
END;
/
-- Printed results:
Population of Megalopolis is 1000000
Population of Midland is 750000
Population of Smallville is 2001- 좀더 복잡한 예시, using a record
DECLARE
-- Record type
TYPE apollo_rec IS RECORD
(
commander VARCHAR2(100),
launch DATE
);
-- Associative array type
TYPE apollo_type_arr IS TABLE OF apollo_rec INDEX BY VARCHAR2(100);
-- Associative array variable
apollo_arr apollo_type_arr;
BEGIN
apollo_arr('Apollo 11').commander := 'Neil Armstrong';
apollo_arr('Apollo 11').launch := TO_DATE('July 16, 1969','Month dd, yyyy');
apollo_arr('Apollo 12').commander := 'Pete Conrad';
apollo_arr('Apollo 12').launch := TO_DATE('November 14, 1969','Month dd, yyyy');
apollo_arr('Apollo 13').commander := 'James Lovell';
apollo_arr('Apollo 13').launch := TO_DATE('April 11, 1970','Month dd, yyyy');
apollo_arr('Apollo 14').commander := 'Alan Shepard';
apollo_arr('Apollo 14').launch := TO_DATE('January 31, 1971','Month dd, yyyy');
DBMS_OUTPUT.PUT_LINE(apollo_arr('Apollo 11').commander);
DBMS_OUTPUT.PUT_LINE(apollo_arr('Apollo 11').launch);
end;
/
-- Printed results:
Neil Armstrong
16-JUL-69