"Redo"의 두 판 사이의 차이
DB CAFE
(→Redo Log Buffer와 Redo Log File) |
|||
| (같은 사용자의 중간 판 49개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
| − | + | == REDO == | |
| − | |||
| − | |||
| − | |||
| − | + | {{틀:고지상자 | |
| + | |제목=REDO 개념 | ||
| + | |내용=* Redo : Re(다시) do(한다), Recovery | ||
| + | ** Redo Log : 변경되는 내용이 있을 때 모두 기록해 두었다가 장애를 대비하는 기능 | ||
| + | }} | ||
| − | + | === Redo 로그의 목적 === | |
| + | # 데이터 베이스 복구 | ||
| + | #: : 물리적인 디스크 장애시 복구, 미디어 복구(Media Recovery) 라고 함 | ||
| + | # 캐시 복구 | ||
| + | #: : 버퍼캐시에 있는 데이터가 디스크의 데이터 블럭에 기록되기 전 장애가 발생한 경우 복구, 인스턴스 복구(Instance Recovery) 라고 함. | ||
| + | # FAST COMMIT | ||
| + | #: : 트랜잭션 발생시 변경사항을 Append 방식으로 순차적으로 빠르게 로그파일에 기록하고 메모리 데이터 블럭과 디스크 데이터 파일간 동기화를 통해서 배치방식으로 일괄 수행함. | ||
| + | #:: 'Delayed 블럭 클린아웃' 방식을 이용하여 트랜잭션이 발생된 전체건이 끝나기를 기다리지 않고 우선 처리 한후 나중에 일괄 수행되는 방식. | ||
| − | + | ---- | |
| − | |||
| + | === 온라인 Redo 로그 와 아카이빙 Redo 로그 === | ||
| + | https://misogain.wordpress.com/wp-content/uploads/2024/05/archive.jpg | ||
| − | + | ==== 온라인 Redo 로그 ==== | |
| − | + | # 온라인 리두 로그는 리두로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일 | |
| − | + | # 최소 2개 파일로 구성됨 | |
| + | # 현재 사용중인 로그파일이 가득 차면 다른 리두로그파일로 로그 스위칭이 발생함 | ||
| + | # 모든 리두로그 파일이 가득 차면 처음 리두로그파일 부터 다시 재사용됨 | ||
| − | + | ==== 아카이빙 Redo 로그 ==== | |
| + | # 온라인 리두로그가 재사용되기 전에 지정된 아키이빙 로그 디렉토리에 백업 하는 파일 | ||
| − | + | ---- | |
| − | |||
| − | + | === Redo Log의 생성 원리 === | |
| + | * Oracle에서 데이터의 변경(DDL, DML, TCL등)이 발생했다면 두 매커니즘에 의해 Rodo Log에 기록됨 | ||
| + | ==== Write Log Ahead ==== | ||
| + | * 실제 데이터를 변경하기 전에 Redo Log에 먼저 기록한 후 데이터를 변경 | ||
| + | *: (DBWR이 작동하기 전에 LGWR이 작동하는 것도 이것과 같은 의미) | ||
| + | * LGWR(Log Writer)가 리두로그 버퍼를 리두로그 파일로 저장하는 시점 | ||
| + | # 3초마다 DBWR 프로세스가 준 신호를 받아서 저장 | ||
| + | # 로그 버퍼량이 3분의 1이 차거나 , 로그버퍼량이 1MB이상 일때 | ||
| + | # commit 이나 rollback이 실행될때 | ||
| − | + | ==== Log force at Commit ==== | |
| + | * 사용자로부터 Commit 요청이 들어오면 관련된 모든 Redo Record들은 Redo Log file에 저장한 후 Commit을 완료. | ||
| + | *: (Redo Log File에 기록하지 않고는 Commit을 완료하지 않는다) | ||
| − | + | * 대량의 데이터 변경 후 Commit이 한꺼번에 수행되면 Delayed Commit(지연된 커밋), Group Commit 발생 | |
| − | + | *:- Group Commit : Commit을 아주 짧은 시간 동안 모아서 한꺼번에 수행하는 기술 | |
| + | *:- 짧은 시간동안 많은 데이터가 변경된 후 한꺼번에 Commit 요청이 들어올 경우 발생 | ||
| − | + | ==== Redo log가 생성되고 기록되는 원리 ==== | |
| − | + | https://velog.velcdn.com/images/dbcafe/post/639951ce-d7f6-488e-bb26-a28ab15df1e3/image.jpg | |
| − | + | ===== Redo Log 기록 원리 ===== | |
| − | + | # 사용자가 특정 데이터를 변경하는 쿼리 수행 시에 해당 SQL을 받은 서버 프로세스는 원하는 Block이 Database Buffer Cache에 있는지 확인 | |
| − | + | #: 확인 후 없으면 해당 블록을 데이터 파일에서 찾아서 복사한 후 Buffer Cache로 가져옴. | |
| − | + | # 해당 row부분을 다른 사용자가 바꿀 수 없도록 Lock를 설정(page fix) 후 PGA에 Redo Change Vector를 생성함. | |
| − | + | #:* 체인지 벡터(Change Vector) : Redo Log에 기록할 변경된 데이터에 대한 모든 정보의 세트(복구를 위한 상세한 설명서) | |
| − | + | # Redo Log는 Commit된 데이터를 복구할 때도 사용 되지만 Rollback 데이터를 복구할 때도 사용. | |
| − | + | #:* 사용자가 커밋(commit)을 수행하고 Checkpoint 발생 전에 DB가 강제 종료 되었다면 해당 데이터를 Roll Forwared 하는 내용도 저장해야 하지만 사용자가 Rollback한 후 아직 Rollback이 완전히 완료되지 않은 상태에서 DB가 강제 종료 되었을 경우에도 Rollback 되지 못한 데이터 전부를 Rollback 해줘야 한다. | |
| − | + | #:* 그래서, Change Vector내에 Undo 관련 내용까지 함께 저장된다. | |
| − | + | # PGA에 만들어진 Change Vector는 Redo Record Format으로 Row단위로 Redo Log Buffer에 복사됨 | |
| − | + | # (PGA에서 Change Vector 생성 후 ) Redo Log Buffer에서 필요한 용량을 계산, Latch 획득 (Change Vector를 Redo Log Buffer에 복사하기 위함) | |
| − | + | #:* Latch(래치) : 한정된 메모리 자원을 여러 사용자가 사용할 때 사용할 수 있는 순서를 정해주는 역할 | |
| − | + | #:* Rodo Log Buffer에 내용을 쓰려면 두 가지 Latch를 확보해야 한다. | |
| − | + | #::1) Redo Copy Latch | |
| − | + | #:::- Redo Copy Latch : Change Vector가 모두 Redo Log Buffer에 기록될 때가지 계속 가지고 있어야 하기 때문에 여러개의 Latch가 존재한다. | |
| − | + | #::2) Redo Allocation Latch | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | ==== Redo Copy Latch 현황 조회 ==== | ||
| + | <source lang=sql> | ||
| + | SELECT name, gets, misses, immediate_gets, wait_time | ||
| + | FROM v$latch_children | ||
| + | WHERE name='redo copy' ; | ||
NAME GETS MISSES IMMEDIATE_GETS WAIT_TIME | NAME GETS MISSES IMMEDIATE_GETS WAIT_TIME | ||
| 107번째 줄: | 82번째 줄: | ||
redo copy 6 0 0 0 | redo copy 6 0 0 0 | ||
redo copy 6 0 6707 0 | redo copy 6 0 6707 0 | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | * CPU 개수가 1개일 경우, 기본적으로 2개의 Redo Copy Latch가 조회됨 | ||
| + | * _log_simultaneous_copies 히든 파라미터를 이용해 개수 조정 가능. | ||
| + | * Latch의 개수를 늘리는 것이 무조건 성능에 좋은 것은 아니다. (예시_은행에 고객이 많이 몰릴 때 번호표 뽑는 기계를 많이 가져다 놓는 것은 의미가 없기 때문에) | ||
| + | * Latch 때문에 문제가 생기는 것인지 Redo Log Buffer나 File 자체에 문제가 있는지 확인 후 조치 필요 | ||
| − | + | ==== Redo Allocation Latch ==== | |
| + | * Redo Copy Latch를 확보한 서버 프로세스는 Redo Allocation Latch를 확보한다 | ||
| + | * Redo Allocation Latch는 1개만 존재 (Redo Copy Latch는 여러개 존재) | ||
| + | *: - 9i부터는 Redo Log Buffer를 여러개 공간으로 나누어서 각 공간별로 Redo Allocation Latch를 할당해주는 Shared Redo Strand 기능이 도입됨 | ||
| + | *:::: 즉, 하나의 Redo Log Buffer를 디스크의 파티션과 같이 여러 개로 나누어 여러 서버 프로세스가 동시에 작업하게 하여 성능을 높임 (LOG_PARALLELISM 파라미터 값으로 설정) | ||
| + | *: - Shared Rodo Strand 기능과 관련해 중요한 것은 Redo Log Buffer를 몇 개로 나누는가 인데 10g 부터는 LOG_PARALLELISM 파라미터가 _LOG_PARALLELISM 히든 파라미터로 변경되 이 값은 Oracle이 동적으로 관리하도록 _LOG_PARALLELIS_DYNAMIC 파라미터가 추가됨 | ||
| + | * _LOG_PARALLELISM_DYNAMIC 값이 True일 경우 Oracle이 해당 Strand 개수를 자동으로 제어 | ||
| + | *: - 이 파라미터에 대한 Oracle 권장 값은 CPU 개수 / 8 | ||
| − | + | ===== Redo Allocation Latch의 개수 조회 ===== | |
| − | + | <source lang=sql> | |
| − | + | SELECT COUNT(*) | |
| − | + | FROM V$latch_children | |
| − | + | WHERE NAME='redo allocation' ; | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
COUNT(*) | COUNT(*) | ||
------------ | ------------ | ||
28 | 28 | ||
| + | </source> | ||
| + | * 10g부터는 Shared Redo Strand 보다 더 확장된 개념인 Private Redo Strand 기능이 도입 | ||
| + | * 각 서버 프로세스가 Shared pool에 자신만의 독립적인 Privete Strand 공간을 만들어서 그곳에 Change Vector를 생성한 후 필요한 경우 LGWR이 Redo Log File에 바로 기록함 | ||
| + | *: Latch를 확보해서 Redo Log Buffer에 기록해야 하는 과정을 줄임으로써 성능 향상시킴. Zero Copy Redo 라고 부름. | ||
| + | ==== 온라인 Redo Log 파일 ==== | ||
| + | # Redo Log Buffer에 기록된 내용들(Redo Entry)은 특정 상황이 되면 LGWR 프로세스가 일부를 Online Redo Log File에 기록한 후 기록 된 Redo Entries들을 Redo Log Buffer에서 삭제(Flush) | ||
| + | # 어떤 Server Process가 특정 상황이 되면 Redo Writing Latch를 확보 한 후 LGWR에게 Redo Log Buffer에 있는 내용을 Redo Log File에 기록하라고 요청 | ||
| + | {{틀:고지상자 | ||
| + | |제목=온라인 리두로그에 기록되는 상황 - Log Switch | ||
| + | |내용= | ||
| + | * ⅰ) 3초 마다 | ||
| + | *:* LGWR 프로세스는 할 일이 없을 경우 Sleep 상태로 있다가 rdbms ipc message라는 대기이벤트의 time out이 되는 시점인 3초마다 Wake up을 해서 Redo Log Buffer에서 Redo Log File에 기록해야 할 내용이 있는지를 확인하여 기록 후 해당 내용을 삭제(Flush) | ||
| + | * ⅱ) Redo Log Buffer 전체 크기의 1/3이 찼거나 1M가 넘을 경우 | ||
| + | *:* 서버 프로세스는 Redo Log Buffer를 할당 받을 때 마다 현재 사용된 log buffer의 Block 수를 계산 | ||
| + | *:* 사용된 Log Buffer의 Block 수가 _LOG_IO_SIZE의 값보다 많을 경우 LGWR에게 기록을 요청 | ||
| + | *:* _LOG_IO_SIZE 파라미터는 Redo Log File로 내려 쓸 임계값을 지정하는 파라미터 | ||
| + | *:: ( 이 값을 512KB로 설정하면 변경사항이 512KB가 될 때 LGWR이 작동) | ||
| + | *:* 9i – Redo Log Buffer의 1/3 10g – 1/6 | ||
| + | * ⅲ) 사용자가 Commit 또는 Rollback을 수행할 때 | ||
| + | *:* 사용자가 Commit이나 Rollback을 수행하게 되면(즉, 트랜잭션을 종료하게 되면) 내부적 관리번호인 SCN이 생성되어 해당 트랜잭션에 할당되고 관리된다. | ||
| + | * ⅳ) DBWR이 LGWR에게 쓰기를 요청할 때 | ||
| + | *:* Oracle 8i부터는 DBWR이 LGWR의 on-disk RBA 값보다 큰 high-RBA 값을 가진 Block을 데이터 파일로 기록해야 할 때 해당 Block을 Differed Write Queue에 먼저 기록한 후 LGWR 프로세스를 먼저 수행시켜 해당 Redo Log를 먼저 내려쓰게 만든 후 Data Block을 기록하는 방식으로 Sync를 맞춘다. | ||
| + | }} | ||
| + | * LGWR이 Redo Log Buffer의 내용을 Redo Log File로 내려 쓸 때 Block 단위로 내려쓴다.(=DBWR) | ||
| + | * DBWR과는 달리 LGWR의 Block 크기는 OS_BLOCK_SIZE 크기에 따라 결정되며 OS에 따라 다를 수 있다. | ||
| + | *:(DBWR은 DB_BLOCK_SIZE에 따라 Block Size 결정) | ||
| − | + | ==== Redo Log Block Size 조회 ==== | |
| − | + | <source lang=sql> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
SQL> SELECT max(lebsz) FROM sys.x$kccle; | SQL> SELECT max(lebsz) FROM sys.x$kccle; | ||
| − | |||
| − | |||
MAX(LEBSZ) | MAX(LEBSZ) | ||
--------------- | --------------- | ||
512 | 512 | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | * 모든 변경사항이 Redo Log에 기록되는 것은 아님. | ||
| + | *: 예를 들어, Direct Load(SQL Loader, Insert /* APPEND */)나 Table, Index 생성시 NOLOGGING 옵션을 주는 경우 Redo Log에 기록되지 않는다. | ||
| − | + | * 단, NOLOGGING 옵션으로 테이블을 생성되었더라도 일반적인 Insert, Update, Delete는 Redo Log에 기록됨. | |
| − | + | === Redo Log File 구성 및 관리 === | |
| + | ==== Redo Log Buffer와 Redo Log File ==== | ||
| + | https://velog.velcdn.com/images/khyup0629/post/93b79e94-51c4-4cd7-aac9-f6d9d8590e63/image.png | ||
| − | + | # 데이터가 변경되면 데이터의 안전한 복구를 위해서 Redo Log Buffer에 먼저 기록한 후 실제 데이터를 변경 | |
| + | #: - Redo Log Buffer 에서 여러 가지 조건이 발생하게 되면 Redo Writing Latch를 획득한 Server Process가 LGWR에게 Redo Log Buffer의 내용을 Redo Log File로 기록 요청 | ||
| + | # LGWR이 내려쓴 내용은 Redo Log Buffer에서 지워 새로운 공간을 확보 | ||
| + | # Log Switch가 발생하게 되면 Checkpoint 신호가 발생 | ||
| + | #: - Log Switch : LGWR이 Redo Log Buffer에 내용을 Redo Log File에 내려 쓰다가 해당 파일이 가득 차게 되면 다음 그룹으로 자동으로 넘어가는 것 | ||
| + | # DBWR이 해당 로그 파일에 있는 내용 중 Buffer Cache에서 데이터파일로 저장되지 못한 변경사항들을 내려씀. | ||
| + | # 이 정보들을 데이터파일과 컨트롤 파일에 반영됨 | ||
| + | # Log Switch가 일어나는 그룹의 순서는 Oracle이 라운드로빈 방식으로 알아서 결정 | ||
| + | #: (=1번 그룹 다음에 2번 그룹이고 그 다음에 3번그룹이 아닐 수도 있다라는 의미) | ||
| − | + | ::* LGWR은 Redo Log File의 그룹에 멤버가 여러 개일 경우 같은 그룹안의 멤버들끼리는 서로 저장하고 있는 내용과 크기가 동일(병렬로 동시에 같은 내용 기록) | |
| + | ::*: 그러나 만약 같은 디스크에 있으면 직렬로 기록(=하나 기록하고 끝나면 다른 하나를 기록) | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | {{틀:고지상자2 | ||
| + | |제목 = 리두로그 그룹 과 멤버 (오라클 권장값) | ||
| + | |내용 = # Redo Log File은 그룹과 멤버라는 개념으로 관리 | ||
| + | # 같은 그룹일 경우 멤버들은 같은 내용을 담고 있어서 만약 하나의 멤버가 삭제되거나 장애가 발생해도 다른 멤버가 하나 더 존재하기 때문에 안전하게 관리할 수 있음 | ||
| + | # 멤버를 더 추가 할 수 있지만 기록시간이 늘어나기 때문에 부하를 줄 수 있음 | ||
| + | # 같은 그룹의 멤버는 절대 동일한 디스크에 함께 두는 것을 권장하지 않음 | ||
| + | # 오라클에서 최소 그릅의 개수는 2개이며 각 그룹별로 필요한 최소 멤버는 1개 | ||
| + | # 오라클 권장 구성 개수 : 최소 그룹 3개, 그룹별 최소 2개 이상의 멤버 | ||
| + | }} | ||
| + | {{틀:고지상자2 | ||
| + | |제목 = 리두로그 기록시 에러가 발생될 경우 | ||
| + | |내용 = # 병렬쓰기 도중에 Redo Log File이 삭제되거나 Block에 문제가 발생할 경우에는 LGWR은 각 오픈 로그 멤버의 상태를 조사해서 어떤 파일이 에러가 발생되는지 알아냄 | ||
| + | # 장애가 난 멤버는 Control File 안에 STALE 상태로 기록, LGWR은 백그라운드 Trace File에 ORA-00346 에러 기록 | ||
| + | #: - STALE 상태 : 해당 로그 파일이 문제가 있다는 것을 의미 | ||
| + | # LGWR이 하나의 로그 파일에서 4개 이상의 에러를 만나게 되면 로그 파일을 닫고 더 이상 그 파일에 내용을 기록하지 않음 | ||
| + | # 만약 LGWR이 어떤 로그파일에도 내용을 기록할 수 없다면 ORA-00340 에러를 발생시키고 Shutdown abort로 강제 종료되고 Startup 되지 않는다. | ||
| + | }} | ||
| − | + | {{틀:고지상자 | |
| − | + | |제목 = 리두로그 성능 개선/조치 사항 | |
| − | + | |내용 = # Redo Log File 크기는 각 서버의 실정에 맞게 사용해야 함(=권장 크기는 정해져 있지 않음) | |
| − | + | #: - 크기가 너무 작게 되면 Log Switch가 자주 발생 ⇒ 성능 저하 | |
| − | + | #: - 크기가 너무 크면 데이터의 손상 가능성이 커짐 | |
| − | + | # '''Alert Log File에 Checkpoint Not Completed.''' 라는 메시지가 나오면 멤버크기를 크게 만들거나 그룹을 더 만들어주어야 함. | |
| − | + | # '''Checkpoint Not Completed''' 라는 메시지는 Log Switch가 너무 빈번하게 일어날 경우 | |
| + | #: DBWR이 이전에 발생한 Checkpoint 내용을 Data File에 다 기록하지 못한 상태에서 다시 Log Switch 신호가 들어올 경우에 주로 발생함. | ||
| + | # 즉, Redo Log File의 크기가 작을 경우 잦은 Log Switch가 발생할 것이므로 이 메시지가 자주 보일 것이며, | ||
| + | #: 이럴 경우 Redo Log File의 크기나 Redo Log Group의 수를 증가시켜 주어야 한다. | ||
| + | }} | ||
| − | + | === Redo Log File 생성/삭제/관리 === | |
| − | + | ==== 신규 Group 생성 (신규 그룹 4번으로 지정) ==== | |
| − | + | <source lang=sql> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
SQL> alter database add logfile group 4 | SQL> alter database add logfile group 4 | ||
| − | + | '/app/oracle/oradata/testdb/redo04_a.log' size 5M ; | |
| − | + | </source> | |
| − | + | ==== Member 추가 ==== | |
| − | + | <source lang=sql> | |
SQL> alter database add logfile member | SQL> alter database add logfile member | ||
| − | + | '/app/oracle/oradata/testdb/redo04_b.log' to group 4 ; | |
| − | + | </source> | |
| − | + | ==== Member 삭제 ==== | |
| − | + | <source lang=sql> | |
SQL> alter database drop logfile member | SQL> alter database drop logfile member | ||
| − | + | '/app/oracle/oradata/testdb/redo04_b.log' ; | |
| − | + | </source> | |
| − | + | ==== Group 삭제 ==== | |
| − | + | <source lang=sql> | |
SQL> alter database drop logfile group 4; | SQL> alter database drop logfile group 4; | ||
| − | + | </source> | |
| − | + | ==== 강제로 Log Switch 발생시키기 ==== | |
| − | + | <source lang=sql> | |
SQL> alter system switch logfile; | SQL> alter system switch logfile; | ||
| − | + | </source> | |
| − | + | ==== 강제로 Checkpoint 발생 ==== | |
| + | <source lang=sql> | ||
SQL> alter system checkpoint; | SQL> alter system checkpoint; | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | * ASM이 아닌 일반 OS파일 시스템으로 Oracle을 설치하였다면 3, 4번에 있는 삭제 과정을 수행해도 실제 해당 파일은 지워지지 않음.(11G기준,ASM 기반에서는 지울 수 있음) | ||
| + | * 파일 시스템이 경우에 위 명령어들을 수행하고 난 뒤 반드시 DBA가 직접 OS 명령어로 해당 파일을 직접 지워야 함(11G기준,다른 그룹이나 멤버를 지우지 않도록 각별히 조심!) | ||
| − | + | * Redo Log File의 상태 : | |
| + | *: - CURRENT : 현재 LGWR이 내용을 기록하고 있는 상태 | ||
| + | *: - ACTIVE : Redo Log File의 내용이 아직 DB Buffer Cache에서 Data File로 저장 되지 않아 지워지면 안되는 상태 | ||
| + | *: - INACTIVE : Redo Log file의 내용이 데이터 파일에도 다 저장되어서 삭제되어도 되는 상태 | ||
| − | + | * DBA가 어떤 필요에 의해 Redo Log File을 삭제하고 싶다면 반드시 INACTIVE 상태로 만들고 3, 4번 명령어로 삭제 수행. | |
| + | * 주의 사항 : Redo Log File을 삭제할 때 절대 OS 명령어로 먼저 삭제하면 안됨!! | ||
| + | === Redo Log File 관리 실습 예제 === | ||
| + | ==== 현재 Redo Log 상태 확인하기 ==== | ||
| + | <source lang=sql> | ||
SQL> !vi log.sql | SQL> !vi log.sql | ||
| 470번째 줄: | 261번째 줄: | ||
SELECT a.group#, a.member, b.bytes/1024/1024 MB, b.sequence# "SEQ#", b.status, b.archived "ARC" | SELECT a.group#, a.member, b.bytes/1024/1024 MB, b.sequence# "SEQ#", b.status, b.archived "ARC" | ||
| − | FROM v$logfile a, v$log b | + | FROM v$logfile a, v$log b |
| − | WHERE a.group#=b.group# | + | WHERE a.group#=b.group# |
| − | ORDER BY 1,2 | + | ORDER BY 1,2 |
/ | / | ||
| − | |||
:wq | :wq | ||
| + | </source> | ||
| + | <source lang=sql> | ||
SQL> @log | SQL> @log | ||
| 484번째 줄: | 276번째 줄: | ||
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO | 2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO | ||
3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO | 3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO | ||
| + | </source> | ||
| − | + | ==== 신규 그룹(4번 그룹) / 멤버 추가 하기 ==== | |
| − | + | <source lang=sql> | |
| − | + | alter database add logfile group 4 | |
| − | + | '/app/oracle/oradata/testdb/redo04_a.log' size 5M ; | |
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | * RAC 환경(ASM) | ||
| + | : - RAC#1 | ||
| + | <source lang=sql> | ||
| + | ALTER DATABASE ADD LOGFILE THREAD 1 | ||
| + | GROUP 1 ('+REDO/db_name/redo__t1_01a.log','+REDO/db_name/redo__t1_01b.log') SIZE 100m, | ||
| + | GROUP 2 ('+REDO/db_name/redo__t1_02a.log','+REDO/db_name/redo__t1_02b.log') SIZE 100m, | ||
| + | GROUP 3 ('+REDO/db_name/redo__t1_03a.log','+REDO/db_name/redo__t1_03b.log') SIZE 100m, | ||
| + | GROUP 4 ('+REDO/db_name/redo__t1_04a.log','+REDO/db_name/redo__t1_04b.log') SIZE 100m; | ||
| + | </source> | ||
| + | : - RAC#2 | ||
| + | <source lang=sql> | ||
| + | ALTER DATABASE ADD LOGFILE THREAD 2 | ||
| + | GROUP 5 ('+REDO/db_name/redo__t2_5a.log','+REDO/db_name/redo__t2_5b.log') SIZE 100m, | ||
| + | GROUP 6 ('+REDO/db_name/redo__t2_6a.log','+REDO/db_name/redo__t2_6b.log') SIZE 100m, | ||
| + | GROUP 7 ('+REDO/db_name/redo__t2_7a.log','+REDO/db_name/redo__t2_7b.log') SIZE 100m, | ||
| + | GROUP 8 ('+REDO/db_name/redo__t2_8a.log','+REDO/db_name/redo__t2_8b.log') SIZE 100m; | ||
| + | </source> | ||
| − | + | <source lang=sql> | |
| + | SQL> @log | ||
GROUP# MEMBER MB SEQ# STATUS ARC | GROUP# MEMBER MB SEQ# STATUS ARC | ||
-------- ------------------------------------------------------- ---- ---- ----------- ----- | -------- ------------------------------------------------------- ---- ---- ----------- ----- | ||
| 512번째 줄: | 310번째 줄: | ||
3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO | 3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YES | 4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YES | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
| − | |||
SQL> alter database add logfile member | SQL> alter database add logfile member | ||
2 '/app/oracle/oradata/testdb/redo04_b.log' to group 4 ; | 2 '/app/oracle/oradata/testdb/redo04_b.log' to group 4 ; | ||
| − | |||
| − | |||
| − | |||
Database altered. | Database altered. | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| + | <source lang=sql> | ||
| + | SQL> @log | ||
GROUP# MEMBER MB SEQ# STATUS ARC | GROUP# MEMBER MB SEQ# STATUS ARC | ||
| 536번째 줄: | 328번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YES | 4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YES | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 0 UNUSED YES | 4 /app/oracle/oradata/testdb/redo04_b.log 5 0 UNUSED YES | ||
| + | </source> | ||
| − | + | <source lang=sql> | |
| − | |||
| − | |||
SQL> alter system switch logfile; | SQL> alter system switch logfile; | ||
| − | |||
| − | |||
| − | |||
System altered. | System altered. | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| + | <source lang=sql> | ||
| + | SQL> @log | ||
GROUP# MEMBER MB SEQ# STATUS ARC | GROUP# MEMBER MB SEQ# STATUS ARC | ||
| 559번째 줄: | 345번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> alter system checkpoint; | SQL> alter system checkpoint; | ||
| − | |||
| − | |||
System altered. | System altered. | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> @log | SQL> @log | ||
| 579번째 줄: | 363번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
※ Alter system checkpoint 명령어로 3번 그룹이 Active → Inactive로 변경됨 | ※ Alter system checkpoint 명령어로 3번 그룹이 Active → Inactive로 변경됨 | ||
| − | + | ==== 기존 멤버 삭제 / 그룹 삭제 하기 (4번 그룹 삭제) ==== | |
| − | + | <source lang=sql> | |
| − | |||
| − | |||
| − | |||
SQL> @log | SQL> @log | ||
| − | |||
| − | |||
GROUP# MEMBER MB SEQ# STATUS ARC | GROUP# MEMBER MB SEQ# STATUS ARC | ||
| 602번째 줄: | 378번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | 4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | <source lang=sql> | ||
| + | alter system switch logfile; | ||
System altered. | System altered. | ||
| + | </source> | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <source lang=sql> | |
| + | select a.group#,b.thread# | ||
| + | , a.member, b.bytes/1024/1024 MB, b.archived, b.status | ||
| + | from v$logfile a, v$log b | ||
| + | where a.group#=b.group# | ||
| + | order by 1,2 ; | ||
GROUP# MEMBER MB ARC STATUS | GROUP# MEMBER MB ARC STATUS | ||
| 629번째 줄: | 401번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO ACTIVE | 4 /app/oracle/oradata/testdb/redo04_a.log 5 NO ACTIVE | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 NO ACTIVE | 4 /app/oracle/oradata/testdb/redo04_b.log 5 NO ACTIVE | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> alter system checkpoint; | SQL> alter system checkpoint; | ||
| − | |||
| − | |||
System altered. | System altered. | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
| − | + | select a.group#,b.thread#, a.member, b.bytes/1024/1024 MB, b.archived, b.status | |
| − | + | from v$logfile a, v$log b | |
| − | + | where a.group#=b.group# | |
| − | + | order by 1,2 ; | |
| − | |||
GROUP# MEMBER MB ARC STATUS | GROUP# MEMBER MB ARC STATUS | ||
| 654번째 줄: | 423번째 줄: | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE | 4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE | ||
4 /app/oracle/oradata/testdb/redo04_b.log 5 NO INACTIVE | 4 /app/oracle/oradata/testdb/redo04_b.log 5 NO INACTIVE | ||
| + | </source> | ||
| − | + | * 그룹삭제 | |
| + | <source lang=sql> | ||
| + | SQL> Alter database drop logfile group 1; | ||
| + | </source> | ||
| − | + | * 멤버 삭제 | |
| + | <source lang=sql> | ||
| + | SQL> alter database drop logfile member '/app/oracle/oradata/testdb/redo04_b.log' ; | ||
| + | Database altered. | ||
| + | </source> | ||
| − | + | * ASM환경에서 그룹 삭제 | |
| + | <source lang=sql> | ||
| + | $ sqlplus " /as sysasm" | ||
| − | + | SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo02a.log'; | |
| + | SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo01a.log'; | ||
| + | SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo03a.log'; | ||
| + | SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo04a.log'; | ||
| + | </source> | ||
| − | + | <source lang=sql> | |
| + | SQL> Alter database drop logfile group 1; | ||
| − | + | <source lang=sql> | |
SQL> !ls /app/oracle/oradata/testdb/redo04_b.log | SQL> !ls /app/oracle/oradata/testdb/redo04_b.log | ||
/app/oracle/oradata/testdb/redo04_b.log ← 여전히 파일이 남아 있음 | /app/oracle/oradata/testdb/redo04_b.log ← 여전히 파일이 남아 있음 | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> !rm –rf /app/oracle/oradata/testdb/redo04_b.log ← 수동으로 삭제 | SQL> !rm –rf /app/oracle/oradata/testdb/redo04_b.log ← 수동으로 삭제 | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> !ls /app/oracle/oradata/testdb/redo04_b.log | SQL> !ls /app/oracle/oradata/testdb/redo04_b.log | ||
ls: /app/oracle/oradata/testdb/redo04_b.log: No such file or directory | ls: /app/oracle/oradata/testdb/redo04_b.log: No such file or directory | ||
| − | + | </source> | |
| − | |||
| − | + | <source lang=sql> | |
SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status | SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status | ||
2 from v$logfile a, v$log b | 2 from v$logfile a, v$log b | ||
| 696번째 줄: | 479번째 줄: | ||
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE | 3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE | ||
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE | 4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE | ||
| − | + | </source> | |
| − | |||
| − | + | <source lang=sql> | |
SQL> alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log' ; | SQL> alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log' ; | ||
alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log' | alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log' | ||
| 706번째 줄: | 488번째 줄: | ||
ERROR at line 1: | ERROR at line 1: | ||
ORA-00361: cannot remove last log member /app/oracle/oradata/testdb/redo04_a.log for group 4 | ORA-00361: cannot remove last log member /app/oracle/oradata/testdb/redo04_a.log for group 4 | ||
| − | + | </source> | |
| − | |||
← 그룹에 member가 1개일 경우 member는 삭제가 안되며 그룹을 지워야 한다. | ← 그룹에 member가 1개일 경우 member는 삭제가 안되며 그룹을 지워야 한다. | ||
| − | + | <source lang=sql> | |
| − | |||
| − | |||
| − | |||
SQL> alter database drop logfile group 4; | SQL> alter database drop logfile group 4; | ||
| − | |||
| − | |||
| − | |||
Database altered. | Database altered. | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status | SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status | ||
2 from v$logfile a, v$log b | 2 from v$logfile a, v$log b | ||
3 where a.group#=b.group# | 3 where a.group#=b.group# | ||
4 order by 1,2 ; | 4 order by 1,2 ; | ||
| − | |||
| − | |||
GROUP# MEMBER MB ARC STATUS | GROUP# MEMBER MB ARC STATUS | ||
| 735번째 줄: | 508번째 줄: | ||
2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE | 2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE | ||
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE | 3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> !ls /app/oracle/oradata/testdb/redo04_a.log | SQL> !ls /app/oracle/oradata/testdb/redo04_a.log | ||
/app/oracle/oradata/testdb/redo04_a.log ← 여전히 파일이 남아 있음 | /app/oracle/oradata/testdb/redo04_a.log ← 여전히 파일이 남아 있음 | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> !rm –rf /app/oracle/oradata/testdb/redo04_a.log ← 수동으로 삭제 | SQL> !rm –rf /app/oracle/oradata/testdb/redo04_a.log ← 수동으로 삭제 | ||
| − | + | </source> | |
| − | + | <source lang=sql> | |
SQL> !ls /app/oracle/oradata/testdb/redo04_a.log | SQL> !ls /app/oracle/oradata/testdb/redo04_a.log | ||
ls: /app/oracle/oradata/testdb/redo04_a.log: No such file or directory | ls: /app/oracle/oradata/testdb/redo04_a.log: No such file or directory | ||
| − | + | </source> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | {{:REDO Waiting Event (리두 대기 이벤트)}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | [[Category:oracle]] | |
2024년 6월 16일 (일) 21:37 기준 최신판
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 REDO[편집]
1.1 Redo 로그의 목적[편집]
- 데이터 베이스 복구
- : 물리적인 디스크 장애시 복구, 미디어 복구(Media Recovery) 라고 함
- 캐시 복구
- : 버퍼캐시에 있는 데이터가 디스크의 데이터 블럭에 기록되기 전 장애가 발생한 경우 복구, 인스턴스 복구(Instance Recovery) 라고 함.
- FAST COMMIT
- : 트랜잭션 발생시 변경사항을 Append 방식으로 순차적으로 빠르게 로그파일에 기록하고 메모리 데이터 블럭과 디스크 데이터 파일간 동기화를 통해서 배치방식으로 일괄 수행함.
- 'Delayed 블럭 클린아웃' 방식을 이용하여 트랜잭션이 발생된 전체건이 끝나기를 기다리지 않고 우선 처리 한후 나중에 일괄 수행되는 방식.
- : 트랜잭션 발생시 변경사항을 Append 방식으로 순차적으로 빠르게 로그파일에 기록하고 메모리 데이터 블럭과 디스크 데이터 파일간 동기화를 통해서 배치방식으로 일괄 수행함.
1.2 온라인 Redo 로그 와 아카이빙 Redo 로그[편집]
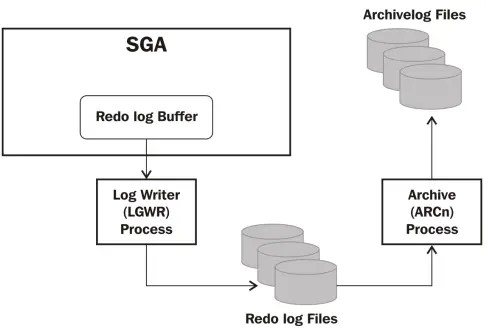
1.2.1 온라인 Redo 로그[편집]
- 온라인 리두 로그는 리두로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일
- 최소 2개 파일로 구성됨
- 현재 사용중인 로그파일이 가득 차면 다른 리두로그파일로 로그 스위칭이 발생함
- 모든 리두로그 파일이 가득 차면 처음 리두로그파일 부터 다시 재사용됨
1.2.2 아카이빙 Redo 로그[편집]
- 온라인 리두로그가 재사용되기 전에 지정된 아키이빙 로그 디렉토리에 백업 하는 파일
1.3 Redo Log의 생성 원리[편집]
- Oracle에서 데이터의 변경(DDL, DML, TCL등)이 발생했다면 두 매커니즘에 의해 Rodo Log에 기록됨
1.3.1 Write Log Ahead[편집]
- 실제 데이터를 변경하기 전에 Redo Log에 먼저 기록한 후 데이터를 변경
- (DBWR이 작동하기 전에 LGWR이 작동하는 것도 이것과 같은 의미)
- LGWR(Log Writer)가 리두로그 버퍼를 리두로그 파일로 저장하는 시점
- 3초마다 DBWR 프로세스가 준 신호를 받아서 저장
- 로그 버퍼량이 3분의 1이 차거나 , 로그버퍼량이 1MB이상 일때
- commit 이나 rollback이 실행될때
1.3.2 Log force at Commit[편집]
- 사용자로부터 Commit 요청이 들어오면 관련된 모든 Redo Record들은 Redo Log file에 저장한 후 Commit을 완료.
- (Redo Log File에 기록하지 않고는 Commit을 완료하지 않는다)
- 대량의 데이터 변경 후 Commit이 한꺼번에 수행되면 Delayed Commit(지연된 커밋), Group Commit 발생
- - Group Commit : Commit을 아주 짧은 시간 동안 모아서 한꺼번에 수행하는 기술
- - 짧은 시간동안 많은 데이터가 변경된 후 한꺼번에 Commit 요청이 들어올 경우 발생
1.3.3 Redo log가 생성되고 기록되는 원리[편집]
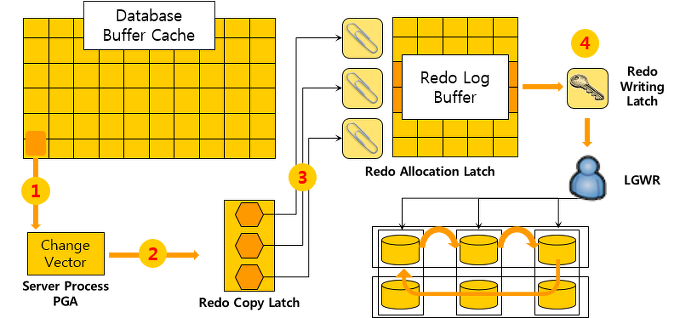
1.3.3.1 Redo Log 기록 원리[편집]
- 사용자가 특정 데이터를 변경하는 쿼리 수행 시에 해당 SQL을 받은 서버 프로세스는 원하는 Block이 Database Buffer Cache에 있는지 확인
- 확인 후 없으면 해당 블록을 데이터 파일에서 찾아서 복사한 후 Buffer Cache로 가져옴.
- 해당 row부분을 다른 사용자가 바꿀 수 없도록 Lock를 설정(page fix) 후 PGA에 Redo Change Vector를 생성함.
- 체인지 벡터(Change Vector) : Redo Log에 기록할 변경된 데이터에 대한 모든 정보의 세트(복구를 위한 상세한 설명서)
- Redo Log는 Commit된 데이터를 복구할 때도 사용 되지만 Rollback 데이터를 복구할 때도 사용.
- 사용자가 커밋(commit)을 수행하고 Checkpoint 발생 전에 DB가 강제 종료 되었다면 해당 데이터를 Roll Forwared 하는 내용도 저장해야 하지만 사용자가 Rollback한 후 아직 Rollback이 완전히 완료되지 않은 상태에서 DB가 강제 종료 되었을 경우에도 Rollback 되지 못한 데이터 전부를 Rollback 해줘야 한다.
- 그래서, Change Vector내에 Undo 관련 내용까지 함께 저장된다.
- PGA에 만들어진 Change Vector는 Redo Record Format으로 Row단위로 Redo Log Buffer에 복사됨
- (PGA에서 Change Vector 생성 후 ) Redo Log Buffer에서 필요한 용량을 계산, Latch 획득 (Change Vector를 Redo Log Buffer에 복사하기 위함)
- Latch(래치) : 한정된 메모리 자원을 여러 사용자가 사용할 때 사용할 수 있는 순서를 정해주는 역할
- Rodo Log Buffer에 내용을 쓰려면 두 가지 Latch를 확보해야 한다.
- 1) Redo Copy Latch
- - Redo Copy Latch : Change Vector가 모두 Redo Log Buffer에 기록될 때가지 계속 가지고 있어야 하기 때문에 여러개의 Latch가 존재한다.
- 2) Redo Allocation Latch
1.3.4 Redo Copy Latch 현황 조회[편집]
SELECT name, gets, misses, immediate_gets, wait_time
FROM v$latch_children
WHERE name='redo copy' ;
NAME GETS MISSES IMMEDIATE_GETS WAIT_TIME
--------------- ------------ ------------ --------------------- ------------
redo copy 6 0 0 0
redo copy 6 0 6707 0- CPU 개수가 1개일 경우, 기본적으로 2개의 Redo Copy Latch가 조회됨
- _log_simultaneous_copies 히든 파라미터를 이용해 개수 조정 가능.
- Latch의 개수를 늘리는 것이 무조건 성능에 좋은 것은 아니다. (예시_은행에 고객이 많이 몰릴 때 번호표 뽑는 기계를 많이 가져다 놓는 것은 의미가 없기 때문에)
- Latch 때문에 문제가 생기는 것인지 Redo Log Buffer나 File 자체에 문제가 있는지 확인 후 조치 필요
1.3.5 Redo Allocation Latch[편집]
- Redo Copy Latch를 확보한 서버 프로세스는 Redo Allocation Latch를 확보한다
- Redo Allocation Latch는 1개만 존재 (Redo Copy Latch는 여러개 존재)
- - 9i부터는 Redo Log Buffer를 여러개 공간으로 나누어서 각 공간별로 Redo Allocation Latch를 할당해주는 Shared Redo Strand 기능이 도입됨
- 즉, 하나의 Redo Log Buffer를 디스크의 파티션과 같이 여러 개로 나누어 여러 서버 프로세스가 동시에 작업하게 하여 성능을 높임 (LOG_PARALLELISM 파라미터 값으로 설정)
- - Shared Rodo Strand 기능과 관련해 중요한 것은 Redo Log Buffer를 몇 개로 나누는가 인데 10g 부터는 LOG_PARALLELISM 파라미터가 _LOG_PARALLELISM 히든 파라미터로 변경되 이 값은 Oracle이 동적으로 관리하도록 _LOG_PARALLELIS_DYNAMIC 파라미터가 추가됨
- - 9i부터는 Redo Log Buffer를 여러개 공간으로 나누어서 각 공간별로 Redo Allocation Latch를 할당해주는 Shared Redo Strand 기능이 도입됨
- _LOG_PARALLELISM_DYNAMIC 값이 True일 경우 Oracle이 해당 Strand 개수를 자동으로 제어
- - 이 파라미터에 대한 Oracle 권장 값은 CPU 개수 / 8
1.3.5.1 Redo Allocation Latch의 개수 조회[편집]
SELECT COUNT(*)
FROM V$latch_children
WHERE NAME='redo allocation' ;
COUNT(*)
------------
28- 10g부터는 Shared Redo Strand 보다 더 확장된 개념인 Private Redo Strand 기능이 도입
- 각 서버 프로세스가 Shared pool에 자신만의 독립적인 Privete Strand 공간을 만들어서 그곳에 Change Vector를 생성한 후 필요한 경우 LGWR이 Redo Log File에 바로 기록함
- Latch를 확보해서 Redo Log Buffer에 기록해야 하는 과정을 줄임으로써 성능 향상시킴. Zero Copy Redo 라고 부름.
1.3.6 온라인 Redo Log 파일[편집]
- Redo Log Buffer에 기록된 내용들(Redo Entry)은 특정 상황이 되면 LGWR 프로세스가 일부를 Online Redo Log File에 기록한 후 기록 된 Redo Entries들을 Redo Log Buffer에서 삭제(Flush)
- 어떤 Server Process가 특정 상황이 되면 Redo Writing Latch를 확보 한 후 LGWR에게 Redo Log Buffer에 있는 내용을 Redo Log File에 기록하라고 요청
- LGWR이 Redo Log Buffer의 내용을 Redo Log File로 내려 쓸 때 Block 단위로 내려쓴다.(=DBWR)
- DBWR과는 달리 LGWR의 Block 크기는 OS_BLOCK_SIZE 크기에 따라 결정되며 OS에 따라 다를 수 있다.
- (DBWR은 DB_BLOCK_SIZE에 따라 Block Size 결정)
1.3.7 Redo Log Block Size 조회[편집]
SQL> SELECT max(lebsz) FROM sys.x$kccle;
MAX(LEBSZ)
---------------
512- 모든 변경사항이 Redo Log에 기록되는 것은 아님.
- 예를 들어, Direct Load(SQL Loader, Insert /* APPEND */)나 Table, Index 생성시 NOLOGGING 옵션을 주는 경우 Redo Log에 기록되지 않는다.
- 단, NOLOGGING 옵션으로 테이블을 생성되었더라도 일반적인 Insert, Update, Delete는 Redo Log에 기록됨.
1.4 Redo Log File 구성 및 관리[편집]
1.4.1 Redo Log Buffer와 Redo Log File[편집]
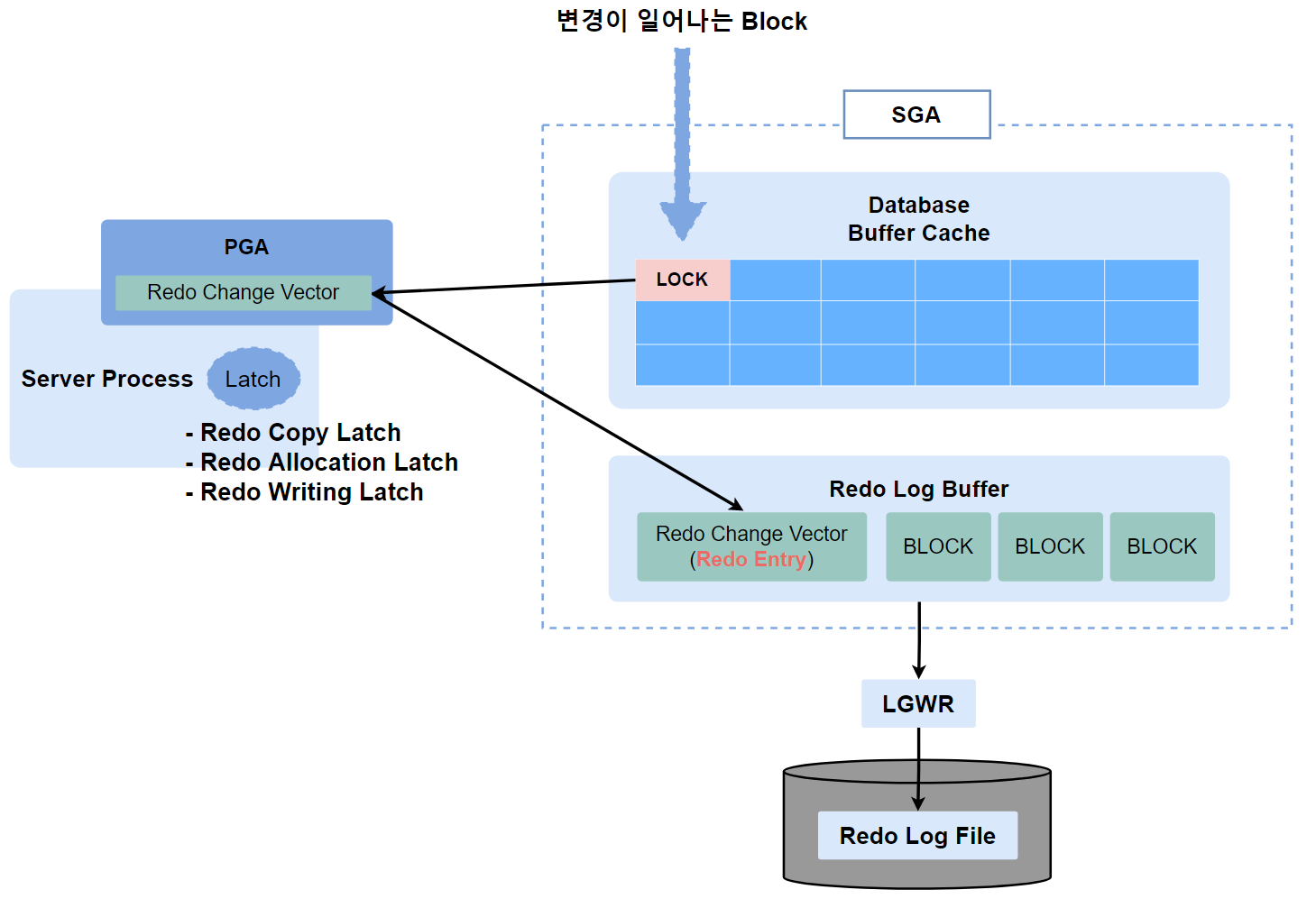
- 데이터가 변경되면 데이터의 안전한 복구를 위해서 Redo Log Buffer에 먼저 기록한 후 실제 데이터를 변경
- - Redo Log Buffer 에서 여러 가지 조건이 발생하게 되면 Redo Writing Latch를 획득한 Server Process가 LGWR에게 Redo Log Buffer의 내용을 Redo Log File로 기록 요청
- LGWR이 내려쓴 내용은 Redo Log Buffer에서 지워 새로운 공간을 확보
- Log Switch가 발생하게 되면 Checkpoint 신호가 발생
- - Log Switch : LGWR이 Redo Log Buffer에 내용을 Redo Log File에 내려 쓰다가 해당 파일이 가득 차게 되면 다음 그룹으로 자동으로 넘어가는 것
- DBWR이 해당 로그 파일에 있는 내용 중 Buffer Cache에서 데이터파일로 저장되지 못한 변경사항들을 내려씀.
- 이 정보들을 데이터파일과 컨트롤 파일에 반영됨
- Log Switch가 일어나는 그룹의 순서는 Oracle이 라운드로빈 방식으로 알아서 결정
- (=1번 그룹 다음에 2번 그룹이고 그 다음에 3번그룹이 아닐 수도 있다라는 의미)
- LGWR은 Redo Log File의 그룹에 멤버가 여러 개일 경우 같은 그룹안의 멤버들끼리는 서로 저장하고 있는 내용과 크기가 동일(병렬로 동시에 같은 내용 기록)
- 그러나 만약 같은 디스크에 있으면 직렬로 기록(=하나 기록하고 끝나면 다른 하나를 기록)
- LGWR은 Redo Log File의 그룹에 멤버가 여러 개일 경우 같은 그룹안의 멤버들끼리는 서로 저장하고 있는 내용과 크기가 동일(병렬로 동시에 같은 내용 기록)
notifications_active 리두로그 그룹 과 멤버 (오라클 권장값)
- Redo Log File은 그룹과 멤버라는 개념으로 관리
- 같은 그룹일 경우 멤버들은 같은 내용을 담고 있어서 만약 하나의 멤버가 삭제되거나 장애가 발생해도 다른 멤버가 하나 더 존재하기 때문에 안전하게 관리할 수 있음
- 멤버를 더 추가 할 수 있지만 기록시간이 늘어나기 때문에 부하를 줄 수 있음
- 같은 그룹의 멤버는 절대 동일한 디스크에 함께 두는 것을 권장하지 않음
- 오라클에서 최소 그릅의 개수는 2개이며 각 그룹별로 필요한 최소 멤버는 1개
- 오라클 권장 구성 개수 : 최소 그룹 3개, 그룹별 최소 2개 이상의 멤버
notifications_active 리두로그 기록시 에러가 발생될 경우
- 병렬쓰기 도중에 Redo Log File이 삭제되거나 Block에 문제가 발생할 경우에는 LGWR은 각 오픈 로그 멤버의 상태를 조사해서 어떤 파일이 에러가 발생되는지 알아냄
- 장애가 난 멤버는 Control File 안에 STALE 상태로 기록, LGWR은 백그라운드 Trace File에 ORA-00346 에러 기록
- - STALE 상태 : 해당 로그 파일이 문제가 있다는 것을 의미
- LGWR이 하나의 로그 파일에서 4개 이상의 에러를 만나게 되면 로그 파일을 닫고 더 이상 그 파일에 내용을 기록하지 않음
- 만약 LGWR이 어떤 로그파일에도 내용을 기록할 수 없다면 ORA-00340 에러를 발생시키고 Shutdown abort로 강제 종료되고 Startup 되지 않는다.
1.5 Redo Log File 생성/삭제/관리[편집]
1.5.1 신규 Group 생성 (신규 그룹 4번으로 지정)[편집]
SQL> alter database add logfile group 4
'/app/oracle/oradata/testdb/redo04_a.log' size 5M ;1.5.2 Member 추가[편집]
SQL> alter database add logfile member
'/app/oracle/oradata/testdb/redo04_b.log' to group 4 ;1.5.3 Member 삭제[편집]
SQL> alter database drop logfile member
'/app/oracle/oradata/testdb/redo04_b.log' ;1.5.4 Group 삭제[편집]
SQL> alter database drop logfile group 4;1.5.6 강제로 Checkpoint 발생[편집]
SQL> alter system checkpoint;- ASM이 아닌 일반 OS파일 시스템으로 Oracle을 설치하였다면 3, 4번에 있는 삭제 과정을 수행해도 실제 해당 파일은 지워지지 않음.(11G기준,ASM 기반에서는 지울 수 있음)
- 파일 시스템이 경우에 위 명령어들을 수행하고 난 뒤 반드시 DBA가 직접 OS 명령어로 해당 파일을 직접 지워야 함(11G기준,다른 그룹이나 멤버를 지우지 않도록 각별히 조심!)
- Redo Log File의 상태 :
- - CURRENT : 현재 LGWR이 내용을 기록하고 있는 상태
- - ACTIVE : Redo Log File의 내용이 아직 DB Buffer Cache에서 Data File로 저장 되지 않아 지워지면 안되는 상태
- - INACTIVE : Redo Log file의 내용이 데이터 파일에도 다 저장되어서 삭제되어도 되는 상태
- DBA가 어떤 필요에 의해 Redo Log File을 삭제하고 싶다면 반드시 INACTIVE 상태로 만들고 3, 4번 명령어로 삭제 수행.
- 주의 사항 : Redo Log File을 삭제할 때 절대 OS 명령어로 먼저 삭제하면 안됨!!
1.6 Redo Log File 관리 실습 예제[편집]
1.6.1 현재 Redo Log 상태 확인하기[편집]
SQL> !vi log.sql
set line 200
col group# for 999
col mb for 999
col member for a45
col seq# for 999
col status for a8
col arc for a5
SELECT a.group#, a.member, b.bytes/1024/1024 MB, b.sequence# "SEQ#", b.status, b.archived "ARC"
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1,2
/
:wqSQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO1.6.2 신규 그룹(4번 그룹) / 멤버 추가 하기[편집]
alter database add logfile group 4
'/app/oracle/oradata/testdb/redo04_a.log' size 5M ;- RAC 환경(ASM)
- - RAC#1
ALTER DATABASE ADD LOGFILE THREAD 1
GROUP 1 ('+REDO/db_name/redo__t1_01a.log','+REDO/db_name/redo__t1_01b.log') SIZE 100m,
GROUP 2 ('+REDO/db_name/redo__t1_02a.log','+REDO/db_name/redo__t1_02b.log') SIZE 100m,
GROUP 3 ('+REDO/db_name/redo__t1_03a.log','+REDO/db_name/redo__t1_03b.log') SIZE 100m,
GROUP 4 ('+REDO/db_name/redo__t1_04a.log','+REDO/db_name/redo__t1_04b.log') SIZE 100m;- - RAC#2
ALTER DATABASE ADD LOGFILE THREAD 2
GROUP 5 ('+REDO/db_name/redo__t2_5a.log','+REDO/db_name/redo__t2_5b.log') SIZE 100m,
GROUP 6 ('+REDO/db_name/redo__t2_6a.log','+REDO/db_name/redo__t2_6b.log') SIZE 100m,
GROUP 7 ('+REDO/db_name/redo__t2_7a.log','+REDO/db_name/redo__t2_7b.log') SIZE 100m,
GROUP 8 ('+REDO/db_name/redo__t2_8a.log','+REDO/db_name/redo__t2_8b.log') SIZE 100m;SQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO
4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YESSQL> alter database add logfile member
2 '/app/oracle/oradata/testdb/redo04_b.log' to group 4 ;
Database altered.SQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 CURRENT NO
4 /app/oracle/oradata/testdb/redo04_a.log 5 0 UNUSED YES
4 /app/oracle/oradata/testdb/redo04_b.log 5 0 UNUSED YESSQL> alter system switch logfile;
System altered.SQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 ACTIVE NO
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NOSQL> alter system checkpoint;
System altered.SQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 INACTIVE NO
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO※ Alter system checkpoint 명령어로 3번 그룹이 Active → Inactive로 변경됨
1.6.3 기존 멤버 삭제 / 그룹 삭제 하기 (4번 그룹 삭제)[편집]
SQL> @log
GROUP# MEMBER MB SEQ# STATUS ARC
-------- ------------------------------------------------------- ---- ---- ----------- -----
1 /app/oracle/oradata/testdb/redo01.log 50 31 INACTIVE NO
2 /app/oracle/oradata/testdb/redo02.log 50 32 INACTIVE NO
3 /app/oracle/oradata/testdb/redo03.log 50 33 INACTIVE NO
4 /app/oracle/oradata/testdb/redo04_a.log 5 34 CURRENT NO
4 /app/oracle/oradata/testdb/redo04_b.log 5 34 CURRENT NO
alter system switch logfile;
System altered.
select a.group#,b.thread#
, a.member, b.bytes/1024/1024 MB, b.archived, b.status
from v$logfile a, v$log b
where a.group#=b.group#
order by 1,2 ;
GROUP# MEMBER MB ARC STATUS
-------- ------------------------------------------------------- ---- ---- ------------
1 /app/oracle/oradata/testdb/redo01.log 50 NO CURRENT
2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO ACTIVE
4 /app/oracle/oradata/testdb/redo04_b.log 5 NO ACTIVE
SQL> alter system checkpoint;
System altered.select a.group#,b.thread#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
from v$logfile a, v$log b
where a.group#=b.group#
order by 1,2 ;
GROUP# MEMBER MB ARC STATUS
-------- ------------------------------------------------------- ---- ---- ------------
1 /app/oracle/oradata/testdb/redo01.log 50 NO CURRENT
2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE
4 /app/oracle/oradata/testdb/redo04_b.log 5 NO INACTIVE- 그룹삭제
SQL> Alter database drop logfile group 1;- 멤버 삭제
SQL> alter database drop logfile member '/app/oracle/oradata/testdb/redo04_b.log' ;
Database altered.- ASM환경에서 그룹 삭제
$ sqlplus " /as sysasm"
SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo02a.log';
SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo01a.log';
SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo03a.log';
SQL> ALTER DISKGROUP REDO DROP FILE '+REDO/db_name/redo04a.log';SQL> Alter database drop logfile group 1;
<source lang=sql>
SQL> !ls /app/oracle/oradata/testdb/redo04_b.log
/app/oracle/oradata/testdb/redo04_b.log ← 여전히 파일이 남아 있음SQL> !rm –rf /app/oracle/oradata/testdb/redo04_b.log ← 수동으로 삭제SQL> !ls /app/oracle/oradata/testdb/redo04_b.log
ls: /app/oracle/oradata/testdb/redo04_b.log: No such file or directory
SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
2 from v$logfile a, v$log b
3 where a.group#=b.group#
4 order by 1,2 ;
GROUP# MEMBER MB ARC STATUS
-------- ------------------------------------------------------- ---- ---- ------------
1 /app/oracle/oradata/testdb/redo01.log 50 NO CURRENT
2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVE
4 /app/oracle/oradata/testdb/redo04_a.log 5 NO INACTIVE
SQL> alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log' ;
alter database drop logfile member '/app/oracle/oradata/testdb/redo04_a.log'
*
ERROR at line 1:
ORA-00361: cannot remove last log member /app/oracle/oradata/testdb/redo04_a.log for group 4← 그룹에 member가 1개일 경우 member는 삭제가 안되며 그룹을 지워야 한다.
SQL> alter database drop logfile group 4;
Database altered.SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
2 from v$logfile a, v$log b
3 where a.group#=b.group#
4 order by 1,2 ;
GROUP# MEMBER MB ARC STATUS
------ --------------------------------------------- ---- --- --------
1 /app/oracle/oradata/testdb/redo01.log 50 NO CURRENT
2 /app/oracle/oradata/testdb/redo02.log 50 NO INACTIVE
3 /app/oracle/oradata/testdb/redo03.log 50 NO INACTIVESQL> !ls /app/oracle/oradata/testdb/redo04_a.log
/app/oracle/oradata/testdb/redo04_a.log ← 여전히 파일이 남아 있음SQL> !rm –rf /app/oracle/oradata/testdb/redo04_a.log ← 수동으로 삭제SQL> !ls /app/oracle/oradata/testdb/redo04_a.log
ls: /app/oracle/oradata/testdb/redo04_a.log: No such file or directory
2 리두(Redo) 대기 이벤트[편집]
- latch: redo writing
- latch: redo allocation
- latch: redo copy
2.1 redo writing 래치[편집]
- redo 버퍼내의 공간을 확보하기 위해 LGWR에게 쓰기 요청을 하려는 프로세스는 redo writing 래치를 획득해야함
- LGWR에 의한 쓰기 작업은 동시에 수행될 수 없으므로 전체 인스턴스에 하나만 존재 함.
- redo writing 래치는 Willing-to-wait 모드로 획득 됨
- redo writing 래치를 획득하는 과정에서 경합이 발생하면 latch: redo writing 이벤트를 대기 함
2.2 redo copy 래치[편집]
- PGA내의 체인지 벡터를 리두 버퍼로 복사하려는 프로세스는 작업의 전체과정 동안 redo copy 래치를 보유해야 한다.
- redo copy 래치는 기본적으로 No-wait 모드로 획득
- 만일 프로세스가 redo copy 래치를 획득하는데 실패하면 연속적으로 다음 redo copy 래치를 획득하기 위해 시도한 후 마지막 redo copy 래치를 획득하는 과정에서는 Willing-to-wait 모드가 사용 됨
- redo copy 래치를 획득하는 과정에서 경합이 발생하면 latch: redo copy 이벤트를 대기
2.3 redo allocation 래치[편집]
- 체인지 벡터를 리두 버퍼에 복사하기 위해 리두 버퍼 내에 공간을 확보 하는 과정에서 redo allocation 래치를 획득해야 함
- 전체 리두 버퍼를 복수개의 Redo strands라는 공간으로 분할해서 사용할 수 있으며, 하나의 redo allocation 래치가 하나의 redo strand를 관리
- 복수개의 redo allocation 래치를 사용 가능하기 때문에 래치 경합을 다소 줄일 수 있다.
- 또한 Dynamic Parellelism에 의해 동적으로 redo strands의 개수를 조정해서 redo allocation 래치의 수가 크게 늘어났다.
- SGA에 추가적으로 private redo strands라는 기능을 도입하여 다중 strands의 개념을 더욱 확장하였다.
- Private strands 영역은 프로세스 간에 공유되지 않기 때문에 리두를 생성하는 과정에서 래치를 획득할 필요가 없으며, LGWR에 의해서 리두 로그 파일로 바로 쓰여 지기 때문에 PGA에서 리두 버퍼로 복사하는 과정이 불필요하다.
- 이것은 zero copy redo라고 표현하기도 한다.
notifications_active 일반적인 환경에서는 리두 관련 래치 경합은 잘 발생하지 않는다.
- 래치 경합의 횟수보다는 래치 경합에 따른 대기시간을 경합의 발생 증거로 활용.
- 리두 버퍼의 크기가 리두 래치 경합을 일으키는 요인이 될 수도 있음
- 리두와 관련된 대부분의 성능문제가 래치 경합보다는 어플리케이션의 작동 방식이나 I/O 성능과 관련이 있다.
- 리두 래치에서 발생하는 경합에 대해서는 뚜렷한 해결책이 없는 경우가 많음
- 버전이 올라감에 따라 리두 버퍼 관련 알고리즘이 개선되어서 대부분의 경우 래치 경합은 더 이상 문제가 되지 않는다.
2.4 log file sync[편집]
select a.sid,
a.event,
a.time_waited,
a.time_waited / c.sum_time_waited * 100 pct_wait_time,
d.value user_commits,
round((sysdate - b.logon_time) * 24) hours_connected
from v$session_event a, v$session b, v$sesstat d,
(select sid, sum(time_waited) sum_time_waited
from v$session_event
where event not in (
'Null event',
'client message',
'KXFX: Execution Message Dequeue - Slave',
'PX Deq: Execution Msg',
'KXFQ: kxfqdeq - normal deqeue',
'PX Deq: Table Q Normal',
'Wait for credit - send blocked',
'PX Deq Credit: send blkd',
'Wait for credit - need buffer to send',
'PX Deq Credit: need buffer',
'Wait for credit - free buffer',
'PX Deq Credit: free buffer',
'parallel query dequeue wait',
'PX Deque wait',
'Parallel Query Idle Wait - Slaves',
'PX Idle Wait',
'slave wait',
'dispatcher timer',
'virtual circuit status',
'pipe get',
'rdbms ipc message',
'rdbms ipc reply',
'pmon timer',
'smon timer',
'PL/SQL lock timer',
'SQL*Net message from client',
'WMON goes to sleep')
having sum(time_waited) > 0 group by sid) c
where a.sid = b.sid
and a.sid = c.sid
and a.sid = d.sid
and d.statistic# = (select statistic#
from v$statname
where name = 'user commits')
and a.time_waited > 10000
and a.event = 'log file sync'
order by pct_wait_time, hours_connected;- 서버 프로세스가 커밋 또는 롤백을 수행하면 LGWR은 리두 버퍼에서 가장 최근에 기록이 이루어진 이후 시점부터 커밋 지점까지의 리두 레코드를 리두 로그 파일에 기록한다.
- 이것을 "sync write"라고 부르며 redo synch writes 통계값을 통해 조회 가능.
- 트랜잭션의 존재 이유가 데이터를 변경하고 커밋을 수행하는 것이기 때문에 log file sync 대기이벤트는 오라클에서 가장 보편적인 대기이벤트 중 하나이다.
- 보통 sync write가 수행되는 시간은 매우 짧기 때문에 log file sync 대기는 문제가 되지 않는다.
- 하지만 일단 발생하게 되면 상당히 해결하기 어려운 대기현상이다.
- 만일 log file sync 대기가 광범위하게 나타난다면 아래와 같은 사실을 의심해야한다.
- 커밋 회수와 log file sync
- - 지나치게 잦은 커밋은 log file sync 대기의 주범이다. 여러 세션에서 동시에 대량의 커밋을 수행하면 log file sync 대기가 광범위하게 나타날 수 있다.
- - 오라클은 여러 세션에서 동시에 실행하거나, PL/SQL 블록에서 반복적으로 커밋이 이루어지거나, Recursive SQL에 의해서 커밋이 이루어지는 경우 그룹 커밋 기능이 사용된다.
- 이때, user commits 통계 값은 커밋 명령을 호출한 횟수와 동일하게 증가하지만, log file sync는 한번만 발생하게 된다.
- nocache 속성의 시퀀스 또한 log file sync를 유발한다.
- - Sequence.nextval을 호출하면 매번 딕셔너리 테이블의 정보를 갱신하고 커밋을 수행해야하기 때문이다.
- I/O 시스템의 성능과 log file sync
- - 리두 로그 파일이 위치한 I/O 시스템의 성능이 느린 경우에는 LGWR의 synch write를 수행하는 시간이 늘어나고 이로 인해 log file sync 대기시간이 증가할 수 있다. ##: 이 경우, 서버 프로세스가 log file sync 이벤트를 대기하는 동안 LGWR는 log file parallel write 이벤트를 대기하게 된다.
- - 일반적인 가이드는 리두 로그 파일올 가장 빠른 다바이스에 위치시키는 것이다.
- - 디스크 경합을 피하기 위해 서로 다른 그룹의 리두 로그 파일은 서로 다른 디스크에 분산시켜야 한다.
- - 리두 로그 파일을 데이터 파일이나 컨트롤 파일과 다른 디스크에 배치시켜야 한다.
- 리두 데이터의 양과 log file sync
- 커밋 수행시 리두 로그 파일에 기록해야 할 데이터양을 줄이면 log file sync 대기시간 또한 줄일 수 있다.
- 특히 크고 긴 트랜잭션에서 리두 데이터양을 줄이게 되면 LGWR의 백그라운드 기록 작업이 줄게 되고 자연스럽게 리두와 관련된 경합이 해소될 수 있다.
- 대량의 데이터를 생성하는 작업에서는 다음과 같은 기법을 쓸 수 있는지 검토해 보아야한다.
- (1) Nologging 옵션을 사용할 수 있는지
- (2) SQL*Loader로 대량의 데이터를 적재할 때는 Direct load option을 사용한다.
- (3) 임시 작업이 필요할 때는 가능하면 임시 테이블을 사용한다.
- (4) 인덱스가 있는 테이블에 대해 Direct load 작업을 수행할 때는 인덱스를 Unusable로 변경하고 데이터 생성하고 인덱스를 Nologging 모드로 재구성과 같은 절차를 통해서 인덱스에 의해 리두가 생성되는 것을 방지한다.
- (5) LOB 데이터의 경우 데이터의 크기가 크다면 가급적 Nologging 속성을 부여한다.
- 리두 버퍼의 크기와 log file sync
- - 일반적으로 리두 버퍼의 크기가 지나치게 큰 경우에 log file sync 대기가 증가하는 경향이 있다.
- - 리두 버퍼의 크기가 큰 경우, LGWR에 의한 백그라운드 기록 횟수가 줄어 드는데, 이 경우 유저 세션에서 sync write를 수행할 때 기록해야 할 데이터의 양이 많아지고 이로 인해 log file sync 대기 시간이 길어질 수 있기 때문이다.
- - 반대로 log buffer space 대기가 증가하는 경향을 보인다면 리두 버퍼의 크기를 늘리는 것이 일반적인 해결책이다.
- - 이런 경우의 해결책은 _LOG_IO_SIZE 히든 파라미터를 이용하는 것이다.
- _LOG_IO_SIZE 파라미터는 LGWR이 리두 버퍼의 내용을 리두 로그 파일에 저장하는 임계치 값을 나타낸다.
- - log buffer space 대기를 줄이기 위해 리두 버퍼의 크기를 키우고 이와 동시에 log file sync 대기를 줄이기 위해_LOG_IO_SIZE 값을 적당히 작은 크기로 조정하면 된다.
- 커밋 회수와 log file sync
2.5 log file parallel write[편집]
- LGWR 프로세스에만 발생하는 대기 이벤트
- LGWR은 리두 버퍼의 내용을 리두 로그 파일에 기록하기 위해 필요한 I/O 콜을 수행한 후 I/O 작업이 완료되기를 기다리는 동안 log file parallel write 이벤트를 대기
- I/O 시스템의 성능에는 아무런 이상 징후가 없는데도 리두 데이터양이 지나치게 많은 경우 log file parallel write 대기가 증가할 수 있다.
- 이것을 해결하기 위한 방법은 아래와 같다.
- (1) 불필요한 커밋을 줄인다.
- (2) Nologging 옵션을 활용하여 리두 데이터의 양을 줄인다.
- (3) 리두 로그 파일이 위치한 I/O 시스템의 성능을 높인다.
- (4) 핫백업을 너무 자주 수행하지 말고, 특히 트랜잭션이 많은 시점에 수행하지 않아야 한다.
- 핫백업 모드에서는 리두 데이터가 로우 레벨이 아닌 블록 레벨로 생성되기 때문이다.
2.6 log buffer space[편집]
- redo allocation 래치를 획득한 상태에서 리두 버퍼에 공간을 확보하려는 순간에 적절한 여유 공간이 없는 경우, 공간이 확보되기를 기다려야 한다.
- 이때 경우에 따라 두 가지 종류의 이벤트를 대기하게 된다.
- 만일 현재 시용 중인 리두 로그 파일이 꽉 차서 더 이상 여유 공간을 확보할 수 없다면, LGWR은 로그 파일 스위치를 수행하고, 서버 프로세스는 log file switch completion 이벤트를 대기한다.
- 그 외의 경우에는 log buffer space 이벤트를 대기하게 된다.
- log buffer space 대기는 트랜잭션에 의해 생성되는 리두의 양에 비해 리두 버퍼의 크기가 작을 때 발생한다. # log buffer space 대기를 줄이기 위해 리두 버퍼 크기를 늘리는 경우, log file sync 대기가 증가할 수 있다.
- log buffer space 대기를 줄이는 또 하나의 방법은 리두 데이터를 적게 생성하는 것이다.
- Direct load 기능을 적당히 사용하고 Nologging 옵션을 부여하는 것 등이 이 방법에 속한다.
- 또한 더 빠르고 효율적인 I/O 시스템을 리두 로그 파일에 사용함으로써 LGWR의 쓰기 성능을 개선하고, log buffer space 대기를 줄일 수 있다.
- log file switch completion
- log file switch (checkpoint incomplete)
- log file switch (archiving needed)
- log file switch (private strand flush incomplete)
- 서버 프로세스는 LGWR에 의해 로그 파일 스위치가 끝날 때까지 log file switch completion 이벤트를 대기하게 된다.
- 하지만 로그 파일 스위치가 끝나는 시점에, 새로 사용할 리두 로그 파일에 대해 아직 종료되지 않은 작업이 있다면 아래와 같이 추가적으로 이벤트를 대기해야 한다.
- 1) 새로 사용할 리두 로그 파일에 대한 체크포인트 작업이 끝나지 않았다면 프로세스는 DBWR에 의해 체크포인트가 끝나기를 대기해야 한다. 이 경우 log file switch (checkpoint incomplete) 이벤트를 대기한다.
- 2) 새로 사용할 리두 로그 파일에 대해 아카이브 작업이 아직 끝나지 않았다면 프로세스는 아카이브 작업이 끝나기를 기다려야한다. 이 경우 log file switch (archiving needed) 이벤트를 대기한다.
- 3) 새로 사용할 리두 로그 파일에 대한 Private strands에 대한 플러시 작업이 아직 끝나지 않았다면, 이 작업이 끝나기를 기다려야한다. 이 경우 log file switch (private strand flush incomplete)이벤트를 대기하게 된다.
서버 프로세스는 먼저 log file completion이벤트를 대기하고 특수한 경우 위의 이벤트를 대기하게 된다. 위 방법들에 대한 해결책은 동일하다. 발생 원인은 트랜잭션이 생성하는 리두 데이터 양에 비해 리두 로그 파일이 지나치게 작다는 것이다. 따라서 리두 로그 파일의 크기를 충분히 키워주고, Direct load operation이나 Nologging 옵션을 사용하여 리두 데이터의 양을 줄여야 한다.