ORACLE 인덱스
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
- 1 인덱스 개념/아키텍처
1 인덱스 개념/아키텍처[편집]
1.1 B+Tree 인덱스 장점[편집]
- 인덱스를 이용해 데이터에 엑세스할 때 모든 인덱스 엔트리에 대해 균형(Balance)을 맞춤
- 인덱스를 이용한 범위(Range) 스캔 시 Double Linked List를 사용하기 때문에 다른 인덱스보다 더 유리하며 ACESENDING과 DESCENDING도 가능함
- OLTP 환경에서 적은 데이터에 엑세스하는 데 유리함
1.2 B+Tree 인덱스 단점[편집]
- 분포도(Cardinality)가 낮은 컬럼의 경우 B*TREE 인덱스가 불리함
- OR 연산자에 대해 테이블 전체를 스캔(Full Scan)하는 것은 위험함
- 인덱스 연산 불가
- 인덱스 확장 시 부하 발생
1.3 인덱스 오퍼레이션[편집]
1.3.1 추가 Insert Operation[편집]
- 테이블에 데이터가 추가되면 해당 테이블에 존재하는 인덱스에도 추가된 데이터의 인덱스 엔트리가 추가된다.
- 테이블에 추가되는 데이터의 인덱스 키(Key) 값의 저장 위치를 찾기 위해 인덱스 리프 블록을 확인해 찾는다.
- 그리고 인덱스 블록의 여유 공간에 해당 인덱스 엔트리를 추가한다.
- 해당 인덱스 블록에 여유 공간이 없을 경우, 해당 블록은 2개의 인덱스 리프 블록으로 분기돼 인덱스 키들은 다시 정렬되고
- 분기된 2개의 인덱스 리프 블록을 통해 추가된다. 이 때 리프 블록을 연결하고 있는 브랜치 블록과 루트 블록의 정보가 갱신될 수 있다.
1.3.2 삭제 Delete Operation[편집]
- Insert Operation과 정반대의 작업을 수행한다.
- 데이터가 삭제되면 해당 인덱스 엔트리의 연결이 끊어진다.
- 그렇게 함으로써 루트 블록으로부터 해당 인덱스 엔트리를 인식하지 못하게 한다.
- 삭제된 인덱스 엔트리의 공간은 추가를 위해 공간 해제를 수행하게 되며, 리프 블록에 하나의 인덱스 엔트리라도 남게 되면 인덱스 리프 블록은 유지되게 된다.
- 많은 인덱스 엔트리가 삭제되면 삭제된 공간은 반납된다.
- 그러나 해당 리프 블록의 전체 데이터가 삭제되지 않는 한 해당 리프 블록은 반납되지 않는다.
- 해당 리프 블록에 새로운 인덱스 엔트리가 추가로 저장되지 않는다면 공간이 낭비되게 된다.
1.3.3 갱신 Update Operation[편집]
- 삭제와 추가 작업이 동시에 수행되는 작업이다.
- 테이블에 데이터가 순차적으로 증가해 추가되는 경우 인덱스의 우측으로 인덱스 엔트리가 집중돼 B*TREE의 가장 중요한 특징인 균형(Balance)이 무너지게 된다.
- 또한 죄측 리프 블록으로 인덱스 엔트리가 추가되지 않기 때문에 좌측 리프 블록은 "블록 사용률" 이 낮아지게 된다.
- 삭제가 많거나 또는 인덱스 키가 순차적으로 증가하며 추가되는 테이블은 주기적인 인덱스 재구성(Rebuild)을 통해 인덱스 균형(Balance)을 유지시켜줘야 한다.
1.4 인덱스 구조[편집]
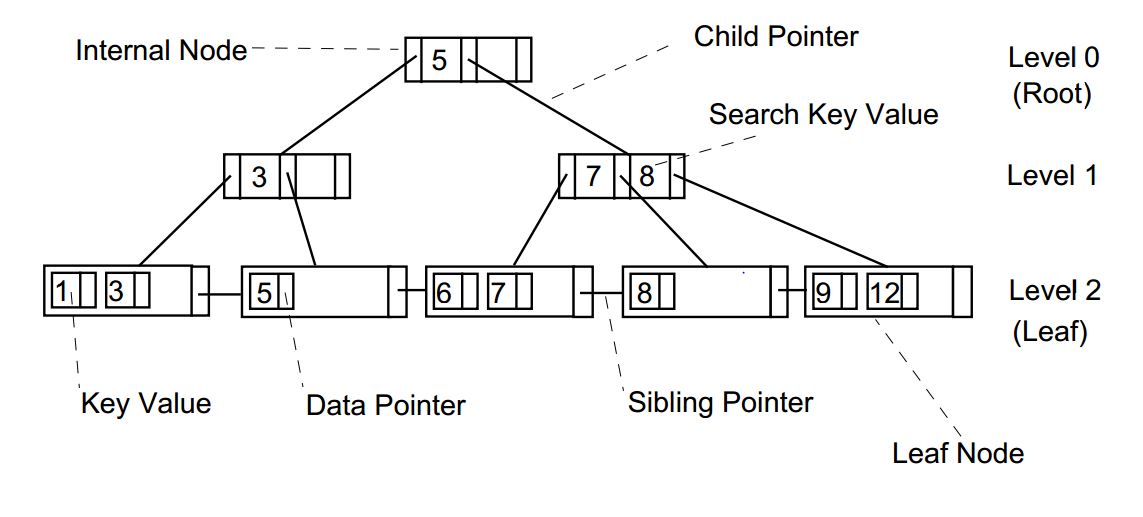
- B*tree는 leaf node 와 non-leaf 로 구성
- leaf node 부터 root node 까지의 길이는 모든 리프가 동일하다는 특징을 가지고 있다.
- 즉, 모든 리프 노드의 레벨은 동일하다.
- leaf node 간에는 링크드 리스트(linked list)로 연결되어 있어 여러 값을 스캔할 때 유리하다.
- leaf node 는 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다.
1.5 인덱스 스캔 방식[편집]
1.5.1 INDEX RANGE SCAN[편집]
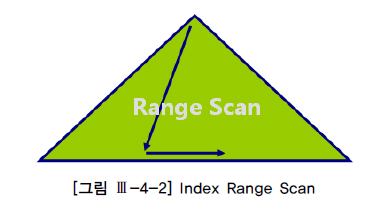
- 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위(Range)만 스캔하는 방식
- 실행계획 상에 Index Range Scan이 나타난다고 해서 항상 빠른 속도를 보장하는 것은 아님
- 인덱스를 스캔하는 범위(Range)를 얼마만큼 줄일 수 있느냐, 그리고 테이블로 액세스하는 횟수를 얼마만큼 줄일 수 있느냐가 튜닝의 관건
- Index Range Scan이 가능하게 하려면 인덱스를 구성하는 선두 칼럼이 조건절에 사용되어야 함.
- Index Range Scan 과정을 거쳐 생성된 결과집합은 인덱스 칼럼 순으로 정렬된 상태가 되기 때문에 이런 특징을 잘 이용하면 sort order by 연산을 생략하거나 min/max 값을 빠르게 추출할 수 있다.
1.5.2 INDEX FULL SCAN[편집]
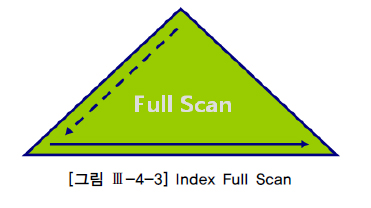
notifications_active INDEX FULL SCAN이 사용되는 경우
- Index Full Scan은 수직적 탐색 없이 수평적 탐색(인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식)으로서, 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택
- 인덱스 선두 칼럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려
- 대용량 테이블인 경우 Table Full Scan의 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 검토한다.
- 데이터 저장공간은 "칼럼길이×레코드수" 에 의해 결정되므로 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적음.
- 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 I/O 측면에서 테이블 전체를 스캔하는 것보다 낫다.
- 인덱스를 이용한 소트 연산 대체 : 옵티마이저는 소트 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 방식을 선택
- 이럴 때 옵티마이저는 Index Full Scan 방식을 선택할 수 있다.
select /*+ first_rows * / * from emp
where sal > 1000
order by ename ;
-- 인덱스 생성 (ename + sal )
create index emp_idx03 on emp(ename,sal);
select /*+ first_rows */ * from emp
where sal > 1000
order by ename ;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 12 |00:00:00.01 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 13 | 12 |00:00:00.01 | 4 |
|* 2 | INDEX FULL SCAN | EMP_IDX03 | 1 | 13 | 12 |00:00:00.01 | 2 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SAL">1000)
filter("SAL">1000)1.5.3 INDEX FAST FULL SCAN[편집]
- Index Fast Full Scan은 Index Full Scan보다 빠르다.
- Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다.
- Index Full Scan과 Fast Full Scan 비교
| INDEX FULL SCAN | INDEX FAST FULL SCAN |
|---|---|
| 1. 인덱스 구조를 따라 스캔 | 1. 세그먼트 전체를 스캔 |
| 2. 결과집합 순서 보장 | 2. 결과집합 순서 보장 안 됨 |
| 3. Single Block I/O | 3. Multiblock I/O |
| 4. 병렬스캔 불가(파티션 돼 있지 않다면) | 4. 병렬스캔 가능 |
| 5. 인덱스에 포함되지 않은 칼럼 조회 시에도 사용 가능 | 5. 인덱스에 포함된 칼럼으로만 조회할 때 사용 가능 |
1.5.5 INDEX SKIP SCAN[편집]
- 인덱스 선두 칼럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다.
- Oracle은 인덱스 선두 칼럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식을 9i 버전에서 선보였는데, 바로 Index Skip Scan이 그것이다.
- Index Skip Scan 내부 수행원리는 루트 또는 브랜치 블록에서 읽은 칼럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 “가능성이 있는” 하위 블록(브랜치 또는 리프 블록)만 골라서 액세스하는 방식이라고 할 수 있다.
- 이 스캔 방식은 조건절에 빠진 인덱스 선두 칼럼의 Distinct Value 개수가 적고 후행 칼럼의 Distinct Value 개수가 많을 때 유용하다.
1.6 인덱스 종류[편집]
1.6.1 압축된 인덱스 Compressed Index[편집]
1.6.2 리버스키 인덱스 Reverse-key Index[편집]
1.6.3 함수형 인덱스 Function-based Index[편집]
1.6.4 Linguistic Index[편집]
1.6.5 Text Index[편집]
1.7 오라클 인덱스의 특징[편집]
- Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다.
- 즉, 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다.
- 테이블 레코드값이 갱신되면 리프노드 인덱스 키값도 갱신된다. 반면 리프노드상의 엔트리값이 갱신되더라고 보랜치 노드까지 값이 바뀌지는 않는다.
- 브랜치 노드는 인덱스 분할에 의해 새로운 블록이 추가되거나 삭제 될때만 갱신된다. (브랜치 노드상의 키값은 하위 노드가 갖는 값의 범위를 의미)
1.7.1 인덱스를 사용 할수 없는 경우[편집]
1.7.1.1 인덱스 사용이 불가능하거나 범위 스캔이 불가능한 경우[편집]
- 인덱스 구성 정보조회
select INDEX_OWNER,INDEX_NAME,TABLE_OWNER,TABLE_NAME,COLUMN_NAME
from ALL_IND_COLUMNS
where table_name ='EMP'
INDEX_OWNER INDEX_NAME TABLE_OWNER TABLE_NAME COLUMN_NAME
------------------------------ ------------------------------ ------------------------------ ------------------------------ ---------------
SCOTT PK_EMP SCOTT EMP EMPNO
-------------------------------------------------------------------------------------------------------------------------------------------- 1. empno 컬럼을 가공한 경우
select *
from emp
where substr(empno,1,2) = 7369- 2. empno 컬럼이 <> 으로 사용된경우
select *
from emp
where empno <> 7369- 3. empno 컬럼이 is not null 로 사용된 경우
select *
from emp
where empno is not null
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 7 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 0 |00:00:00.01 | 7 |
------------------------------------------------------------------------------------1.7.1.2 인덱스 컬럼 가공 사례[편집]
notifications_active 인텍스 컬럼을 수정(가공) 하면 안되는 이유
인덱스 컬럼을 수정하는 경우 범위 스캔을 위한 시작점을 찾을 수 없어서 옵티마이저는 인덱스 전체를 스캔(INDEX FULL SCAN) 하거나 테이블 전체를 스캔(FULL TABLE SCAN)하는 방식을 취한다.
- 컬럼을 가공한 경우 SQL 변경을 통한 성능 개선 방법

1.8 인텍스 튜닝 방안[편집]
1.8.1 is null 조건을 사용하더라도 다른컬럼의 조건이 하나라도 있으면 range scan가능[편집]
-- depotno 컬럼을 2번째 항목으로 추가
create index emp_idx on emp(job,deptno);
select *
from emp
where job is null
and deptno =20; <= job은 null 이지만 deptno가 20인 조건으로 range scan이 가능함.
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | 1 | 0 |00:00:00.01 | 1 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("JOB" IS NULL AND "DEPTNO"=20)
filter("DEPTNO"=20)1.8.2 함수기반 인덱스 사용[편집]
-- v_deptno 문자형 타입으로 컬럼 추가
alter table emp add v_deptno varchar2(2);
update emp set v_deptno = deptno;
Process Time: 0.0194 sec
14 row(s) affected;
-- 인덱스 생성
create index emp_x01 on emp(v_deptno);
-- 숫자형 타입으로 조회 하면 인덱스가 사용되지 않음.
select * from emp where v_deptno =20;
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 8 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 5 |00:00:00.01 | 8 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_NUMBER("V_DEPTNO")=20)- TO_NUMBER("V_DEPTNO") 를 사용하여 함수형 인덱스 생성
create index emp_x02 on emp(TO_NUMBER("V_DEPTNO"));
select * from emp where v_deptno =20;
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 5 |00:00:00.01 | 4 |
|* 2 | INDEX RANGE SCAN | EMP_X02 | 1 | 1 | 5 |00:00:00.01 | 2 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMP"."SYS_NC00011$"=20)1.8.3 null 허용케이스[편집]
create index emp_fbi01 on emp(mgr,'');
select *
from emp
where mgr is null;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 |
|* 2 | INDEX RANGE SCAN | EMP_FBI01 | 1 | 1 | 0 |00:00:00.01 | 1 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("MGR" IS NULL)1.9 INDEX 정보 조회[편집]
1.9.1 인덱스 관련 뷰[편집]
* DBA|ALL|USER_INDEXES
* DBA|ALL|USER_IND_COLUMNS1.9.2 사용자 인덱스 구성 컬럼 정보[편집]
- 현재 사용자의 인덱스와 각 인덱스를 구성하는 컬럼 정보 확인
SELECT A.INDEX_NAME
, A.UNIQUENESS
, TO_CHAR(COLUMN_POSITION, '999') AS POS
, SUBSTRB(COLUMN_NAME, 1, 33) AS COLUMN_NAME
FROM USER_INDEXES A
, USER_IND_COLUMNS B
WHERE A.INDEX_NAME = B.INDEX_NAME
AND A.TABLE_OWNER = UPPER('E_LUCIS')
AND A.TABLE_NAME = UPPER('&테이블명')
ORDER BY 1, 3;1.9.3 전체 INDEX 보기[편집]
- DBA권한으로 확인가능하는 전체 인덱스 및 인덱스구성 컬럼 정보 조회
SELECT SUBSTRB(A.TABLE_NAME, 1, 22) AS TABLE_NAME
, SUBSTRB(A.INDEX_NAME, 1, 23) AS INDEX_NAME
, SUBSTRB(A.UNIQUENESS, 1, 7) AS UNIQUE
, TO_CHAR(COLUMN_POSITION, '999') AS POS
, SUBSTRB(COLUMN_NAME, 1, 20) AS COLUMN_NAME
FROM DBA_INDEXES A
, DBA_IND_COLUMNS B
WHERE A.INDEX_NAME = B.INDEX_NAME
AND A.TABLE_OWNER = B.TABLE_OWNER
AND A.TABLE_OWNER = 'E_LUCIS'
ORDER BY 1, 2, 3;1.9.4 전체 INDEX 리빌드 대상 조회[편집]
-------------------------------------------------------------------------------
-- 인덱스 조회
-- BLEVEL(인덱스깊이) : 4이상이면 REBUILD 고려 -
-- LEAF_BLOCKS(리프블록수) : 4이상이면 REBUILD 고려 -
-------------------------------------------------------------------------------
SELECT
INDEX_NAME AS "인덱스명"
, INDEX_TYPE AS "인덱스타입"
, TABLE_OWNER AS "오너"
, TABLE_NAME AS "테이블명"
, TABLE_TYPE AS "테이블타입"
, UNIQUENESS AS "UNIUE여부"
, BLEVEL AS "인덱스깊이"
, LEAF_BLOCKS AS "리프블록수"
, TABLESPACE_NAME AS "테이블스페이스"
, INI_TRANS AS "동시트랜잭션수" -- 동시에 엑세스 가능한 트랜잭션의 초기 개수
, MAX_TRANS AS "MAX트랜잭션수" -- 동시엑세스 가능한 MAX 트랜잭션 수
FROM USER_INDEXES
WHERE TABLE_OWNER = 'SHE'
AND INDEX_TYPE = 'NORMAL'
AND INDEX_NAME LIKE '%%'
ORDER BY BLEVEL DESC, LEAF_BLOCKS DESC
;1.9.5 특정 테이블의 인덱스 확인[편집]
- 현재 사용자의 특정 테이블 정보 확인
SELECT C.TABLE_NAME , C.INDEX_NAME , C.COLUMN_NAME , C.COLUMN_POSITION , T.NUM_ROWS
FROM ALL_IND_COLUMNS C
, (SELECT TABLE_NAME, NUM_ROWS
FROM ALL_TABLES
WHERE OWNER = '&사용자'
AND TABLE_NAME IN (SELECT TABLE_NAME
FROM USER_TABLES
WHERE TABLE_NAME LIKE:IN_TABLE_NAME || '%'
)
AND NUM_ROWS > 0
) T
WHERE C.TABLE_NAME = T.TABLE_NAME
ORDER BY T.NUM_ROWS DESC
, C.TABLE_NAME
, C.INDEX_NAME
, C.COLUMN_POSITION;1.9.6 인덱스에 대한 컬럼 조회[편집]
- 사용자의 인덱스 컬럼 구성 정보
SELECT TABLE_NAME , INDEX_NAME , COLUMN_POSITION , COLUMN_NAME
FROM USER_IND_COLUMNS
ORDER BY TABLE_NAME
, INDEX_NAME
, COLUMN_POSITION;1.9.7 PRIMARY KEY를 REFERENCE 하는 FOREIGN KEY 찾기[편집]
- 특정테이블의 PK를 참조하고 있는 외부키(FK) 정보 조회
SELECT C.NAME CONSTRAINT_NAME
FROM DBA_OBJECTS A
, CDEF$ B
, CON$ C
WHERE A.OBJECT_NAME = UPPER('&테이블명')
AND A.OBJECT_ID = B.ROBJ#
AND B.CON# = C.CON#;1.9.8 중복인덱스 체크[편집]
- 중복된 컬럼으로 사용중인 인덱스 정보 조회
SELECT O1.NAME || '.' || N1.NAME REDUNDANT_INDEX, O2.NAME || '.' || N2.NAME SUFFICIENT_INDEX
FROM SYS.ICOL$ IC1 , SYS.ICOL$ IC2 , SYS.IND$ I1 , SYS.OBJ$ N1 , SYS.OBJ$ N2 , SYS.USER$ O1 , SYS.USER$ O2
WHERE IC1.POS# = 1
AND IC2.BO# = IC1.BO#
AND IC2.OBJ#!= IC1.OBJ#
AND IC2.POS# = 1
AND IC2.INTCOL# = IC1.INTCOL#
AND I1.OBJ# = IC1.OBJ#
AND BITAND(I1.PROPERTY, 1) = 0
AND (SELECT MAX(POS#) * (MAX(POS#) + 1) / 2
FROM SYS.ICOL$
WHERE OBJ# = IC1.OBJ#) = (SELECT SUM(XC1.POS#)
FROM SYS.ICOL$ XC1 , SYS.ICOL$ XC2
WHERE XC1.OBJ# = IC1.OBJ#
AND XC2.OBJ# = IC2.OBJ#
AND XC1.POS# = XC2.POS#
AND XC1.INTCOL# = XC2.INTCOL#)
AND N1.OBJ# = IC1.OBJ#
AND N2.OBJ# = IC2.OBJ#
AND O1.USER# = N1.OWNER#
AND O2.USER# = N2.OWNER#;1.9.9 테이블의 PK를 구성하는 컬럼 조회[편집]
- 사용자 테이블의 기본키(PK) 정보
SELECT A.TABLE_NAME, B.CONSTRAINT_NAME, C.COLUMN_NAME
FROM USER_TABLES A
, USER_CONSTRAINTS B
, USER_CONS_COLUMNS C
WHERE A.TABLE_NAME = B.TABLE_NAME
AND B.CONSTRAINT_NAME = C.CONSTRAINT_NAME
AND B.CONSTRAINT_TYPE = 'P';1.9.10 인덱스의 Delete Space 조회[편집]
- 인덱스의 Delete Space% 값이 20% 가 넘으면, 그 인덱스는 다시 작성하는 것이 좋다.
SELECT NAME , LF_ROWS , DEL_LF_ROWS
, (DEL_LF_ROWS / LF_ROWS) * 100 AS "DELETE SPACE%"
FROM INDEX_STATS
WHERE NAME = UPPER('&INDEX_NAME');1.9.11 Index가 없는 Table 조회[편집]
- 인덱스 없는 테이블 정보 조회
SELECT OWNER, TABLE_NAME
FROM (SELECT OWNER, TABLE_NAME
FROM DBA_TABLES
MINUS
SELECT TABLE_OWNER, TABLE_NAME
FROM DBA_INDEXES
)
WHERE OWNER NOT IN ('SYS', 'SYSTEM')
ORDER BY OWNER, TABLE_NAME;1.9.12 INDEX INVISIBLE[편집]
- 인덱스를 실제 삭제하기 전에 "사용 안 함" 상태로 변경 하는것
- 인덱스가 많은 경우 DML문장에 나쁜 영향을 주기 때문에 사용하지 않는 인덱스는 삭제할때 유용
- 인덱스를 삭제하려고 했을 때, 정말 사용하는지 사용하지 않는 것인지를 정확하게 알수 없음.
- INVISIBLE 상태에서 DML 작업 시 인덱스 내용은 계속 반영 됨.
1.10 인덱스 생성[편집]
- 생성시 주의점
- 테이블과 인덱스가 같은 테이블스페이스에 있으면 안됨. 성능 저하!, 전용 인덱스 테이블스페이스를 사용할 것!
- index 생성시 redolog에도 기록이 되는데 인덱스가 클 경우 시간이 너무 오래걸리기 때문에 생성시 nologging 옵션을 줘서 리빌드 후 alter로 변경.
1.10.1 인덱스 생성문[편집]
CREATE INDEX 인덱스명
ON 테이블명(칼럼명)
PCTFREE *
STORAGE(INITIAL * NEXT * PCTINCREASE * MAXEXTENTS *)
TABLESPACE T/S명 ;
* -- PCTUSED 옵션은 index는 지워지지 않기 때문에 필요 없음.
* -- STORAGE 행은 ASSM일 경우 알아서 자동적으로 설정되기 때문에 신경 쓸 필요는 없음.1.10.2 PRIMARY KEY DISABLE/ENABLE[편집]
-- PK DISABLE
ALTER TABLE TB_PK_TEST
DISABLE CONSTRAINT PK_PK_TEST;
-- PK ENABLE
ALTER TABLE TB_PK_TEST
ENABLE CONSTRAINT PK_PK_TEST;1.10.3 PRIMARY KEY 재생성[편집]
- -- PRIMARY KEY DROP
ALTER TABLE EMP DROP PRIMARY KEY;- -- PRIMARY KEY 생성
ALTER TABLE EMP
ADD CONSTRAINT EMP_PK
PRIMARY KEY(EMPNO) USING INDEX
STORAGE (INITIAL 1M NEXT 1M PCTINCREASE 0)
TABLESPACE USERS;1.10.4 PK 생성 스크립트 SQL[편집]
SELECT 'ALTER TALLE '||OWNER||'.'||TABLE_NAME||' ADD CONSTRAINTS '||CONSTRAINT_NAME||' PRIMARY KEY ('||COLS||');' AS DDL
FROM (
SELECT C.OWNER
, C.TABLE_NAME
, S.CONSTRAINT_NAME
-- , S.CONSTRAINT_TYPE
, LISTAGG(C.COLUMN_NAME,',') WITHIN GROUP (ORDER BY POSITION) COLS
-- , C.POSITION
FROM DBA_CONS_COLUMNS C
, DBA_CONSTRAINTS S
WHERE C.CONSTRAINT_NAME = S.CONSTRAINT_NAME
AND S.CONSTRAINT_TYPE = 'P'
AND C.TABLE_NAME IN (
'TB_EMP'
)
GROUP BY C.OWNER
, C.TABLE_NAME
, S.CONSTRAINT_NAME
)1.10.5 테이블/PK 인덱스 추출 SQL 생성[편집]
- 오라클 DBMS_METADATA.GET_DDL() 내장패키지/함수를 이용한 테이블,인덱스 추출
sqlplus spool 기능으로 일괄생성하여 추출/백업 스크립트를 편리하게 작성할수 있다.
SELECT OWNER
, TABLE_NAME
, CONSTRAINT_NAME
-- , 'SELECT dbms_metadata.get_ddl(''TABLE'','''||CONSTRAINT_NAME||''','''||OWNER||''') FROM DUAL;' TABLE_DDL
, 'SELECT dbms_metadata.get_ddl(''INDEX'','''||CONSTRAINT_NAME||''','''||OWNER||''') FROM DUAL;' INDEX_DDL
-- , LISTAGG(COLUMN_NAME,',') WITHIN GROUP (ORDER BY POSITION) PK_COLS
FROM (
SELECT A.OWNER
, A.TABLE_NAME
, B.CONSTRAINT_NAME
, C.COLUMN_NAME
, C.POSITION
FROM DBA_TABLES A
, DBA_CONSTRAINTS B
, DBA_CONS_COLUMNS C
WHERE A.TABLE_NAME = B.TABLE_NAME
AND (A.OWNER,A.TABLE_NAME) IN (SELECT OWNER,TABLE_NAME
FROM MIG_TABLES X
WHERE SYSTEM_CODE = 'LC1'
AND A.TABLE_NAME = X.TABLE_NAME
)
AND B.CONSTRAINT_NAME = C.CONSTRAINT_NAME
AND B.CONSTRAINT_TYPE = 'P' -- PK만 출력시
)
GROUP BY OWNER
, TABLE_NAME
, CONSTRAINT_NAME
ORDER BY 1,2,3
;1.10.6 온라인 인덱스 생성[편집]
- DML이 실시간으로 발생하더라도 테이블 LOCK 없이 INDEX 생성 또는 REBUILD 가능
- 사용 예
-- 일반적으로 사용하는 인덱스 생성 DDL
CREATE INDEX 스키마.인덱스이름
ON 스키마.테이블이름 (컬럼들)
TABLESPACE 테이블스페이스
STORAGE
(
INITIAL 64K
NEXT 1M
)
NOLOGGING
ONLINE -- 온라인 옵션
;
ALTER INDEX 스키마.인덱스이름 LOGGING;1.10.6.1 ONLINE 인덱스 작업이 불가능한 경우[편집]
- 컬럼의 길이가 너무 길어 online 작업 불가
- If 8K block size then maximum index key length=3218
- If 16K block size then maximum index key length=6498
- How the maximum index key length is measured by?
- Maximum index key length=Total index length (Sum of width of all indexed column+the number of indexed columns)+Length of the key(2 bytes)+ROWID(6 bytes)+the length of the rowid(1 byte)
- 에러 내용
ORA-00604: 순환 SQL 레벨 1 에 오류가 발생했습니다
ORA-01450: 키의 최대 길이(3215)를 초과했습니다1.11 인비저블 인덱스 INVISIBLE INDEX[편집]
android * 인덱스를 실제 생성/삭제하기 전에 "사용 안함" 상태로 만들어서 테스트해 볼 수 있는 기능을 제공하는 인덱스이다.(11g New Feature)
- 인덱스가 많은 경우 DML문장에 나쁜 영향을 주기 때문에 사용하지 않는 인덱스는 삭제해 주어야 한다.
- 문제는 해당 인덱스를 삭제하려고 했을 때, 정말 사용하는지 사용하지 않는 것인지를 정확하게 알아야 한다.
- 모니터링 기간이 잘못 되었다든지 해서 인덱스를 삭제했는데, 나중에 생각지도 못했던 부분에서 문제가 발생할 수 있다.
1.11.1 인비저블 인덱스 조회[편집]
select VISIBILITY
from dba_indexes
where index_name='IX_DBCAFE_01'
and owner='DBCAFE';-- INVISIBLE 로 변경시
ALTER INDEX DBCAFE.IX_DBCAFE_01 INVISIBLE;1.11.2 인비저블 인덱스 생성[편집]
- Index를 Invisible Index로 생성
- Invisible Index는 옵티마이져가 PLAN을 결정할때 관여하지 않는 인덱스임
- (주의) 인덱스가 REBUILD 되면 VISIBLE INDEX로 변경된다.
CREATE INDEX EMP.IDX_TEST ON EMP.TB_TEST(COL1,COL2,COL3)
PCTFREE 10
INITRANS 5
PARALLEL 8 NOLOGGING
TABLESPACE TS_IDX
INVISABLE -- 인비저블 인덱스
ONLINE -- DML 발생시에도 테이블에 LOCK이 발생되지 않음.
;1.11.3 VISIBLE 인덱스로 변경[편집]
ALTER INDEX EMP.IX_TEST VISIBLE;1.11.4 인비저블 인덱스 사용시 검토사항[편집]
- 테이블에 대한 Acess Path 분석을 통한 영향도 및 타당성 검토를 수행한다.
- index를 만들었을때 DML에 의한 성능저하 요인은?
- index에 의한 효과 대상 SQL은?
- 효과의 영향도는?
- 다음을 SESSION LEVEL로 적용 후 관련 SQL에 대한 모든 PLAN점검을 실행한다.
ALTER SESSION SET optimizer_use_invisible_indexes=TRUE;
1.12 인덱시 생성시 필요한 사이즈 추정치 계산[편집]
--Below script is to get the required space for index creation, before actually it is being created.
--- Lets check for create index DBACLASS.INDEX1 on DBACLASS.EMP(EMPNO)
SET SERVEROUTPUT ON
DECLARE
v_used_bytes NUMBER(10);
v_Allocated_Bytes NUMBER(10);
BEGIN
DBMS_SPACE.CREATE_INDEX_COST
(
'create index DBACLASS.INDEX1 on DBACLASS.EMP(EMPNO)',
v_used_Bytes,
v_Allocated_Bytes
);
DBMS_OUTPUT.PUT_LINE('Used Bytes MB: ' || round(v_used_Bytes/1024/1024));
DBMS_OUTPUT.PUT_LINE('Allocated Bytes MB: ' || round(v_Allocated_Bytes/1024/1024));
END;
/
1.13 인덱스 사이즈 조사[편집]
- -- INDEX 사이즈 조사
MERGE INTO MIG_TABLES A
USING (
SELECT C.OWNER,C.TABLE_NAME
-- ,X.SEGMENT_NAME
,SUM(X.SIZE_MB) SIZE_MB
FROM DBA_INDEXES C
, (
SELECT A.OWNER
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
, ROUND(SUM(A.BYTES)/1024/1024) "SIZE_MB"
FROM DBA_SEGMENTS A
, DBA_INDEXES B
WHERE A.SEGMENT_NAME = B.INDEX_NAME
AND A.SEGMENT_TYPE IN ('INDEX','INDEX PARTITION')
AND A.OWNER = B.OWNER
-- AND A.OWNER = '유저아이디'
AND EXISTS (SELECT 1
FROM MIG_TABLES C
WHERE C.TABLE_NAME = B.TABLE_NAME
AND C.OWNER = B.OWNER
AND C.SYSTEM_CODE = 'LC1'
AND C.USE_YN = 'Y'
)
GROUP BY A.OWNER
, A.SEGMENT_NAME
, A.SEGMENT_TYPE
) X
WHERE C.OWNER = X.OWNER
AND C.INDEX_NAME = X.SEGMENT_NAME
-- ORDER BY 1,2,3
GROUP BY C.OWNER,C.TABLE_NAME
-- HAVING COUNT(*) > 1
) B
ON (A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME)
WHEN MATCHED THEN UPDATE SET
A.ASIS_INDEX_SIZE = B.SIZE_MB
;1.14 인덱스 삭제[편집]
DROP INDEX [인덱스명]1.15 인덱스명 변경[편집]
ALTER INDEX OWNER.INDEX_NAME RENAME TO TO_INDEX_NAME;1.16 인덱스 리빌드[편집]
ALTER INDEX 인덱스명 REBUILD TABLESPACE T/S명 ;1.16.1 인덱스 리빌드 생성 뷰 샘플[편집]
- 인덱스 테이블스페이스를 사용하지 않는 OWNER,INDEX 점검 및 인덱스 테이블스페이스로 이동
CREATE OR REPLACE FORCE VIEW V_DBA_CHK_INVALID_TS
(
TS_NAME
, ORG_TS_NAME
)
BEQUEATH DEFINER
AS
SELECT 'ALTER INDEX '
|| OWNER
|| '.'
|| INDEX_NAME
|| ' REBUILD TABLESPACE TS_'
|| OWNER
|| '_I01;' TS_NAME
, TABLESPACE_NAME ORG_TS_NAME
FROM DBA_INDEXES
WHERE 1 = 1
AND OWNER IN (SELECT USERNAME
FROM TB_MGR_USER -- 사용자 테이블 생성
WHERE SCHEMA_YN = 'Y')
AND NOT REGEXP_LIKE (TABLESPACE_NAME, 'I01$')
AND NOT REGEXP_LIKE (INDEX_NAME, '^SYS|PK$|^PK');1.17 인덱스 DISABLE/ENABLE[편집]
- 중요) 인덱스 DISABLE 후 TRUNCATE 를 실시하면 인덱스가 자동으로 ENABLE 됨에 주의 할것
-- 세션 변경 (import 명령어시에도 해당 옵션 사용 가능)
ALTER SESSION SET SKIP_UNUSABLE_INDEXES = TRUE;
-- INDEX 사용중지
ALTER INDEX IX_PK_TEST_01 UNUSABLE;
-- INDEX 리빌드
ALTER INDEX IX_PK_TEST_01 REBUILD;1.18 인덱스 관리 프로시져[편집]
CREATE OR REPLACE PROCEDURE SP_ADD_INDEX
/*
-- 2019/08/05
-- 인덱스 추가 테이블
-- 권한 추가시 권한관리테이블(TB_MGR_GRANT)에 관리 대상을 추가한다.
-- BY CY.KIM
-- ----------------------------------------------------------------
-- 인덱스 정보 동기화 관리테이블 <-> 운영인덱스 간 MERGE
-- SP_ADD_INDEX(p_iowner=>'SCOTT',p_option => 'M' ,p_exec=>1);
--
-- INDEX 관리테이블(TB_MGR_INDEX)
CREATE TABLE TB_MGR_INDEX
(
TABLE_OWNER VARCHAR2(128 BYTE) NOT NULL,
TABLE_NAME VARCHAR2(128 BYTE) NOT NULL,
INDEX_OWNER VARCHAR2(128 BYTE) NOT NULL,
INDEX_NAME VARCHAR2(128 BYTE) NOT NULL,
COLUMN_CNT NUMBER,
INDEX_COLUMNS VARCHAR2(4000 BYTE),
INDEX_TYPE VARCHAR2(27 BYTE),
UNIQUENESS VARCHAR2(9 BYTE),
TABLESPACE_NAME VARCHAR2(30 BYTE),
PARTITIONED VARCHAR2(3 BYTE),
CREATED DATE DEFAULT SYSDATE NOT NULL
);
CREATE TABLE TB_MGR_INDEX_LOG
(
TABLE_OWNER VARCHAR2(128 BYTE) NOT NULL,
TABLE_NAME VARCHAR2(128 BYTE) NOT NULL,
INDEX_OWNER VARCHAR2(128 BYTE) NOT NULL,
INDEX_NAME VARCHAR2(128 BYTE) NOT NULL,
COLUMN_CNT NUMBER,
INDEX_COLUMNS VARCHAR2(4000 BYTE),
INDEX_TYPE VARCHAR2(27 BYTE),
UNIQUENESS VARCHAR2(9 BYTE),
TABLESPACE_NAME VARCHAR2(30 BYTE),
PARTITIONED VARCHAR2(3 BYTE),
CREATED DATE NOT NULL,
CREATED_SQL VARCHAR2(2000 BYTE),
P_OPTION VARCHAR2(100 BYTE)
)
*/
(
p_iowner in varchar2 default ''
, p_iname in varchar2 default ''
, p_itype in varchar2 default '' -- index type NORMAL,FUNCTION BASED ,IOT
, p_towner in varchar2 default null
, p_tname in varchar2 default null
, p_uniq in varchar2 default '' -- index type UNIQUE,NONUNIQUE
, p_cols in varchar2 default ''
, p_cols_cnt in varchar2 default ''
, p_tsname in varchar2 default 'TS_SCOTT_I01'
, p_part in varchar2 default '' -- Partition
, p_option in varchar2 default 'A' -- D:Drop all Index, C:Create all Index , A:Add create one index ,R:Remove index one,M:MERGE
, p_dblink in varchar2 default '' -- DB링크명
, p_exec in number default 0
)
IS
/* 1.권한관리테이블에 추가 대상 */
CURSOR ADD_OBJECT IS
-- 1.신규 추가된 권한 TB_MGR_INDEX 입력
SELECT TABLE_OWNER
, TABLE_NAME
, INDEX_OWNER
, INDEX_NAME
, COLUMN_CNT
, INDEX_COLUMNS
, INDEX_TYPE
, CASE UNIQUENESS WHEN 'NONUNIQUE' THEN '' END AS UNIQUENESS
, TABLESPACE_NAME
, PARTITIONED
FROM TB_MGR_INDEX@DL_SCOTT_DEV_A
WHERE A.TABLE_OWNER = p_towner
AND A.TABLE_NAME = p_tname
;
V_SQL VARCHAR2(2000);
V_TABLE_OWNER VARCHAR2(100);
V_TABLE_NAME VARCHAR2(100);
V_INDEX_OWNER VARCHAR2(100);
V_INDEX_NAME VARCHAR2(100);
V_COLUMN_CNT VARCHAR2(100);
--[5]
V_INDEX_COLUMNS VARCHAR2(300);
V_INDEX_TYPE VARCHAR2(100);
V_UNIQUENESS VARCHAR2(100);
V_TABLESPACE_NAME VARCHAR2(100);
V_PARTITIONED VARCHAR2(100);
--[10]
V_ROWCNT NUMBER;
V_MSG long;
BEGIN
-- DBMS_OUTPUT.ENABLE;
dbms_output.enable(3000);
-- IF p_dblink is not null THEN
-- p_dblink := '@'||p_dblink
-- END IF;
-- ------------------------ 전체 인덱스 MERGE M ----------------------------------
IF p_option = 'M' THEN
dbms_output.put_line('[SUCESS] ');
V_SQL:='MERGE INTO TB_MGR_INDEX T
USING (
SELECT A.TABLE_OWNER , A.TABLE_NAME , A.INDEX_OWNER , A.INDEX_NAME , A.COLUMN_CNT , A.INDEX_COLUMNS , A.INDEX_TYPE , A.UNIQUENESS , A.TABLESPACE_NAME , A.PARTITIONED
FROM VW_INDEXES'||case when p_dblink is not null then '@'||p_dblink else '' end||' A
WHERE NOT EXISTS (SELECT 1 FROM DBA_CONSTRAINTS'||case when p_dblink is not null then '@'||p_dblink else '' end||' B
WHERE B.INDEX_NAME = A.INDEX_NAME
AND B.INDEX_OWNER = A.INDEX_OWNER
AND B.TABLE_NAME = A.TABLE_NAME
AND B.CONSTRAINT_TYPE = ''P'' -- PK
)
AND A.INDEX_OWNER IN ('''||p_iowner||''')
) S
ON ( T.TABLE_OWNER = S.TABLE_OWNER
AND T.TABLE_NAME = S.TABLE_NAME
AND T.INDEX_OWNER = S.INDEX_OWNER
AND T.INDEX_NAME = S.INDEX_NAME
)
WHEN MATCHED THEN
-- INDEX명이 같으면 컬럼 UPDATE
UPDATE SET T.INDEX_COLUMNS = S.INDEX_COLUMNS
, T.COLUMN_CNT = S.COLUMN_CNT
WHERE T.INDEX_COLUMNS <> S.INDEX_COLUMNS
WHEN NOT MATCHED THEN
-- INDEX명이 다르면 INSERT
INSERT ( TABLE_OWNER , TABLE_NAME , INDEX_OWNER , INDEX_NAME , COLUMN_CNT , INDEX_COLUMNS , INDEX_TYPE , UNIQUENESS , TABLESPACE_NAME , PARTITIONED )
VALUES ( S.TABLE_OWNER , S.TABLE_NAME , S.INDEX_OWNER , S.INDEX_NAME , S.COLUMN_CNT , S.INDEX_COLUMNS , S.INDEX_TYPE , S.UNIQUENESS , S.TABLESPACE_NAME , S.PARTITIONED )';
IF p_exec <> 0 THEN
EXECUTE IMMEDIATE V_SQL;
V_ROWCNT := sql%rowcount;
dbms_output.enable(3000);
dbms_output.put_line( V_ROWCNT || ' rows merged' );
dbms_output.put_line('[SUCESS] '||V_SQL);
COMMIT;
ELSE
dbms_output.enable(3000);
dbms_output.put_line('[SQL] '||V_SQL);
END IF;
-- ------------------------ 단건 인덱스 생성 A ----------------------------------
ELSIF p_option = 'A' THEN
V_SQL := 'CREATE '||p_uniq||' INDEX '||p_iowner||'.'||p_iname||' ON '||p_towner||'.'||p_tname||'('||p_cols||')'||' TABLESPACE '||p_tsname;
IF p_exec <> 0 THEN
EXECUTE IMMEDIATE V_SQL;
-- 입력
-- INSERT INTO TB_MGR_INDEX
-- (OWNER, INDEX_NAME, INDEX_TYPE, TABLE_OWNER, TABLE_NAME, TABLESPACE_NAME, INDEX_COLS, USE_YN)
-- VALUES (p_iowner,p_iname ,p_itype ,p_iowner , p_tname ,p_tsname ,p_cols,'Y');
-- COMMIT;
SP_INS_MGR_INDEX@DL_SCOTT_DEV_
p_iowner
, NVL(p_towner,p_iowner)
, p_tname
, p_iname
, p_uniq
, p_itype
, p_cols
, p_cols_cnt
, p_tsname
, p_part
);
-- 로그 입력
INSERT INTO TB_MGR_INDEX_LOG A (
A.TABLE_OWNER
, A.TABLE_NAME
, A.INDEX_OWNER
, A.INDEX_NAME
, A.COLUMN_CNT
----[5]
, A.UNIQUENESS
, A.TABLESPACE_NAME
, A.INDEX_COLUMNS
, A.PARTITIONED
, A.P_OPTION
----[10]
, A.CREATED_SQL
) VALUES (
nvl(p_towner,p_iowner)
, p_tname
, p_iowner
, p_iname
, p_cols_cnt
----[5]
, p_uniq
, p_tsname
, p_cols
, p_part
, p_option
----[10]
, V_SQL
);
COMMIT;
dbms_output.enable(500);
dbms_output.put_line('[SUCESS] '||V_SQL);
ELSE
dbms_output.enable(100);
dbms_output.put_line('[SQL] '||V_SQL);
END IF;
-- ------------------------ 단건 인덱스 삭제 R 인경우 ----------------------------------
ELSIF p_option = 'R' THEN
V_SQL := 'DROP INDEX '||p_iowner||'.'||p_iname;
IF p_exec <> 0 THEN
EXECUTE IMMEDIATE V_SQL;
-- 삭제
-- DELETE FROM TB_MGR_INDEX WHERE TABLE_OWNER = p_iowner AND TABLE_NAME = p_tname AND INDEX_NAME = p_iname;
-- COMMIT;
SP_DEL_MGR_INDEX@DL_SCOTT_DEV_
p_iowner
, nvl(p_towner,p_iowner)
, p_tname
, p_iname
, 'D'
, 1
);
INSERT INTO TB_MGR_INDEX_LOG A (
A.TABLE_OWNER
, A.TABLE_NAME
, A.INDEX_OWNER
, A.INDEX_NAME
, A.COLUMN_CNT
----[5]
, A.UNIQUENESS
, A.TABLESPACE_NAME
, A.INDEX_COLUMNS
, A.PARTITIONED
, A.P_OPTION
----[10]
, A.CREATED_SQL
) VALUES (
nvl(p_towner,p_iowner)
, p_tname
, p_iowner
, p_iname
, p_cols_cnt
----[5]
, p_uniq
, p_tsname
, p_cols
, p_part
, p_option
----[10]
, V_SQL
);
COMMIT;
dbms_output.enable(500);
dbms_output.put_line('[SUCESS] '||V_SQL);
ELSE
dbms_output.enable(100);
dbms_output.put_line('[SQL] '||V_SQL);
END IF;
-- ------------------------ 다중건 생성 p_option C,D 인경우 ----------------------------------
ELSE
FOR V_ROW IN ADD_OBJECT
LOOP
V_TABLE_OWNER := V_ROW.TABLE_OWNER;
V_TABLE_NAME := V_ROW.TABLE_NAME;
V_INDEX_OWNER := V_ROW.INDEX_OWNER;
V_INDEX_NAME := V_ROW.INDEX_NAME;
V_COLUMN_CNT := V_ROW.COLUMN_CNT;
V_INDEX_COLUMNS := V_ROW.INDEX_COLUMNS;
V_INDEX_TYPE := V_ROW.INDEX_TYPE;
V_UNIQUENESS := V_ROW.UNIQUENESS;
V_TABLESPACE_NAME := V_ROW.TABLESPACE_NAME;
V_PARTITIONED := V_ROW.PARTITIONED;
-- V_USE_YN := V_ROW.USE_YN;
-- INDEX 테이블에 추가
-- UX일때는 UNIQUE 인덱스
IF p_option = 'C' THEN
V_SQL := 'CREATE '||V_UNIQUENESS||' INDEX '||V_INDEX_OWNER||'.'||V_INDEX_NAME||' ON '||V_TABLE_OWNER||'.'||V_TABLE_NAME||
'( '
-- ||CASE WHEN V_INDEX_TYPE IN ('FUNCTION-BASED DOMAIN','FUNCTION-BASED NORMAL') THEN 'q''{' END
||V_INDEX_COLUMNS
-- ||CASE WHEN V_INDEX_TYPE IN ('FUNCTION-BASED DOMAIN','FUNCTION-BASED NORMAL') THEN '}''' END
||' ) TABLESPACE '||V_TABLESPACE_NAME;
ELSIF p_option = 'D' THEN
V_SQL := 'DROP INDEX '||V_INDEX_OWNER||'.'||V_INDEX_NAME;
ELSE
V_SQL := '[ERROR] p_option :'||p_option||' not supported';
END IF;
IF p_exec <> 0 THEN
EXECUTE IMMEDIATE V_SQL;
IF p_option = 'D' THEN
-- 인덱스 관리테이블 ROW 삭제
-- DELETE FROM TB_MGR_INDEX WHERE OWNER = V_TABLE_OWNER AND INDEX_NAME = V_INDEX_NAME;
-- COMMIT;
-- 테이블 전체 삭제
-- SP_DEL_MGR_INDEX(V_TABLE_OWNER,nvl(V_TABLE_OWNER,V_TABLE_OWNER),V_TABLE_NAME, V_INDEX_NAME, 'D',1);
SP_DEL_MGR_INDEX@DL_SCOTT_DEV_
V_INDEX_OWNER
, V_TABLE_OWNER
, V_TABLE_NAME
, V_INDEX_NAME
, 'D'
, 1
);
ELSE
-- 테이블 전체 입력
SP_INS_MGR_INDEX@DL_SCOTT_DEV_
V_INDEX_OWNER
, V_TABLE_OWNER
, V_TABLE_NAME
, V_INDEX_NAME
, V_UNIQUENESS
, V_INDEX_TYPE
, V_INDEX_COLUMNS
, V_COLUMN_CNT
, V_TABLESPACE_NAME
, V_PARTITIONED
);
END IF;
-- LOG 기록
INSERT INTO TB_MGR_INDEX_LOG A (
A.TABLE_OWNER
, A.TABLE_NAME
, A.INDEX_OWNER
, A.INDEX_NAME
, A.COLUMN_CNT
----[5]
, A.UNIQUENESS
, A.TABLESPACE_NAME
, A.INDEX_COLUMNS
, A.PARTITIONED
, A.P_OPTION
----[10]
, A.CREATED_SQL
) VALUES (
V_TABLE_OWNER
, V_TABLE_NAME
, V_INDEX_OWNER
, V_INDEX_NAME
, V_COLUMN_CNT
, V_UNIQUENESS
, V_TABLESPACE_NAME
, V_INDEX_COLUMNS
, V_PARTITIONED
, p_option
----[10]
, V_SQL
);
COMMIT;
dbms_output.enable(500);
dbms_output.put_line('[SUCESS] '||V_SQL);
ELSE
dbms_output.enable(100);
dbms_output.put_line('[SQL] '||V_SQL);
END IF;
END LOOP;
END IF;
EXCEPTION
WHEN OTHERS THEN
V_MSG := 'ERROR : ['|| to_char(SQLCODE) ||']'|| substr(SQLERRM,1,500);
-- LOG 기록
IF p_option <> 'M' THEN
INSERT INTO TB_MGR_INDEX_LOG A (
A.TABLE_OWNER
, A.TABLE_NAME
, A.INDEX_OWNER
, A.INDEX_NAME
, A.COLUMN_CNT
----[5]
, A.UNIQUENESS
, A.TABLESPACE_NAME
, A.INDEX_COLUMNS
, A.PARTITIONED
, A.P_OPTION
----[10]
, A.CREATED_SQL
) VALUES (
nvl(p_towner,p_iowner)
, p_tname
, p_iowner
, p_iname
, p_cols_cnt
----[5]
, p_uniq
, p_tsname
, p_cols
, p_part
, p_option
----[10]
, V_MSG||':'||V_SQL
);
COMMIT;
END IF;
END;
/