블룸필터 BLOOM FILTER
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
1 BLOOM FILTER의 이해와 활용법[편집]
notifications_active Bloom Filter 원리
- 어떤 원소가 집합에 속한다고 판단된 경우 실제로는 원소가 집합에 속하지 않는 긍정 오류가 발생하는 것이 가능하지만, 반대로 원소가 집합에 속하지 않는 것으로 판단되었는데 실제로는 원소가 집합에 속하는 부정 오류는 절대로 발생하지 않는다는 특성이 있다.
- 집합에 원소를 추가하는 것은 가능하나, 집합에서 원소를 삭제하는 것은 불가능하다.
- 집합 내 원소의 숫자가 증가할수록 긍정 오류 발생 확률도 증가한다.
- 예)
- ['aa', 'bb', 'cc', 'dd'] 라는 집합을 Bloom Filter를 이용해 저장하면 이 안에 'xx'라는 원소가 있는지 검사했을 때 있다고 얘기할 수도 있음(거짓 긍정,false positive)
- 하지만 'aa'라는 원소가 있는지 검사했을 때 없다(거짓 부정,false negative)고 나올 일은 절대 없다는 것.
- Bloom Filter 테스트하는 웹사이트
https://llimllib.github.io/bloomfilter-tutorial/
1.1 Bloom Filter 동작원리 이해[편집]
- 블랙 리스트 기반 IP주소 검색 및 차단의 예시
filter_1 1. x,y,z 라고 하는 IP를 블랙리스트에 저장(블름필터 생성)
filter_2 2. 블랙리스트의 IP를 찾는다고 가정(블름필터 탐색)
filter_3 3. Bloom Filter는 n비트 크기의 비트 배열구조와, 서로 다른 j개의 Hash함수를 사용하여 구현(해시함수는 n개 값을 균일하게 출력함)
filter_4 4. 블랙 리스트에 IP 주소 저장 순서(Bloom Filter 에 등록)
4-1. IP x를 가져와 3개의 해싱 함수(f1,f2,f3)로 해싱.
해싱함수별 해싱값 f1=1,f2=5,f3=13
4-2. 각 해싱값에 해당되는 해당 배열 인덱스 값을 0에서 1로 수정
4-3. 18(N)개의 비트 배열, 그리고 3(J)개의 해싱 함수 사용함.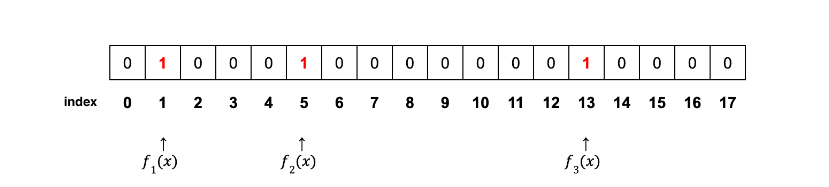
4-4. IP y로 4-1 ~ 4-3번 과정을 반복,
해싱함수별 해싱값 f1=4,f2=11,f3=16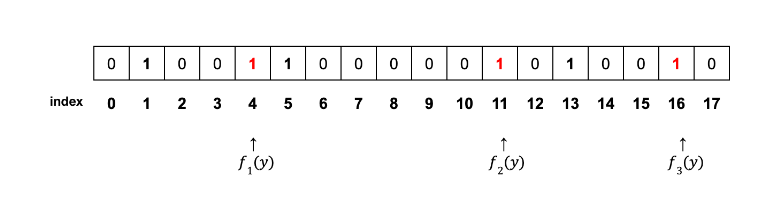
4-5. IP z로 4-1 ~ 4-3번 과정을 반복 (이전 인덱스 값이 0이 아닌 1인경우 수정없이 1로 유지)
, 해싱함수별 해싱값 f1=3,f2=5,f3=11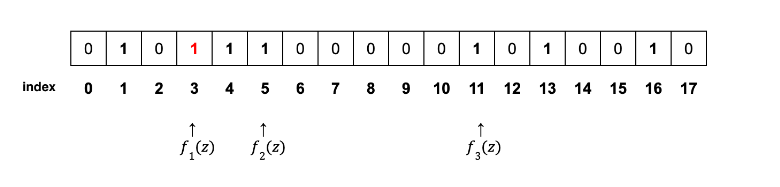
- 여기 까지가 블랙리스트 등록 끝.(오라클에서 선행테이블로 해시함수를 만든과정 완료)
filter_5 5. 이후 추가로 IP주소가 들어왔을때 필터링 하는 과정(오라클에서 조인후 탐색하는 과정)
5-1. w 라는 IP를 가진 패킷을 받음
5-2. IP w를 위의 방식과 같이 3개의 해싱 함수(f1,f2,f3)로 해싱,
f1=1,f2=13,f3=15 값이 나왔다면
5-3. 4,13 인덱스 값은 1이지만 15의 인덱스 값은 0 이므로
w라는 IP는 블랙 리스트 IP가 아님- Bloom Filter가 거짓 인데 참으로 판단하는 경우 - 거짓부정 => False Negative 는 발생하지 않지만 , 54 처럼 Hash함수는 참인데 연산결과 거짓인 경우 - 거짓긍정 => False Positive 발생하게 된다 .
- 문제는 거짓 긍정 (False positive) 가 많이 발생할수록 Bloom Filter 의 성능은 점점 떨어진다는 것. Bloom Filter 의 성능을 좋게 하기 위해선 False positive 를 줄여야 함
- False positive 를 줄이는 방법은 배열의 비트수를 늘리거나 hash 함수를 늘리는 방법 사용.
- 배열의 비트수 를 늘리면 memory 사용률이 올라가고 , hash 함수를 증가시키면 cpu 사용량이 올라 간다 .
2 오라클에서 Bloom Filter 활용법[편집]
assignment 오라클에서 사용되는 Bloom Filter 요약
- 구성요소가 집합의 구성원인지 점검하는데 사용되는 확률적 자료 구조
- 두 집합의 원소가 한쪽은 적고 한쪽은 많을때 , 조인하여 일치하는 교집합의 수는 적을 경우 탁월한 성능을 보임.
- 대용량 데이터를 조인 할 때 조인하는 대상을 미리 필터하여 줄여주는 효과
- Parallel Join , Hash Join ,Merge Join 시 발생함
- Join Filter Pruning 이나 Result Cache를 지원 하는데도 활용 됨
- 엑사데이터(EXADATA)에서 Bloom Filter 가 offloading 으로 처리 하도록 함으로써 , 데이터베이스 부하를 감소하는 중요한 요소.
2.1 오라클 블름필터를 이용한 대용량 데이터 튜닝[편집]
2.1.1 테스트용 테이블 생성 스크립트[편집]
create table emp_1
as
with a as
(select /*+ materialize */ level + 10000000 as empno,
chr(mod(level,90)) as big_ename, chr(mod(level,90)) as big_addr
from dual
connect by level <= 100000)
select empno,
lpad(big_ename, 3000,big_ename) as big_ename ,
lpad(big_addr, 3000,big_addr) as big_addr
from a ;
create table emp_2
as
select * from emp_1 ;
EXEC dbms_stats.gather_table_stats(user,'EMP_1');
EXEC dbms_stats.gather_table_stats(user,'EMP_2');2.1.2 실행계획 확인[편집]
explain plan for
SELECT /*+ full(t1) full(t2)
parallel(t1 8) parallel(t2 8)
leading(t1) use_hash(t2)
NO_PX_JOIN_FILTER(t2) */
*
FROM emp_1 t1,
emp_2 t2
WHERE t1.empno = T2.empno
and t1.BIG_ENAME > '1' ;- 병렬쿼리 이해
- TQ 는 processes간의 데이터를 주고받는 역활
- 하나의 TQ 는 여러개의 parallel Slave 를 가진다.
- - 아래 PLAN 상 TQ 가 3개(:TQ10000, :TQ10001, TQ10002 ) 생성됨
--------------------------------------------------------------------------------------
| Id | Operation | Name | Cost (%CPU)| TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12132 (1)| | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | 12132 (1)| Q1,02 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | 12132 (1)| Q1,02 | PCWP | |
| 4 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 3054 (0)| Q1,00 | P->P | HASH |
| 6 | PX BLOCK ITERATOR | | 3054 (0)| Q1,00 | PCWC | |
|* 7 | TABLE ACCESS FULL| EMP_1 | 3054 (0)| Q1,00 | PCWP | |
| 8 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 9 | PX SEND HASH | :TQ10001 | 3054 (0)| Q1,01 | P->P | HASH |
| 10 | PX BLOCK ITERATOR | | 3054 (0)| Q1,01 | PCWC | |
| 11 | TABLE ACCESS FULL| EMP_2 | 3054 (0)| Q1,01 | PCWP | |
--------------------------------------------------------------------------------------
- 각 Id 단위의 설명 :
- Q1,00 의 slave process 들은 emp_1 테이블을 full scan 하면서 t1.BIG_ENAME > '1' 조건을 FILTER 하였고 process 간의 통신을 위하여 걸러진 데이터를 Q1,02 에 보낸다.(Id5~7)
- Q1,02 의 slave process 들은 1번에서 받은 데이터들을 이용해 hash table 을 만든다.(Id3~4)
- Q1,01 의 slave process 들은 emp_1 테이블을 full scan 하고 읽은 데이터를 Q1,02 에 보낸다.(ID9~11)
- Q1,02 의 slave process 들은 3번에서 던진 데이터를 받아서 미리 만들어진 hash 테이블을 검색하면서 조인작업을 진행하고 결과를 Query Cordinator 에 보낸다.(Id2~3)
- Query Cordinator 는 각 TQ 로 부터 데이터를 받아서 취합한후에 결과를 Return 한다.(Id0~1)
- Q1,01 의 모든 SLAVE 들은 Q1,02 의 모든 SLAVE 들에게 똑같은 데이터를 던져서 체크한후에 만족하면 조인에 성공하고 그렇지 않으면 조인에 실패하는 비효율적인 프로세스를 가지게 된다. 위쿼리를 예를들면 사번 10000100을 Q1,02 의 SLAVE 가 8개라면 8번 던져서 1/8 확률로 조인에 성공하면 다행이지만 아예 조인에 실패할 확률도 있는것이다.
- - 이런 비효율을 없애는 것이 Parallel Join Filter 이다.
- Parallel Join Filter 의 개념은 Q1,01(후행테이블의 TQ) 이 Q1,02에게 데이터를 전달하기전에 불필요한 데이터를 걸러 낸다는 것이다.
2.1.3 parallel join filter 적용[편집]
explain plan for
SELECT /*+ full(t1) full(t2)
parallel(t1 8) parallel(t2 8)
leading(t1) use_hash(t2)
PX_JOIN_FILTER(t2)
*/
*
FROM emp_1 t1,
emp_2 t2
WHERE t1.empno = T2.empno
and t1.BIG_ENAME > '1' ;- 주의 해야할 사항
- t1.ename > '1' 등 t1 의 filter predicate 가 없으면 Parallel Join Filter 는 결코 작동하지 않는다.그럴때는 t1.empno > 0 등의 결과값의 영향을 끼치지 않는 filter 조건을 주는 트릭 사용
- 또하나의 주의 해야할 사항은 PX_JOIN_FILTER 사용시 후행테이블을 사용하여야 한다는것.왜냐하면 아래의 PLAN 을 보면 Filter 의 생성은 t1 에서 하지만(id4), 사용은 t2 쪽(id11)에서 하기때문에 PX_JOIN_FILTER(t1) 을 주면 절대 filter operation 이 생기지 않는다.
---------------------------------------------------------------------------------------
| Id | Operation | Name | Cost (%CPU)| TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12132 (1)| | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | 12132 (1)| Q1,02 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | 12132 (1)| Q1,02 | PCWP | |
| 4 | PX JOIN FILTER CREATE| :BF0000 | 3054 (0)| Q1,02 | PCWP | |
| 5 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 3054 (0)| Q1,00 | P->P | HASH |
| 7 | PX BLOCK ITERATOR | | 3054 (0)| Q1,00 | PCWC | |
|* 8 | TABLE ACCESS FULL| EMP_1 | 3054 (0)| Q1,00 | PCWP | |
| 9 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 10 | PX SEND HASH | :TQ10001 | 3054 (0)| Q1,01 | P->P | HASH |
| 11 | PX JOIN FILTER USE | :BF0000 | 3054 (0)| Q1,01 | PCWP | |
| 12 | PX BLOCK ITERATOR | | 3054 (0)| Q1,01 | PCWC | |
| 13 | TABLE ACCESS FULL| EMP_2 | 3054 (0)| Q1,01 | PCWP | |
---------------------------------------------------------------------------------------- id 4 에서 parallel Join filter 를 생성(create) 하였고 filter 명은 :BF0000 이다.
- id 11 에서 생성된 :BF0000 filter 를 사용하였다.
notifications_active Parallel Join filter 를 사용 하면 좋은 경우
- 많은양의 데이터가 조인에 실패하는경우
- 1번을 만족하면서 RAC 에서 multi-node 로 Parallel Query 를 실행한경우.이경우는 대부분 DOP(Degree Of Parallelism)가 클때 발생하며 추가적인 Network I/O 가 발생하므로 Parallel join filter 를 적용할경우 획기적인 성능향상을 기대할수 있다.
2.2 오라클 Bloom Filter 의 작동 요건[편집]
- Parallel Join 과 Partition Table Join 시 조인 이전에 대상건수를 줄여 성능을 최적화 하는 역할.
- 관련 힌트 : PX_JOIN_FILTER / NO_PX_JOIN_FILTER
notifications_active 오라클 Bloom Filter 의 작동 요건
- 반드시 Hash Join 또는 Merge Join 시에만 적용됨
- Partition Table 조인이어야 한다 ( 조인 Key 는 Partition Key 여야 한다 ).
- Partition Table 조인이 아닌 경우라면 , Parallel Query 여야 함.
- Parallel Query 도 아니고 Partition Table 도 아닌 경우 라도 Inline View 안에 Group by절이 포함된 경우 Bloom Filter를 사용할 수 있다
- 이때, 조인 칼럼 은 Group by 절에 사용된 칼럼 이어야 한다
- 주의 할 점) Parallel Query 에서 위 조건을 만족하고 , Bloom Filter 를 사용하도록 힌트를 사용하였어도 "선행 테이블에 대한 상수 조건이 없을 경우에는 Bloom Filter 가 사용되지 않는다" 는 것.
- Bloom Filter 를 사용하는 것이 효율적이라 판단 되면 , Dummy 조건을 추가 하여 강제로 Bloom Filter 로 유도할 수 있다 .
- 작동요건이 만족되고 힌트까지 부여해도 선행 집합에 상수 조건이 없다고 Bloom Filter가 작동되지 않는것은 성능적으로 않좋기 때문임.
2.3 선행집합에 상수 조건이 없다면 Bloom Filter가 작동되지 않는 이유[편집]
- Bloom Filter 사용시 선행 테이블은 Filter 집합을 만드는데 사용됨
- 예를 들어 아무 조건이 없는경우 , 추출된 집합에 1~10 까지의 데이터가 포함되어 있다고 가정하고, 비트 배열의 크기가 10 이라면 , 10 개의 배열 모두 1 로 세팅 될 것이다.
- 즉, 모든 데이터가 false positive 가 발생함으로써 , 조인 이전에 데이터를 미리 걸러 내는 효과가 없음.
- 즉 선행테이블에 조건이 없다면 , 많은 양의 데이터가 추출 될 것이고 , 이로 인해 비트배열의 대부분이 1 로 마킹 됨으로써 Bloom Filter 의 효율이 떨어질 가능성이 크다는 것.
2.4 Bloom Filter 장점[편집]
- Hash Join 이나 Merge Join 을 하기에 젼에 조인 대상건수를 미리 줄여서 Join 의 부하를 감소 시킴.
- Parallel Processing 의 경우 Slave 에서 조인을 하기 위해 Coordinate 로 전송하는 통신량 감소, 조인시 의 부하 감소 시킴 .
- 엑사테이터에서 Bloom Filter 를 offloading 으로 처리하여 Cell Server 의 CPU 를 사용 해 DB 서버에 CPU 부하 를 감소 시킴 .
2.5 Bloom Filter 단점[편집]
- False positive 발생 빈도가 높을 경우 , 오히려 더 비효율적임.
2.6 Bloom Filter 모니터링 - V$SQL_JOIN_FILTER[편집]
- 우선 Parallel Processing이 되는지 확인
- DBMS_XPLAN 의 Predicate Information 을 통해 Bloom Filter 의 사용 여부는 알 수 있지만 , 실제 작업은 각각의 Slave Process가 하므로 실제적인 일량을 알수 없어 모니터링 불가 따라서 Parallel 을 사용한 경우에는 V$SQL_JOIN_FILTER View 를 통해 관찰 해야 한다 .
- V$SQL_JOIN_FILTER 뷰로 확인
select qc_session_id
, sql_plan_hash_value
, filtered
, probed
, probed - filtered AS send
FROM V$SQL_JOIN_FILTER
WHERE qc_session_id = 21- FILTERED : Bloom Filter 를 통해 제거된 Row 를 의미
- PROBED : 전체 대상을 의미.
- FILTERED 와 PROBED 의 수치가 비슷할수록 효율이 높다고 판단.
- 예를 들언 전체 PROBED 집합 대상은 10 만건인데 , 그 중 Bloom Filter 로 99,993 건을 걸러낸 후 7 건의 데이터만 Coordinate 에게 전송한 후 조인 연산을 했다면 필터링 효율이 높은것임.
- 주의사항) V$SQL_JOIN_FILTER 성능뷰는 Parallel SQL 에 대해서만 성능이 수집된다는 것
- Partition Join Pruning 의 경우에는 해당 뷰에 정보가 남지 않으므로 이때 는 DBMS_XPLAN 이나 Trace 결과를 통해 효율성을 모니터링 해야함.
참조: https://dataonair.or.kr/db-tech-reference/d-lounge/technical-data/?mod=document&uid=235922