"인덱스 구조"의 두 판 사이의 차이
DB CAFE
(→INDEX FAST FULL SCAN) |
(→인덱스를 사용 할수 없는 경우) |
||
| (같은 사용자의 중간 판 31개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
| − | = 인덱스 | + | = 인덱스 개념/아키텍처 = |
== B+Tree 인덱스 장점 == | == B+Tree 인덱스 장점 == | ||
# 인덱스를 이용해 데이터에 엑세스할 때 모든 인덱스 엔트리에 대해 균형(Balance)을 맞춤 | # 인덱스를 이용해 데이터에 엑세스할 때 모든 인덱스 엔트리에 대해 균형(Balance)을 맞춤 | ||
# 인덱스를 이용한 범위(Range) 스캔 시 Double Linked List를 사용하기 때문에 다른 인덱스보다 더 유리하며 ACESENDING과 DESCENDING도 가능함 | # 인덱스를 이용한 범위(Range) 스캔 시 Double Linked List를 사용하기 때문에 다른 인덱스보다 더 유리하며 ACESENDING과 DESCENDING도 가능함 | ||
# OLTP 환경에서 적은 데이터에 엑세스하는 데 유리함 | # OLTP 환경에서 적은 데이터에 엑세스하는 데 유리함 | ||
| + | ---- | ||
| + | |||
== B+Tree 인덱스 단점 == | == B+Tree 인덱스 단점 == | ||
# 분포도(Cardinality)가 낮은 컬럼의 경우 B*TREE 인덱스가 불리함 | # 분포도(Cardinality)가 낮은 컬럼의 경우 B*TREE 인덱스가 불리함 | ||
| 9번째 줄: | 11번째 줄: | ||
# 인덱스 연산 불가 | # 인덱스 연산 불가 | ||
# 인덱스 확장 시 부하 발생 | # 인덱스 확장 시 부하 발생 | ||
| + | ---- | ||
== 인덱스 오퍼레이션 == | == 인덱스 오퍼레이션 == | ||
| 41번째 줄: | 44번째 줄: | ||
# leaf node 간에는 링크드 리스트(linked list)로 연결되어 있어 여러 값을 스캔할 때 유리하다. | # leaf node 간에는 링크드 리스트(linked list)로 연결되어 있어 여러 값을 스캔할 때 유리하다. | ||
# leaf node 는 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다. | # leaf node 는 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다. | ||
| − | + | ---- | |
| − | + | ---- | |
| − | |||
== 인덱스 스캔 방식 == | == 인덱스 스캔 방식 == | ||
| 61번째 줄: | 63번째 줄: | ||
=== INDEX FULL SCAN === | === INDEX FULL SCAN === | ||
https://dataonair.or.kr/publishing/img/knowledge/SQL_332.jpg | https://dataonair.or.kr/publishing/img/knowledge/SQL_332.jpg | ||
| − | + | {{틀:고지상자2 | |
| + | |제목=INDEX FULL SCAN이 사용되는 경우 | ||
| + | |내용=# Index Full Scan은 수직적 탐색 없이 수평적 탐색(인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식)으로서, 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택 | ||
# 인덱스 선두 칼럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려 | # 인덱스 선두 칼럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려 | ||
| − | # | + | # 대용량 테이블인 경우 Table Full Scan의 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 검토한다. |
| − | # 데이터 저장공간은 | + | # 데이터 저장공간은 "칼럼길이×레코드수" 에 의해 결정되므로 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적음. |
| − | # 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 테이블 전체를 스캔하는 것보다 낫다. | + | # 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 I/O 측면에서 테이블 전체를 스캔하는 것보다 낫다. |
| − | # 이럴 때 옵티마이저는 Index Full Scan 방식을 선택할 수 있다. | + | # 인덱스를 이용한 소트 연산 대체 : 옵티마이저는 소트 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 방식을 선택 |
| + | * 이럴 때 옵티마이저는 Index Full Scan 방식을 선택할 수 있다. | ||
| + | }} | ||
| + | |||
| + | <source lang=sql> | ||
| + | select /*+ first_rows * / * from emp | ||
| + | where sal > 1000 | ||
| + | order by ename ; | ||
| + | |||
| + | -- 인덱스 생성 (ename + sal ) | ||
| + | create index emp_idx03 on emp(ename,sal); | ||
| + | |||
| + | select /*+ first_rows */ * from emp | ||
| + | where sal > 1000 | ||
| + | order by ename ; | ||
| + | |||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 12 |00:00:00.01 | 4 | | ||
| + | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 13 | 12 |00:00:00.01 | 4 | | ||
| + | |* 2 | INDEX FULL SCAN | EMP_IDX03 | 1 | 13 | 12 |00:00:00.01 | 2 | | ||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | |||
| + | Predicate Information (identified by operation id): | ||
| + | --------------------------------------------------- | ||
| + | |||
| + | 2 - access("SAL">1000) | ||
| + | filter("SAL">1000) | ||
| + | |||
| + | |||
| + | </source> | ||
=== INDEX FAST FULL SCAN === | === INDEX FAST FULL SCAN === | ||
* Index Fast Full Scan은 Index Full Scan보다 빠르다. | * Index Fast Full Scan은 Index Full Scan보다 빠르다. | ||
# Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다. | # Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다. | ||
| + | # Index Full Scan과 Fast Full Scan 비교 | ||
| + | {| class="wikitable" | ||
| + | |- | ||
| + | ! INDEX FULL SCAN !! INDEX FAST FULL SCAN | ||
| + | |- | ||
| + | | 1. 인덱스 구조를 따라 스캔|| 1. 세그먼트 전체를 스캔 | ||
| + | |- | ||
| + | | 2. 결과집합 순서 보장|| 2. 결과집합 순서 보장 안 됨 | ||
| + | |- | ||
| + | | 3. Single Block I/O|| 3. Multiblock I/O | ||
| + | |- | ||
| + | | 4. 병렬스캔 불가(파티션 돼 있지 않다면)|| 4. 병렬스캔 가능 | ||
| + | |- | ||
| + | | 5. 인덱스에 포함되지 않은 칼럼 조회 시에도 사용 가능|| 5. 인덱스에 포함된 칼럼으로만 조회할 때 사용 가능 | ||
| + | |} | ||
=== INDEX UNIQUE SCAN === | === INDEX UNIQUE SCAN === | ||
| + | https://dataonair.or.kr/publishing/img/knowledge/SQL_335.jpg | ||
| + | * 수직적 탐색만으로 데이터를 찾는 스캔 방식으로서, Unique 인덱스를 ‘=’ 조건으로 탐색하는 경우에 작동한다. | ||
=== INDEX SKIP SCAN === | === INDEX SKIP SCAN === | ||
| + | https://dataonair.or.kr/publishing/img/knowledge/SQL_336.jpg | ||
| + | * 인덱스 선두 칼럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다. | ||
| + | * Oracle은 인덱스 선두 칼럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식을 9i 버전에서 선보였는데, 바로 Index Skip Scan이 그것이다. | ||
| + | # Index Skip Scan 내부 수행원리는 루트 또는 브랜치 블록에서 읽은 칼럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 “가능성이 있는” 하위 블록(브랜치 또는 리프 블록)만 골라서 액세스하는 방식이라고 할 수 있다. | ||
| + | # 이 스캔 방식은 조건절에 빠진 인덱스 선두 칼럼의 Distinct Value 개수가 적고 후행 칼럼의 Distinct Value 개수가 많을 때 유용하다. | ||
| + | |||
| + | ---- | ||
| + | == 인덱스 종류 == | ||
| + | === 압축된 인덱스 Compressed Index === | ||
| + | === 리버스키 인덱스 Reverse-key Index === | ||
| + | === 함수형 인덱스 Function-based Index === | ||
| + | === Linguistic Index === | ||
| + | === Text Index === | ||
| + | ---- | ||
| + | == 오라클 인덱스의 특징 == | ||
| + | # Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다. | ||
| + | #: 즉, 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다. | ||
| + | # 테이블 레코드값이 갱신되면 리프노드 인덱스 키값도 갱신된다. 반면 리프노드상의 엔트리값이 갱신되더라고 보랜치 노드까지 값이 바뀌지는 않는다. | ||
| + | # 브랜치 노드는 인덱스 분할에 의해 새로운 블록이 추가되거나 삭제 될때만 갱신된다. (브랜치 노드상의 키값은 하위 노드가 갖는 값의 범위를 의미) | ||
| + | ---- | ||
| + | |||
| + | === 인덱스를 사용 할수 없는 경우 === | ||
| + | ==== 인덱스 사용이 불가능하거나 범위 스캔이 불가능한 경우 ==== | ||
| + | * 인덱스 구성 정보조회 | ||
| + | <source lang=sql> | ||
| + | select INDEX_OWNER,INDEX_NAME,TABLE_OWNER,TABLE_NAME,COLUMN_NAME | ||
| + | from ALL_IND_COLUMNS | ||
| + | where table_name ='EMP' | ||
| + | |||
| + | INDEX_OWNER INDEX_NAME TABLE_OWNER TABLE_NAME COLUMN_NAME | ||
| + | ------------------------------ ------------------------------ ------------------------------ ------------------------------ --------------- | ||
| + | SCOTT PK_EMP SCOTT EMP EMPNO | ||
| + | ------------------------------------------------------------------------------------------------------------------------------------------- | ||
| + | |||
| + | </source> | ||
| + | * 1. empno 컬럼을 가공한 경우 | ||
| + | <source lang=sql> | ||
| + | select * | ||
| + | from emp | ||
| + | where substr(empno,1,2) = 7369 | ||
| + | |||
| + | </source> | ||
| + | * 2. empno 컬럼이 <> 으로 사용된경우 | ||
| + | <source lang=sql> | ||
| + | select * | ||
| + | from emp | ||
| + | where empno <> 7369 | ||
| + | </source> | ||
| + | |||
| + | * 3. empno 컬럼이 is not null 로 사용된 경우 | ||
| + | <source lang=sql> | ||
| + | select * | ||
| + | from emp | ||
| + | where empno is not null | ||
| + | |||
| + | |||
| + | ------------------------------------------------------------------------------------ | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | ------------------------------------------------------------------------------------ | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 7 | | ||
| + | |* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 0 |00:00:00.01 | 7 | | ||
| + | ------------------------------------------------------------------------------------ | ||
| + | |||
| + | </source> | ||
| + | |||
| + | ==== 인덱스 컬럼 가공 사례 ==== | ||
| + | {{틀:고지상자2 | ||
| + | |제목=인텍스 컬럼을 수정(가공) 하면 안되는 이유 | ||
| + | |내용=인덱스 컬럼을 수정하는 경우 '''범위 스캔을 위한 시작점'''을 찾을 수 없어서 옵티마이저는 인덱스 전체를 스캔(INDEX FULL SCAN) 하거나 테이블 전체를 스캔(FULL TABLE SCAN)하는 방식을 취한다. | ||
| + | }} | ||
| + | * 컬럼을 가공한 경우 SQL 변경을 통한 성능 개선 방법 | ||
| + | |||
| + | http://wiki.gurubee.net/download/attachments/29065492/%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%BB%AC%EB%9F%BC%EC%9D%98%EA%B0%80%EA%B3%B5.JPG | ||
| + | |||
| + | [[Category:oracle]] | ||
| + | |||
| + | == 인텍스 튜닝 방안 == | ||
| + | |||
| + | === '''is null 조건'''을 사용하더라도 다른컬럼의 조건이 하나라도 있으면 range scan가능 === | ||
| + | <source lang=sql> | ||
| + | -- depotno 컬럼을 2번째 항목으로 추가 | ||
| + | create index emp_idx on emp(job,deptno); | ||
| + | |||
| + | select * | ||
| + | from emp | ||
| + | where job is null | ||
| + | and deptno =20; <= job은 null 이지만 deptno가 20인 조건으로 range scan이 가능함. | ||
| + | |||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 | | ||
| + | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 | | ||
| + | |* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | 1 | 0 |00:00:00.01 | 1 | | ||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | |||
| + | Predicate Information (identified by operation id): | ||
| + | --------------------------------------------------- | ||
| + | |||
| + | 2 - access("JOB" IS NULL AND "DEPTNO"=20) | ||
| + | filter("DEPTNO"=20) | ||
| + | </source> | ||
| + | |||
| + | === 함수기반 인덱스 사용 === | ||
| + | <source lang=sql> | ||
| + | -- v_deptno 문자형 타입으로 컬럼 추가 | ||
| + | alter table emp add v_deptno varchar2(2); | ||
| + | |||
| + | update emp set v_deptno = deptno; | ||
| + | |||
| + | Process Time: 0.0194 sec | ||
| + | 14 row(s) affected; | ||
| + | -- 인덱스 생성 | ||
| + | create index emp_x01 on emp(v_deptno); | ||
| + | |||
| + | -- 숫자형 타입으로 조회 하면 인덱스가 사용되지 않음. | ||
| + | select * from emp where v_deptno =20; | ||
| + | |||
| + | ------------------------------------------------------------------------------------ | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | ------------------------------------------------------------------------------------ | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 8 | | ||
| + | |* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 5 |00:00:00.01 | 8 | | ||
| + | ------------------------------------------------------------------------------------ | ||
| + | |||
| + | Predicate Information (identified by operation id): | ||
| + | --------------------------------------------------- | ||
| + | |||
| + | 1 - filter(TO_NUMBER("V_DEPTNO")=20) | ||
| + | </source> | ||
| + | |||
| + | * TO_NUMBER("V_DEPTNO") 를 사용하여 함수형 인덱스 생성 | ||
| + | |||
| + | <source lang=sql> | ||
| + | create index emp_x02 on emp(TO_NUMBER("V_DEPTNO")); | ||
| + | |||
| + | select * from emp where v_deptno =20; | ||
| + | |||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 4 | | ||
| + | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 5 |00:00:00.01 | 4 | | ||
| + | |* 2 | INDEX RANGE SCAN | EMP_X02 | 1 | 1 | 5 |00:00:00.01 | 2 | | ||
| + | ------------------------------------------------------------------------------------------------- | ||
| + | |||
| + | Predicate Information (identified by operation id): | ||
| + | --------------------------------------------------- | ||
| + | |||
| + | 2 - access("EMP"."SYS_NC00011$"=20) | ||
| + | </source> | ||
| + | |||
| + | === null 허용케이스 === | ||
| + | <source lang=sql> | ||
| + | create index emp_fbi01 on emp(mgr,''); | ||
| + | |||
| + | select * | ||
| + | from emp | ||
| + | where mgr is null; | ||
| + | |||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | ||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | | 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 | | ||
| + | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 | | ||
| + | |* 2 | INDEX RANGE SCAN | EMP_FBI01 | 1 | 1 | 0 |00:00:00.01 | 1 | | ||
| + | --------------------------------------------------------------------------------------------------- | ||
| + | |||
| + | Predicate Information (identified by operation id): | ||
| + | --------------------------------------------------- | ||
| + | |||
| + | 2 - access("MGR" IS NULL) | ||
| + | </source> | ||
2024년 1월 19일 (금) 10:11 기준 최신판
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 인덱스 개념/아키텍처[편집]
1.1 B+Tree 인덱스 장점[편집]
- 인덱스를 이용해 데이터에 엑세스할 때 모든 인덱스 엔트리에 대해 균형(Balance)을 맞춤
- 인덱스를 이용한 범위(Range) 스캔 시 Double Linked List를 사용하기 때문에 다른 인덱스보다 더 유리하며 ACESENDING과 DESCENDING도 가능함
- OLTP 환경에서 적은 데이터에 엑세스하는 데 유리함
1.2 B+Tree 인덱스 단점[편집]
- 분포도(Cardinality)가 낮은 컬럼의 경우 B*TREE 인덱스가 불리함
- OR 연산자에 대해 테이블 전체를 스캔(Full Scan)하는 것은 위험함
- 인덱스 연산 불가
- 인덱스 확장 시 부하 발생
1.3 인덱스 오퍼레이션[편집]
1.3.1 추가 Insert Operation[편집]
- 테이블에 데이터가 추가되면 해당 테이블에 존재하는 인덱스에도 추가된 데이터의 인덱스 엔트리가 추가된다.
- 테이블에 추가되는 데이터의 인덱스 키(Key) 값의 저장 위치를 찾기 위해 인덱스 리프 블록을 확인해 찾는다.
- 그리고 인덱스 블록의 여유 공간에 해당 인덱스 엔트리를 추가한다.
- 해당 인덱스 블록에 여유 공간이 없을 경우, 해당 블록은 2개의 인덱스 리프 블록으로 분기돼 인덱스 키들은 다시 정렬되고
- 분기된 2개의 인덱스 리프 블록을 통해 추가된다. 이 때 리프 블록을 연결하고 있는 브랜치 블록과 루트 블록의 정보가 갱신될 수 있다.
1.3.2 삭제 Delete Operation[편집]
- Insert Operation과 정반대의 작업을 수행한다.
- 데이터가 삭제되면 해당 인덱스 엔트리의 연결이 끊어진다.
- 그렇게 함으로써 루트 블록으로부터 해당 인덱스 엔트리를 인식하지 못하게 한다.
- 삭제된 인덱스 엔트리의 공간은 추가를 위해 공간 해제를 수행하게 되며, 리프 블록에 하나의 인덱스 엔트리라도 남게 되면 인덱스 리프 블록은 유지되게 된다.
- 많은 인덱스 엔트리가 삭제되면 삭제된 공간은 반납된다.
- 그러나 해당 리프 블록의 전체 데이터가 삭제되지 않는 한 해당 리프 블록은 반납되지 않는다.
- 해당 리프 블록에 새로운 인덱스 엔트리가 추가로 저장되지 않는다면 공간이 낭비되게 된다.
1.3.3 갱신 Update Operation[편집]
- 삭제와 추가 작업이 동시에 수행되는 작업이다.
- 테이블에 데이터가 순차적으로 증가해 추가되는 경우 인덱스의 우측으로 인덱스 엔트리가 집중돼 B*TREE의 가장 중요한 특징인 균형(Balance)이 무너지게 된다.
- 또한 죄측 리프 블록으로 인덱스 엔트리가 추가되지 않기 때문에 좌측 리프 블록은 "블록 사용률" 이 낮아지게 된다.
- 삭제가 많거나 또는 인덱스 키가 순차적으로 증가하며 추가되는 테이블은 주기적인 인덱스 재구성(Rebuild)을 통해 인덱스 균형(Balance)을 유지시켜줘야 한다.
1.4 인덱스 구조[편집]
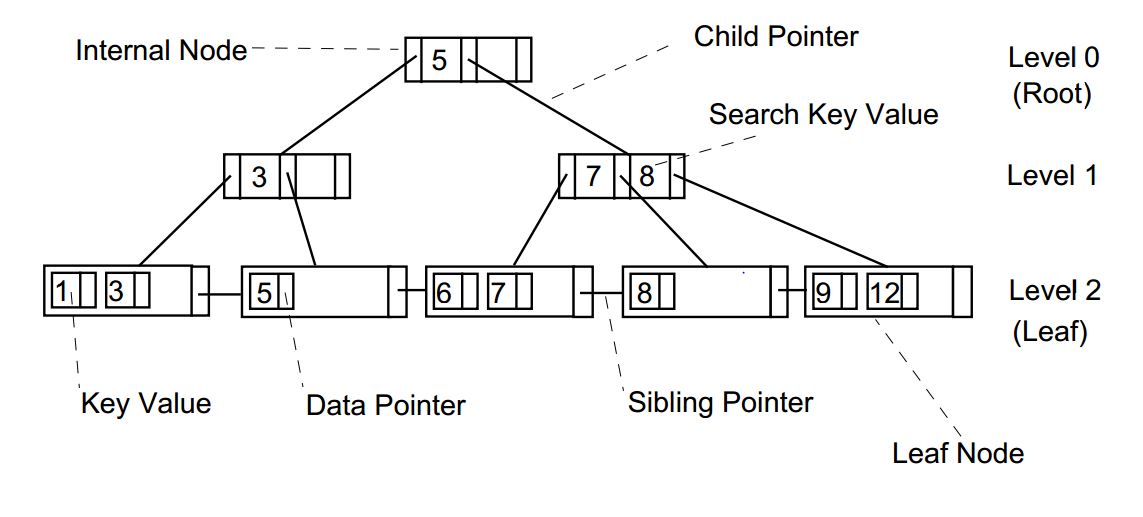
- B*tree는 leaf node 와 non-leaf 로 구성
- leaf node 부터 root node 까지의 길이는 모든 리프가 동일하다는 특징을 가지고 있다.
- 즉, 모든 리프 노드의 레벨은 동일하다.
- leaf node 간에는 링크드 리스트(linked list)로 연결되어 있어 여러 값을 스캔할 때 유리하다.
- leaf node 는 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다.
1.5 인덱스 스캔 방식[편집]
1.5.1 INDEX RANGE SCAN[편집]
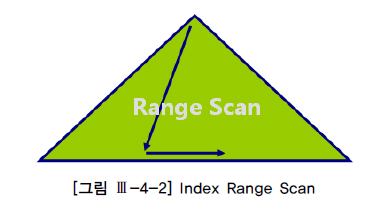
- 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위(Range)만 스캔하는 방식
- 실행계획 상에 Index Range Scan이 나타난다고 해서 항상 빠른 속도를 보장하는 것은 아님
- 인덱스를 스캔하는 범위(Range)를 얼마만큼 줄일 수 있느냐, 그리고 테이블로 액세스하는 횟수를 얼마만큼 줄일 수 있느냐가 튜닝의 관건
- Index Range Scan이 가능하게 하려면 인덱스를 구성하는 선두 칼럼이 조건절에 사용되어야 함.
- Index Range Scan 과정을 거쳐 생성된 결과집합은 인덱스 칼럼 순으로 정렬된 상태가 되기 때문에 이런 특징을 잘 이용하면 sort order by 연산을 생략하거나 min/max 값을 빠르게 추출할 수 있다.
1.5.2 INDEX FULL SCAN[편집]
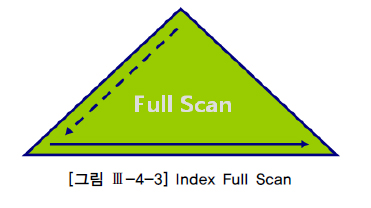
notifications_active INDEX FULL SCAN이 사용되는 경우
- Index Full Scan은 수직적 탐색 없이 수평적 탐색(인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식)으로서, 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택
- 인덱스 선두 칼럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려
- 대용량 테이블인 경우 Table Full Scan의 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 검토한다.
- 데이터 저장공간은 "칼럼길이×레코드수" 에 의해 결정되므로 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적음.
- 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 I/O 측면에서 테이블 전체를 스캔하는 것보다 낫다.
- 인덱스를 이용한 소트 연산 대체 : 옵티마이저는 소트 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 방식을 선택
- 이럴 때 옵티마이저는 Index Full Scan 방식을 선택할 수 있다.
select /*+ first_rows * / * from emp
where sal > 1000
order by ename ;
-- 인덱스 생성 (ename + sal )
create index emp_idx03 on emp(ename,sal);
select /*+ first_rows */ * from emp
where sal > 1000
order by ename ;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 12 |00:00:00.01 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 13 | 12 |00:00:00.01 | 4 |
|* 2 | INDEX FULL SCAN | EMP_IDX03 | 1 | 13 | 12 |00:00:00.01 | 2 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SAL">1000)
filter("SAL">1000)1.5.3 INDEX FAST FULL SCAN[편집]
- Index Fast Full Scan은 Index Full Scan보다 빠르다.
- Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다.
- Index Full Scan과 Fast Full Scan 비교
| INDEX FULL SCAN | INDEX FAST FULL SCAN |
|---|---|
| 1. 인덱스 구조를 따라 스캔 | 1. 세그먼트 전체를 스캔 |
| 2. 결과집합 순서 보장 | 2. 결과집합 순서 보장 안 됨 |
| 3. Single Block I/O | 3. Multiblock I/O |
| 4. 병렬스캔 불가(파티션 돼 있지 않다면) | 4. 병렬스캔 가능 |
| 5. 인덱스에 포함되지 않은 칼럼 조회 시에도 사용 가능 | 5. 인덱스에 포함된 칼럼으로만 조회할 때 사용 가능 |
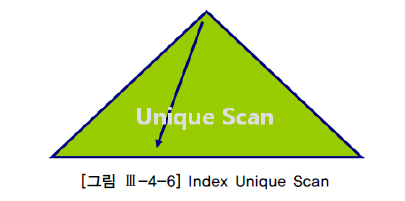
1.5.5 INDEX SKIP SCAN[편집]
- 인덱스 선두 칼럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다.
- Oracle은 인덱스 선두 칼럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식을 9i 버전에서 선보였는데, 바로 Index Skip Scan이 그것이다.
- Index Skip Scan 내부 수행원리는 루트 또는 브랜치 블록에서 읽은 칼럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 “가능성이 있는” 하위 블록(브랜치 또는 리프 블록)만 골라서 액세스하는 방식이라고 할 수 있다.
- 이 스캔 방식은 조건절에 빠진 인덱스 선두 칼럼의 Distinct Value 개수가 적고 후행 칼럼의 Distinct Value 개수가 많을 때 유용하다.
1.6 인덱스 종류[편집]
1.6.1 압축된 인덱스 Compressed Index[편집]
1.6.2 리버스키 인덱스 Reverse-key Index[편집]
1.6.3 함수형 인덱스 Function-based Index[편집]
1.6.4 Linguistic Index[편집]
1.6.5 Text Index[편집]
1.7 오라클 인덱스의 특징[편집]
- Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다.
- 즉, 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다.
- 테이블 레코드값이 갱신되면 리프노드 인덱스 키값도 갱신된다. 반면 리프노드상의 엔트리값이 갱신되더라고 보랜치 노드까지 값이 바뀌지는 않는다.
- 브랜치 노드는 인덱스 분할에 의해 새로운 블록이 추가되거나 삭제 될때만 갱신된다. (브랜치 노드상의 키값은 하위 노드가 갖는 값의 범위를 의미)
1.7.1 인덱스를 사용 할수 없는 경우[편집]
1.7.1.1 인덱스 사용이 불가능하거나 범위 스캔이 불가능한 경우[편집]
- 인덱스 구성 정보조회
select INDEX_OWNER,INDEX_NAME,TABLE_OWNER,TABLE_NAME,COLUMN_NAME
from ALL_IND_COLUMNS
where table_name ='EMP'
INDEX_OWNER INDEX_NAME TABLE_OWNER TABLE_NAME COLUMN_NAME
------------------------------ ------------------------------ ------------------------------ ------------------------------ ---------------
SCOTT PK_EMP SCOTT EMP EMPNO
-------------------------------------------------------------------------------------------------------------------------------------------- 1. empno 컬럼을 가공한 경우
select *
from emp
where substr(empno,1,2) = 7369- 2. empno 컬럼이 <> 으로 사용된경우
select *
from emp
where empno <> 7369- 3. empno 컬럼이 is not null 로 사용된 경우
select *
from emp
where empno is not null
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 7 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 0 |00:00:00.01 | 7 |
------------------------------------------------------------------------------------1.7.1.2 인덱스 컬럼 가공 사례[편집]
notifications_active 인텍스 컬럼을 수정(가공) 하면 안되는 이유
인덱스 컬럼을 수정하는 경우 범위 스캔을 위한 시작점을 찾을 수 없어서 옵티마이저는 인덱스 전체를 스캔(INDEX FULL SCAN) 하거나 테이블 전체를 스캔(FULL TABLE SCAN)하는 방식을 취한다.
- 컬럼을 가공한 경우 SQL 변경을 통한 성능 개선 방법

1.8 인텍스 튜닝 방안[편집]
1.8.1 is null 조건을 사용하더라도 다른컬럼의 조건이 하나라도 있으면 range scan가능[편집]
-- depotno 컬럼을 2번째 항목으로 추가
create index emp_idx on emp(job,deptno);
select *
from emp
where job is null
and deptno =20; <= job은 null 이지만 deptno가 20인 조건으로 range scan이 가능함.
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | 1 | 0 |00:00:00.01 | 1 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("JOB" IS NULL AND "DEPTNO"=20)
filter("DEPTNO"=20)1.8.2 함수기반 인덱스 사용[편집]
-- v_deptno 문자형 타입으로 컬럼 추가
alter table emp add v_deptno varchar2(2);
update emp set v_deptno = deptno;
Process Time: 0.0194 sec
14 row(s) affected;
-- 인덱스 생성
create index emp_x01 on emp(v_deptno);
-- 숫자형 타입으로 조회 하면 인덱스가 사용되지 않음.
select * from emp where v_deptno =20;
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 8 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 5 |00:00:00.01 | 8 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_NUMBER("V_DEPTNO")=20)- TO_NUMBER("V_DEPTNO") 를 사용하여 함수형 인덱스 생성
create index emp_x02 on emp(TO_NUMBER("V_DEPTNO"));
select * from emp where v_deptno =20;
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 5 |00:00:00.01 | 4 |
|* 2 | INDEX RANGE SCAN | EMP_X02 | 1 | 1 | 5 |00:00:00.01 | 2 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMP"."SYS_NC00011$"=20)1.8.3 null 허용케이스[편집]
create index emp_fbi01 on emp(mgr,'');
select *
from emp
where mgr is null;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 0 |00:00:00.01 | 1 |
|* 2 | INDEX RANGE SCAN | EMP_FBI01 | 1 | 1 | 0 |00:00:00.01 | 1 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("MGR" IS NULL)