인덱스 구조
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 인덱스 구조[편집]
1.1 B+Tree 인덱스 장점[편집]
- 인덱스를 이용해 데이터에 엑세스할 때 모든 인덱스 엔트리에 대해 균형(Balance)을 맞춤
- 인덱스를 이용한 범위(Range) 스캔 시 Double Linked List를 사용하기 때문에 다른 인덱스보다 더 유리하며 ACESENDING과 DESCENDING도 가능함
- OLTP 환경에서 적은 데이터에 엑세스하는 데 유리함
1.2 B+Tree 인덱스 단점[편집]
- 분포도(Cardinality)가 낮은 컬럼의 경우 B*TREE 인덱스가 불리함
- OR 연산자에 대해 테이블 전체를 스캔(Full Scan)하는 것은 위험함
- 인덱스 연산 불가
- 인덱스 확장 시 부하 발생
1.3 인덱스 오퍼레이션[편집]
1.3.1 추가 Insert Operation[편집]
- 테이블에 데이터가 추가되면 해당 테이블에 존재하는 인덱스에도 추가된 데이터의 인덱스 엔트리가 추가된다.
- 테이블에 추가되는 데이터의 인덱스 키(Key) 값의 저장 위치를 찾기 위해 인덱스 리프 블록을 확인해 찾는다.
- 그리고 인덱스 블록의 여유 공간에 해당 인덱스 엔트리를 추가한다.
- 해당 인덱스 블록에 여유 공간이 없을 경우, 해당 블록은 2개의 인덱스 리프 블록으로 분기돼 인덱스 키들은 다시 정렬되고
- 분기된 2개의 인덱스 리프 블록을 통해 추가된다. 이 때 리프 블록을 연결하고 있는 브랜치 블록과 루트 블록의 정보가 갱신될 수 있다.
1.3.2 삭제 Delete Operation[편집]
- Insert Operation과 정반대의 작업을 수행한다.
- 데이터가 삭제되면 해당 인덱스 엔트리의 연결이 끊어진다.
- 그렇게 함으로써 루트 블록으로부터 해당 인덱스 엔트리를 인식하지 못하게 한다.
- 삭제된 인덱스 엔트리의 공간은 추가를 위해 공간 해제를 수행하게 되며, 리프 블록에 하나의 인덱스 엔트리라도 남게 되면 인덱스 리프 블록은 유지되게 된다.
- 많은 인덱스 엔트리가 삭제되면 삭제된 공간은 반납된다.
- 그러나 해당 리프 블록의 전체 데이터가 삭제되지 않는 한 해당 리프 블록은 반납되지 않는다.
- 해당 리프 블록에 새로운 인덱스 엔트리가 추가로 저장되지 않는다면 공간이 낭비되게 된다.
1.3.3 갱신 Update Operation[편집]
- 삭제와 추가 작업이 동시에 수행되는 작업이다.
- 테이블에 데이터가 순차적으로 증가해 추가되는 경우 인덱스의 우측으로 인덱스 엔트리가 집중돼 B*TREE의 가장 중요한 특징인 균형(Balance)이 무너지게 된다.
- 또한 죄측 리프 블록으로 인덱스 엔트리가 추가되지 않기 때문에 좌측 리프 블록은 "블록 사용률" 이 낮아지게 된다.
- 삭제가 많거나 또는 인덱스 키가 순차적으로 증가하며 추가되는 테이블은 주기적인 인덱스 재구성(Rebuild)을 통해 인덱스 균형(Balance)을 유지시켜줘야 한다.
1.4 인덱스 구조[편집]
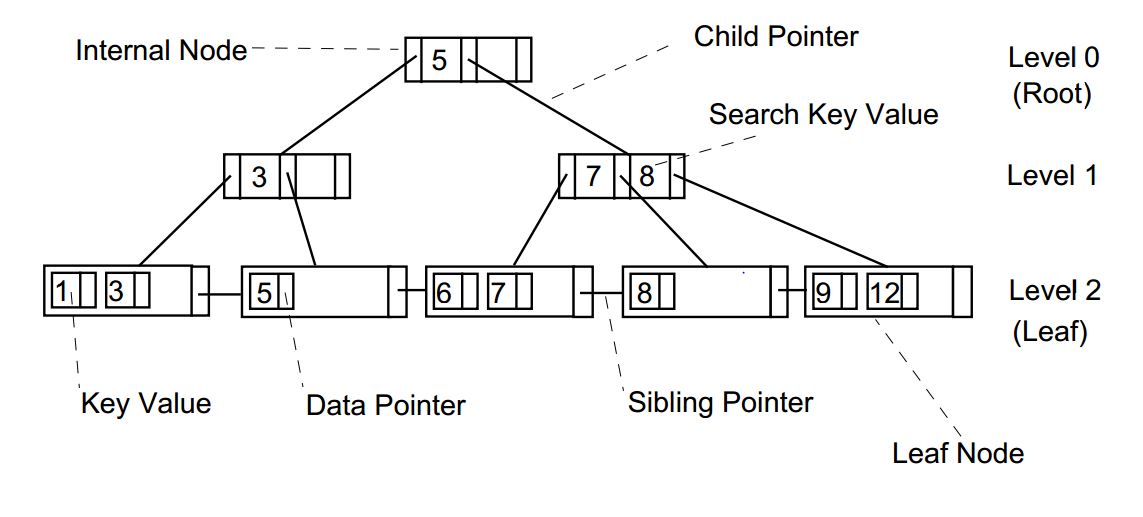
- B*tree는 leaf node 와 non-leaf 로 구성
- leaf node 부터 root node 까지의 길이는 모든 리프가 동일하다는 특징을 가지고 있다.
- 즉, 모든 리프 노드의 레벨은 동일하다.
- leaf node 간에는 링크드 리스트(linked list)로 연결되어 있어 여러 값을 스캔할 때 유리하다.
- leaf node 는 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다.
1.4.1 오라클 인덱스의 특징[편집]
- Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다.
- 즉, 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다.
1.5 인덱스 스캔 방식[편집]
1.5.1 INDEX RANGE SCAN[편집]
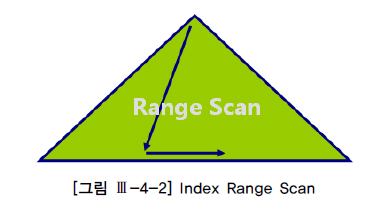
- 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위(Range)만 스캔하는 방식
- 실행계획 상에 Index Range Scan이 나타난다고 해서 항상 빠른 속도를 보장하는 것은 아님
- 인덱스를 스캔하는 범위(Range)를 얼마만큼 줄일 수 있느냐, 그리고 테이블로 액세스하는 횟수를 얼마만큼 줄일 수 있느냐가 튜닝의 관건
- Index Range Scan이 가능하게 하려면 인덱스를 구성하는 선두 칼럼이 조건절에 사용되어야 함.
- Index Range Scan 과정을 거쳐 생성된 결과집합은 인덱스 칼럼 순으로 정렬된 상태가 되기 때문에 이런 특징을 잘 이용하면 sort order by 연산을 생략하거나 min/max 값을 빠르게 추출할 수 있다.
1.5.2 INDEX FULL SCAN[편집]
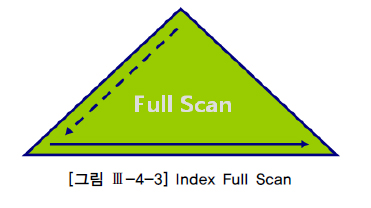
- Index Full Scan은 수직적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식으로서, 대개는 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.
- 인덱스 선두 칼럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려
- 그런데 대용량 테이블이어서 Table Full Scan의 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 검토한다.
- 데이터 저장공간은 ‘가로×세로’ 즉, ‘칼럼길이×레코드수’에 의해 결정되므로 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적게 마련이다.
- 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 테이블 전체를 스캔하는 것보다 낫다.
- 이럴 때 옵티마이저는 Index Full Scan 방식을 선택할 수 있다.
1.5.3 INDEX FAST FULL SCAN[편집]
- Index Fast Full Scan은 Index Full Scan보다 빠르다.
- Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다.
- Index Full Scan과 Fast Full Scan 비교
| INDEX FULL SCAN | INDEX FAST FULL SCAN |
|---|---|
| 1. 인덱스 구조를 따라 스캔 | 1. 세그먼트 전체를 스캔 |
| 2. 결과집합 순서 보장 | 2. 결과집합 순서 보장 안 됨 |
| 3. Single Block I/O | 3. Multiblock I/O |
| 4. 병렬스캔 불가(파티션 돼 있지 않다면) | 4. 병렬스캔 가능 |
| 5. 인덱스에 포함되지 않은 칼럼 조회 시에도 사용 가능 | 5. 인덱스에 포함된 칼럼으로만 조회할 때 사용 가능 |
1.5.5 INDEX SKIP SCAN[편집]
- 인덱스 선두 칼럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다.
- Oracle은 인덱스 선두 칼럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식을 9i 버전에서 선보였는데, 바로 Index Skip Scan이 그것이다.
- Index Skip Scan 내부 수행원리는 루트 또는 브랜치 블록에서 읽은 칼럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 “가능성이 있는” 하위 블록(브랜치 또는 리프 블록)만 골라서 액세스하는 방식이라고 할 수 있다.
- 이 스캔 방식은 조건절에 빠진 인덱스 선두 칼럼의 Distinct Value 개수가 적고 후행 칼럼의 Distinct Value 개수가 많을 때 유용하다.