NL 조인
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 NL 조인[편집]
2 Nested Loop Join 의 개념[편집]
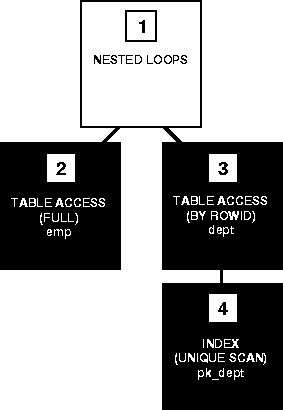
- 두개 이상의 테이블에서, 하나의 집합을 기준으로 순차적으로 상대방 테이블의 row 를 결합하여 원하는 결과를 추출하는 테이블 연결 방식
- 결합하기 위해 기준이 되는 테이블 : driving 테이블 또는 outer 테이블
- 결합되어지는 테이블 : driven 테이블 또는 inner 테이블
- NL 조인에서는 드라이빙 테이블의 각 row 에 대하여 loop 방식으로 조인이 되는데 드라이빙 테이블의 집합을 어느정도 줄일 수 있는가에 따라 NL 조인의 성능이 결정됨.
2.1 NL조인 시 인덱스 오브젝트 필요성[편집]
- 인덱스 오브젝트의 필요성
- - 드라이빙 테이블이 한 row 씩 반복해 가면서 inner 테이블과 조인이 이루어짐
- - inner 테이블의 연결 고리 칼럼에서 조인하고자 하는 값을 빠르게 검색할 수 있는 방법이 있어야함
- - inner 테이블의 크기가 적다면 테이블 전체를 메모리에 읽어서 반복적으로 검색하는 것이 빠름
- - 조인되는 값들의 cardinality 가 높을 수록, 한 번 스캔되어 조인된 자료가 다음 row 에서 조인에 사용될 확률이 낮아지기 때문에 스캔에 의한 조인 효율은 저하
- (-> 원하는 값이 존재하는 지 빠르게 확인하기 위한 목적과 그 값에 대한 데이터를 빠르게 읽어 내기 위해서 인덱스 오브젝트는 NL 조인에서 (특히 inner 테이블의 액세스 시) 반드시 필요)
2.2 인덱스 오브젝트 장점[편집]
- 인덱스 오브젝트의 장점
- - 단일 칼럼을 조인의 연결고리로 사용할 경우 전체 테이블 row size 가 100바이트이고 인덱스 칼럼의 크기가 10바이트라면, 전체 테이블을 검색하는 것과 인덱스를 검색하는 것은 절대적인 양으로도 10배 차이가 발생
- - 인덱스는 정렬되어 있기 때문에 검색 알고리즘을 인덱스는 정렬되어 있기 때문에 검색 알고리즘을 적용할 수도 있으며, 한번 읽어진 인덱스 블록들은 buffer cache 에 어느 정도는 남겨져 있기 때문에 반복적인 I/O 양은 최소화
예시) USE_NL( 어떤 테이블을 기술 할것인가? )
SELECT 고객.* ,주문.*
FROM 고객
JOIN 주문
ON 주문.고객번호 = 고객.고객번호
WHERE 고객.고객명='홍길동'
AND 주문.주문일자='201909';
3 인덱스 조건[편집]
- 드라이빙 테이블은 필터링 조건이 중요
- 세컨드 테이블은 조인조건의 인덱스가 중요
- 드라이빙 테이블 조회 후 1건씩 순차적으로 세컨트 테이블에 접근
- INDEX 구성
- EMP.IX_EMP_01 ( DEPTNO)
- DEPT.IX_DEPT_01 ( DEPTNO))
SELECT /*+ USE_NL(B) LEADING(A) */ ENAME,JOB,B.DNAME
FROM EMP A
JOIN DEPT B
ON A.DEPTNO = B.DEPTNO
-------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 17 (100)| | 14 |00:00:00.01 | 11 |
| 1 | NESTED LOOPS | | 1 | 14 | 672 | 17 (0)| 00:00:01 | 14 |00:00:00.01 | 11 |
| 2 | NESTED LOOPS | | 1 | 14 | 672 | 17 (0)| 00:00:01 | 14 |00:00:00.01 | 10 |
| 3 | TABLE ACCESS FULL | EMP | 1 | 14 | 364 | 3 (0)| 00:00:01 | 14 |00:00:00.01 | 7 |
|* 4 | INDEX RANGE SCAN | IX_DEPT_01 | 14 | 1 | | 0 (0)| | 14 |00:00:00.01 | 3 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 14 | 1 | 22 | 1 (0)| 00:00:01 | 14 |00:00:00.01 | 1 |
-------------------------------------------------------------------------------------------------------------------------------------4 LEADING 이나 ORDERED 힌트와 같이 사용 추천[편집]
- INDEX 구성
- EMP.IX_EMP_01 ( DEPTNO)
- DEPT.IX_DEPT_01 ( DEPTNO))
SELECT /*+ USE_NL(A,B) LEADING(A) */ ENAME,JOB,B.DNAME
FROM EMP A JOIN DEPT B ON A.DEPTNO = B.DEPTNO
-------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 17 (100)| | 14 |00:00:00.01 | 11 |
| 1 | NESTED LOOPS | | 1 | 14 | 672 | 17 (0)| 00:00:01 | 14 |00:00:00.01 | 11 |
| 2 | NESTED LOOPS | | 1 | 14 | 672 | 17 (0)| 00:00:01 | 14 |00:00:00.01 | 10 |
| 3 | TABLE ACCESS FULL | EMP | 1 | 14 | 364 | 3 (0)| 00:00:01 | 14 |00:00:00.01 | 7 |
|* 4 | INDEX RANGE SCAN | IX_DEPT_01 | 14 | 1 | | 0 (0)| | 14 |00:00:00.01 | 3 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 14 | 1 | 22 | 1 (0)| 00:00:01 | 14 |00:00:00.01 | 1 |
-------------------------------------------------------------------------------------------------------------------------------------5 USE_NL 괄호 안의 테이블은 NL조인 적용 대상 테이블[편집]
SELECT /*+ USE_NL(A,B) LEADING(B) */ ENAME,JOB,B.DNAME
FROM EMP A
JOIN DEPT B ON A.DEPTNO = B.DEPTNO
------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 6 (100)| | 14 |00:00:00.01 | 10 |
| 1 | NESTED LOOPS | | 1 | 14 | 672 | 6 (0)| 00:00:01 | 14 |00:00:00.01 | 10 |
| 2 | NESTED LOOPS | | 1 | 20 | 672 | 6 (0)| 00:00:01 | 14 |00:00:00.01 | 9 |
| 3 | TABLE ACCESS FULL | DEPT | 1 | 4 | 88 | 3 (0)| 00:00:01 | 4 |00:00:00.01 | 7 |
|* 4 | INDEX RANGE SCAN | IX_EMP_01 | 4 | 5 | | 0 (0)| | 14 |00:00:00.01 | 2 |
| 5 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 4 | 104 | 1 (0)| 00:00:01 | 14 |00:00:00.01 | 1 |
------------------------------------------------------------------------------------------------------------------------------------