버퍼 캐시
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 버퍼 와 캐시[편집]
1.1 버퍼 (Buffer)[편집]
- 두 장치간에 입출력 속도차이로 인한 처리 지연을 방지하지 위하여 도입된 개념
- 디스크는 CPU 와 비교하면 비교가 안될 정도로 느리다. 그래서 1개의 연산 데이터를 읽어들여 CPU 에 보낼 때, CPU 는 이에 따라 분당 100개의 데이터를 처리 할 수 있어도 디스크로 인하여 1개의 데이터를 처리 할 수 밖에없다.
- 이 때 CPU는 다른 작업들을 수행 하지 못하고 99개의 데이터 영역 처리 공간 및 시간이 지속 대기 및 지연이 되므로 이에 따라 연산속도를 제대로 활용하지 못한 채 연산 속도가 느려지게 된다.
- 그래서 그 사이에서 중간에 버퍼가 도입되게 되었다.
- 보통 이와 같이 CPU 가 연산을 하는 과정에서 언급 되는 버퍼는 메모리내의 버퍼 영역을 뜻한다.
- 메모리 영역이 중간에 있으면 디스크가 느리더라도 메모리에 1개씩 지속적으로 데이터를 전송하면서 메모리가 보관을 할 수 있다.
- CPU 는 메모리가 디스크로 부터 데이터를 지속적으로 받아 적재를 하기 때문에 그 동안 이 작업에 쓸 수 있는 연산공간을 다른 연산작업에 사용하는 한편, 메모리가 보관했다가 전송하는 디스크의 일부 데이터를 디스크가 데이터를 모두 전송할때 까지 대기 할 필요 없이 부분적으로 지속 처리를 하기 때문에 각 요소들이 대기시간으로 인한 성능 지연이 없이 CPU 연산을 100% 까지 사용 할 수 있다.
1.2 캐시 (Cache)[편집]
- 입출력 처리 속도 지연을 방지하는 것은 버퍼와 유사하나 추가적으로 연산 처리속도를 극대화 하기 위하여 도입된 개념
- 흔히 DB에서 작업이 필요한 데이터들을 디스크에서 선별하여 메모리에 보관한 후, 이 메모리를 디스크 대신 작업 데이터 보관 공간으로 사용
- DB가 디스크로부터 데이터를 지속적으로 조회를 하여 연산 처리 작업을 수행한다면, 위의 버퍼 개념과 같이 지속적인 성능 저하가 발생하므로 캐시는 매우 필수적인 요소
1.3 버퍼와캐시의 차이점[편집]
- 버퍼, 캐시는 두 장치간의 속도 간극을 줄이는데에 목적을 두는건 동일
- 버퍼는 속도가 느린 장치에 관점을 두어 속도 간극을 줄이고
- 캐시는 속도가 빠른 장치에 관점을 두어 속도간극을 줄이는 것
2 오라클 버퍼캐시[편집]
2.1 DB 버퍼 캐시[편집]
- 사용자가 입력한 데이터를 데이터 파일에 저장한 뒤 다시 읽는 과정에서 거쳐가는 캐시영역
- 최근 사용한 블록에 대한 정보를 저장하는 메모리의 일정 영역으로 물리적인 I/O를 최소화 한다.
2.2 블록단위 I/O[편집]
- 메모리 버퍼 캐시에서 버퍼 블록을 액세스 할때
- 데이터파일에 저장된 데이터 블록을 DB 버퍼 캐시로 적재할때
- 캐시에서 변경된 블록을 다시 데이터파일에 저장할 때
- 옵티마이져가 인덱스를 이용해 테이블을 액세스할 지 Full Table Scan을 할 지 결정하는 판단 기준으로 블록 갯수를 사용한다. 중요한 점은 레코드 수가 아니라는것.
2.2.1 single block I/O[편집]
- 한번의 I/O Call에 하나의 데이터 블록만 읽어 메모리에 적재하는 방법
- 인덱스를 경유해 테이블 액세스시 사용하는 액세스 방법
2.2.2 multi block I/O[편집]
- Call이 필요한 시점에 인접한 블록들을 같이 읽어 메모리에 적재하는 방법
- Extent 범위 단위에서 읽는다.
- 하나의 Extent 범위를 넘어가면 후에 다시 CALL을 해서 읽는다.
- 즉, Extent의 범위를 작게 설정하면 그만큼 DB CALL 횟수도 늘어난다.
- Full Table Scan시 사용하는 액세스 방법.
2.3 버퍼 캐시 구조[편집]
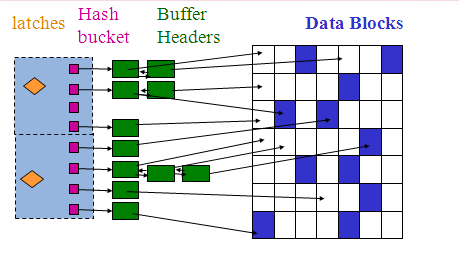
- 해시테이블 구조로 관리
- 찾고자 하는 데이터블록 주소인 DBA(Data Block Address))를 해시값으로 변환하여 해시 해시 키 값으로 사용
- 해당 해시 버킷에서 체인을 따라 스캔하여 있으면 바로 읽고 없으면 디스크에서 가져와 해시 체인에 연결한 후 읽는다.
- SGA 내에서 가장 많이 사용되는 자료구조.
- 버퍼 헤더만 해시 체인에 연결 되고 데이터 값은 포인터를 이용해 버퍼 블록을 찾아 얻는다.
- 여러개의 해시 버킷으로 구성.
- 해시 버킷과 해시 체인은 1:1 관계.
- 성능 고도화 목표 중 하나로 해시 체인 스캔 비용 최소화 하는것 .
- 하나의 해시 체인에 하나의 버퍼만 달리는 것을 목표로 한다.
2.4 하나의 해시 버킷의 구성[편집]

- 버킷(Bucket) ==> 체인(Chain) ==> 헤더(Header)의 구조
- 버퍼 헤더
- 버퍼에 대한 메타 정보.
- 버퍼 메모리 영역의 실제 버퍼에 대한 포인터 값.
- 버퍼 헤더
- 해시 체인은 Shared Pool 내에 존재.
- 해시 체인은 양방향의 링크된 리스트로 되어있다.
- 해싱(hasing) 알고리즘을 주소록으로 쉽게 이해하기
- 성씨가 같은 고객은 같은 페이지(=해시 버킷)내에 있지만 해시 버킷 내에서는 정렬상태를 유지 하지 않아 스캔방식으로 탐색하여 찾아야한다.
- 성능을 위해 각 버킷 내 엔트리 개수 일정 수준 유지가 필요하다.
2.5 버킷 찾아가기[편집]
- 블록의 주소(블록 클래스)를 해시함수에 적용한다.
- 같은 해시 값을 갖는 버퍼 헤더들이 체인 형태로 있다.
- Latch에 의해 보호되는 자료구조를 이용해 Latch를 획득한 프로세스만 진입을 허용한다.
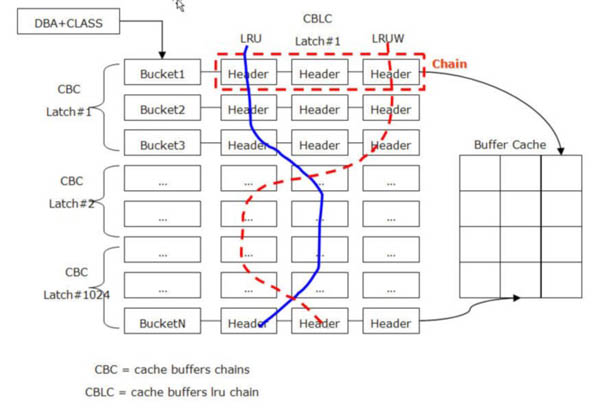
- 버퍼 캐시 구조를 통한 데이터 액세스의 전체적인 흐름
- 1) 해시 테이블 ( Hash table )
- 2) 해시 버킷 ( Hash bucket )
- 3) 버퍼 헤더 체인 ( buffer header chain )
- 4) 버퍼 헤더 ( buffer header )
- 5) 버퍼 캐시 블록 ( buffer body )
- 6) 테이블 블록 헤더 ( block header )
- 7) 테이블 블록 ( block body )
- 6) 테이블 블록 헤더 ( block header )
- 5) 버퍼 캐시 블록 ( buffer body )
- 4) 버퍼 헤더 ( buffer header )
- 3) 버퍼 헤더 체인 ( buffer header chain )
- 2) 해시 버킷 ( Hash bucket )
- 1) 해시 테이블 ( Hash table )
2.6 캐시 버퍼 체인[편집]
- 각 해시 체인은 Latch에 의해 보호된다.
2.7 래치 (Latch)[편집]
- 같은 리소스에 대한 액세스를 직렬화 하여 리소스를 보호하기 위해 구현된 일종의 Lock 메커니즘.
- 하나의 Latch 가 여러 해시 체인을 동시 보호.
- 버퍼 헤더에 Pin 설정 시 cache buffers chains Latch를 사용.
- Oracle 9i 부터 읽기전용일 경우 cache buffers chains 래치를 Share모드로 획득이 가능하다.
- 체인 구조 변경 혹은 버퍼 헤더에 Pin 설정 시 Exclusive 모드로 변경된다.
2.8 캐시 버퍼 체인 래치의 대기 이벤트[편집]
- 버퍼 캐시를 사용하기 위해 해시 체인을 탐색하거나 변경하려는 프로세스들이 래치를 획득하는 과정에서 경합이 발생한다.
- 캐시 버퍼 체인 래치 경합이 발생하는 대표적인 경우
- 비효율적인 SQL문장 사용 : 동시에 여러 프로세스가 넓은 범위의 인덱스나 넓은 범위의 테이블에 대해 스캔을 수행하는 경우에 발생한다.
- 핫블록(Hot Block) 현상 : SQL 문의 작동방식이 소수의 특정 블록을 계속해서 스캔하는 형태로 작성되었다면, 여러 세션이 동시에 이 SQL 문을 수행 할 때 경합이 발생한다.
- 캐시 버퍼 체인 래치 경합이 발생하는 대표적인 경우
2.9 캐시 버퍼 LRU 체인[편집]
- 두 종류의 LRU(Least Recently Used) 리스트를 사용.
- 모든 버퍼 블록 헤더를 LRU 체인에 연결하는데 이 때 둘 중 하나의 LRU 리스트에 속한다.
2.9.1 LRUW(LRU Write) List (= Dirty 리스트 )[편집]
- 캐시 내에서 변경됐지만, 아직 디스크에 기록되지 않은 Dirty버퍼 블록들을 관리.
- 변경 시 리스트에서 잠시 나온다.
- LRUW(LRU Write)리스트 라고도 한다.
2.9.2 LRU List[편집]
- 아직 Dirty 리스트로 옮겨지지 않은 나머지 버퍼블록들을 관리.
- 변경 시 Dirty 리스트(LRUW 리스트)로 이동.
모든 버퍼 블록은 셋중 하나의 상태이다.
2.9.3 Free 버퍼 (Free Buffer)[편집]
- 빈 상태 혹은 데이터 파일과 동기화 된 상태.
- 언제든 덮어 쓸 수 있으며 변경 시 Dirty 버퍼가 된다.
2.9.4 Dirty 버퍼 (Dirty Buffer)[편집]
- 변경 되어 데이터 파일과 동기화가 필요한 상태.
- 동기화 되면 Free 버퍼가 된다.
2.9.5 Pinned 버퍼[편집]
- 읽기/쓰기 작업 중인 버퍼 블록.
2.10 버퍼캐시 성능 개선[편집]
2.10.1 Buffer Cache에 상주되어 있는 오브젝트 확인[편집]
- 모든 세그먼트가 가지는 블럭의 수를 조회하는 쿼리
SELECT o.object_name, COUNT(*) number_of_blocks
FROM DBA_OBJECTS o, V$BH bh
WHERE o.data_object_id = bh.OBJD
AND o.owner != 'SYS'
GROUP BY o.object_Name
ORDER BY COUNT(*);2.10.2 BUFFER CACHE HIT RATIO 계산[편집]
- Buffer Cache Hit Ratio은 디스크 액세스없이 버퍼 캐시에서 요청 된 블록을 찾은 빈도를 계산
- 이 비율은 V$SYSSTAT 성능뷰 에서 선택한 데이터를 사용하여 계산됨
- 버퍼 캐시 적중률을 사용하여 V$DB_CACHE_ADVICE view에서 예측 한대로 물리적 I/O를 확인할 수 있음.
- V$SYSSTAT 뷰 통계값 설명
| Statistic | 설명 |
|---|---|
| consistent gets from cache | 버퍼 캐시에서 블록에 대해 일관된 읽기가 요청 된 횟수. |
| db block gets from cache | 버퍼 캐시에서 CURRENT 블록이 요청 된 횟수. |
| physical reads cache | 디스크에서 버퍼 캐시로 읽은 총 데이터 블록 수. |
- V$SYSSTAT 조회
SELECT name, value
FROM V$SYSSTAT
WHERE name IN ('db block gets from cache', 'consistent gets from cache',
'physical reads cache');- V$SYSSTAT 이용 Buffer Cache Hit Ratio를 계산
1 – ((‘physical reads cache’) / (‘consistent gets from cache’ + ‘db block gets from cache’))
위 계산식을 이용한 버퍼 캐시 히트율 쿼리.
-- 'Database Buffer Cache Hit Ratio'
select ((1-((phy.value)/(cur.value+con.value)))*100) AS bcache
from v$sysstat cur, v$sysstat con, v$sysstat phy
where cur.name = 'db block gets'
and con.name = 'consistent gets'
and phy.name='physical reads';- BUFFER CACHE HIT RATIO 해석
- 버퍼캐시 크기를 늘리거나 줄일지 결정하기 전에 먼저 버퍼 캐시 적중률을 검사 해야합니다.
- 캐시 적중률이 낮다고 해서 반드시 버퍼캐시 크기를 늘리면 성능에 도움이 된다는 의미는 아닙니다.
- 반대로 캐시 적중률이 높다고 해서 버퍼캐시의 크기가 현재의 워크로드에 적합한 크기를 가진다고 할 수도 없습니다.
- 버퍼 캐시 적중률을 해석하려면 다음 요인을 고려
- Single pass로 처리를 수행하거나 SQL문을 최적화하여 자주 액세스하는 데이터의 반복 스캔을 피해야 합니다.
- 동일한 큰 테이블이나 인덱스를 반복적으로 스캔하면 캐시 적중률이 인위적으로 높아질 수 있습니다.
- 자주 실행되고 많은 Buffer Gets를 발생하는 SQL문을 검사하여 실행 계획이 최적인지 확인 .
- 클라이언트 프로그램 또는 중간 계층에서 자주 액세스하는 데이터를 캐싱하여 동일한 데이터를 다시 쿼리하지 않게 합니다.
- OLTP 응용 프로그램을 실행하는 큰 데이터베이스에서는 많은 행에 한번만 액세스하거나 혹은 액세스 하지 않도록 합니다.
- 사용 후에 블록을 메모리에 보관할 목적이 없는 경우가 많기 때문.
- 버퍼캐시 크기를 지속적으로 늘려서는 안됩니다.
- 데이터베이스가 전체 테이블 스캔을 수행하거나 버퍼 캐시를 사용하지 않는 조작을 수행하는 경우 버퍼 캐시 크기의 지속적인 증가는 성능에 영향을 미치지 않습니다.
- 큰 테이블의 Full scan이 발생할 때 적중률이 낮은 것을 고려해야합니다.
- Short table scan은 특정 크기 임계 값 아래의 small table에서 수행되는 스캔입니다.
- Small table에 대한 정의는 최대 Buffer Cache 사이즈의 2% 입니다.