병렬 쿼리 튜닝
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
- 1 병렬 쿼리 튜닝
- 1.1 병렬처리 핵심은?
- 1.2 슬기로운 병렬처리 사용법
- 1.3 병렬 처리 진행 사항 모니터링
- 1.4 PARALLEL 힌트를 사용해도 병렬 처리가 안되는 경우
- 1.5 병렬 힌트 활용
- 1.6 병렬 쿼리 튜닝 포인트
- 1.7 입력/수정 성능저하시 검토 사항
- 1.8 데이터 전환시 사용하는 병렬처리
1 병렬 쿼리 튜닝[편집]
1.1 병렬처리 핵심은?[편집]
1.1.1 그래뉼[편집]
android The basic unit of work in parallelism is a called a granule.
Oracle Database divides the operation executed in parallel (for example, a table scan, table update, or index creation) into granules.
- 병렬로 처리할때 일의 최소 단위
- 병렬 서버는 한번에 하나의 그래뉼씩 처리 함
- 그래뉼 갯수와 크기는 병렬도와 관련되고 분산처리에 영향을 미침
- 블록 그래뉼 과 파티션 그래뉼로 나뉨
- 병렬 쿼리 granule
1.1.1.1 블록 그래뉼[편집]
- PX BLOCK ITERATOR 라고 표시
- QC는 테이블로부터 읽어야할 범위의 블록 GRANULE로서 각 병렬 서버에게 할당
- 파티션 여부,파티션 갯수 와 무관하게 병렬도 지정이 가능
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
==========> 블록 이터레이터로 표시됨
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------1.1.1.2 파티션 그래뉼[편집]
- PX PARTITION RANGE ALL
- 전체 파티션을 읽을때 표시
- PX PARTITION RANGE ITERATOR 라고 표시
- 일부 파티션만 읽을 때 표시
- 사용되는 시기
- Partition-Wise 조인 시
- 파티션 인덱스를 병렬로 스캔할 시
- 파티션 인덱스를 병렬로 갱신할 때
- 파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
- 병렬도는 파티션 갯수 이하로만 지정 할수 있음(튜닝 요소)
- 1개 파티션을 2개의 프로세스가 함께 처리 할수 없음
- 예시) WHERE 조건에 파티션 컬럼이 1개만 타도록 제한된 경우 아래 예시 참조
- 병렬 서버가 한 파티션 처리를 끝마치면 다른 파티션을 할당 받아서 진행 함(병렬도가 파티션 갯수 보다 적을때)
---------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000| 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
==========> 파티션 RANGE ... 로 표시됨
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES| 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST|26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
---------------------------------------------------------------------------------------------------1.1.2 파티션-와이즈 조인 Partition-wise Join[편집]
- 기본적인 원리는 커다란 하나의 조인을 분할하여 여러개의 작은 조각으로 나누는것
- 머지조인, 해시조인시 적용하는 최적화 기법
- 파티션 와이즈 조인은 파티션 테이블이 필수 임
- 조인처리에 사용되는 cpu,memory,네트워크 리소스를 줄이는 방법임
- '-wise' 의미 [1]
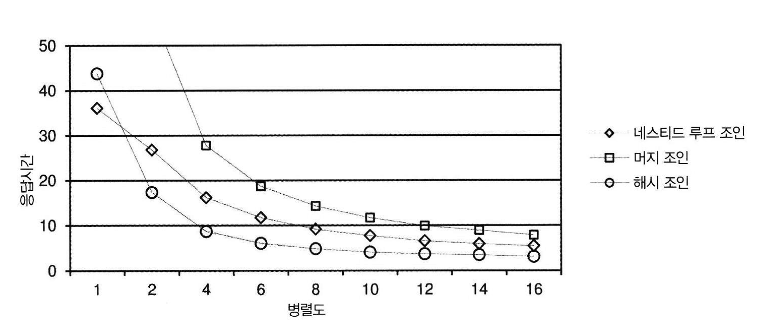
- 조인 과 병렬도 성능 비교
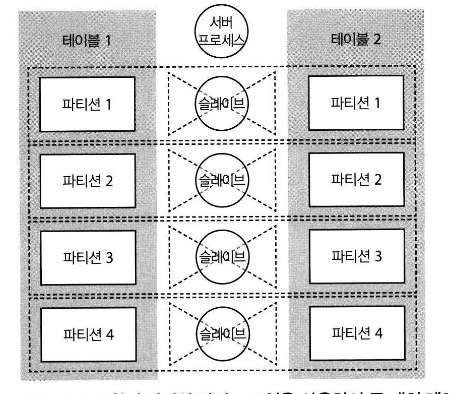
1.1.2.1 풀 파티션-와이즈 조인[편집]
- Full Partition-Wise Join (완전 동등하게 조인)
- 동등하게 파티션된 2개 테이블을 조인 함
- 대규모 조인이 예상되는 테이블은 동등한 파티션으로 설계할것을 모델링 단계에서 고려할것
- (주의사항) 리스트 파티션은 동일 갯수,동일 순서가 맞도록 파티션 되어야 함
- 서브파티션과도 조인 가능
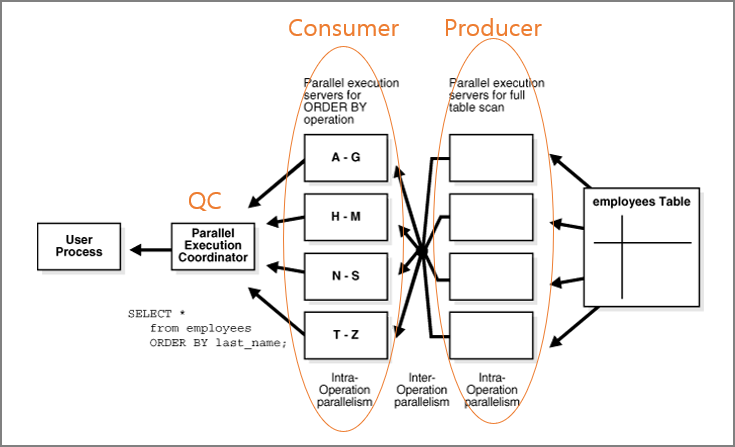
1.1.2.2 부분 파티션-와이즈 조인[편집]
- Patial Partition-Wise Join (부분)
- 병렬로만 수행이 가능함
- 한쪽 테이블만 조인키 기준으로 파티션 된 경우임
- 부분 파티션 조인시 일반 조인보다는 빠르지만 큰 성능 향상을 기대하기는 어렵다.(오히려 성능이 나빠질수도 있다)

1.1.4 DOP 많을수록 좋을까?[편집]
1.1.4.1 DOP 32 => DOP 16 으로 줄여서 성능개선[편집]
- 튜닝 전
MERGE /*+ENABLE_PARALLEL_DML PARALLEL(32) FULL(T) USE_HASH(T)*/
INTO TB_TEST1 T
USING (
SELECT PLAN_ID
, GRFNLID
, IDMB_ID
, SBWDC_ID
.... 생략 ....
- 튜닝 후
- - 분배 방식 및 ACCESS 방식 변경을 위한 힌트 추가.
- 약 1천 9백만건 이상 MERGE 되는 대량 DML 문으로 원본도 병렬 처리가 잘되고 있어 크게 개선 될 포인트는 없음.
- parallel degree는 16으로 내렸으며 약 583초(8분23초) 수행.(변경전 700초)
- SQL 변경
MERGE /*+ ENABLE_PARALLEL_DML PARALLEL(T 16) LEADING(S) FULL(T) USE_HASH(T) PQ_DISTRIBUTE(T HASH HASH) */
INTO TB_TEST1 T
USING (
SELECT PLAN_ID
, GRFM_ID
, IDM8_ID
.... 생략 ....1.1.6 병렬 PLAN 해석하는 방법[편집]
- XPLAN 조회 ( ‘+PARTITION +PARALLEL +OUTLINE' )
-- 병렬 쿼리 확인
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST ADAPTIVE PARTITION PARALLEL OUTLINE'));--------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1638 | 7 (29)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
----------[3] 서버집합(Q1,02)은 전송받은 레코드를 정렬하고 나서 QC에게 전송한다.
| 2 | PX SEND QC (ORDER) | :TQ10002 | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | P->S | QC (ORDER) |
| 3 | SORT ORDER BY | | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | PCWP | |
------------[소비자]
| 4 | PX RECEIVE | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,02 | PCWP | |
-------------[2] 1번째 서버집합(Q1,01)은 EMP테이블을 병렬로 읽으면서 QC에서 받은 DEPT테이블과 조인하고,조인에 성공한 레코드는 2번째 서버집합(Q1,02)에게 전송한다.
-------------[생산자]
| 5 | PX SEND RANGE | :TQ10001 | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | P->P | RANGE |
|* 6 | HASH JOIN | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | PCWP | |
| 7 | BUFFER SORT | | | | | | Q1,01 | PCWC | |
----------------[소비자]
| 8 | PX RECEIVE | | 4 | 120 | 3 (0)| 00:00:01 | Q1,01 | PCWP | |
-----------------[생산자]
| 9 | PX SEND BROADCAST | :TQ10000 | 4 | 120 | 3 (0)| 00:00:01 | | S->P | BROADCAST |
------------------[1] QC가 DEPT 읽어서 1번째 서버집합(Q1,01)에게 전송 한다
| 10 | TABLE ACCESS FULL| DEPT | 4 | 120 | 3 (0)| 00:00:01 | | | |
| 11 | PX BLOCK ITERATOR | | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWC | |
| 12 | TABLE ACCESS FULL | EMP | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
--------------------------------------------------------------------------------------------------------------------
1.1.6.1 SQL 플랜상 튜닝 검토 사항[편집]
android # broadcast 는 소량테이블에 적합(임시로 생성한 테이블에 통계정보가 있는지 확인필요)
- hash 는 대량 테이블에 적합
- S->P 는 튜닝 대상임. P->P로 바꿀수 있는 방법을 검토.sql수정도 좋다.
- round-robin 은 튜닝 대상임
- merge 나 insert ,delete문에만 주로 Parallel 힌트 사용. 하위 select 문에서는 가급적 지양 , 1:1 관계를 지향한다
- part key 플랜도 튜닝 대상. pq_disiribute(A hash hash) 힌트로 변경 검토
- 오라클은 내부적 으로 어떤 힌트를 사용하고 있는지 볼까 ?
- OUTLINE

1.2 슬기로운 병렬처리 사용법[편집]
- 병렬도를 같게 지정하는 것이 바람직 함.
- 테이블별 개별 힌트- PARALLEL(A 8) 보다 글로벌 힌트- PARALLEL(8)로 적용
1.2.1 병렬 힌트를 어디에 어떻게 써야 하나?[편집]
1.2.1.1 SELECT 절 병렬 힌트[편집]
- 조인 순서 지정 - leading() , ordered 힌트사용
- 조인 방식 지정 - use_nl(),use_hash(),use_merge()
- * hash 조인일때 - SWAP_JOIN INPUTS() , NO_SWAP_JOIN INPUTS() - Build Input 지정
- FULL() 힌트 사용 - 옵티마이저가 인덱스 스캔을 선택하면 parallel 힌트가 무시됨
- PO_DISTRIBUTE() 분산 방식 지정
SELECT
-- 튜닝 전
/* FULL(BA) FULL(BB) FULL(BC) FULL(BD)
PARALLEL(BA 16)
PARALLEL(BB 16)
PARALLEL(BC 16)
PARALLEL(BD 16) */
-- 튜닝 후
/*+ PARALLEL(16)
LEADING(BB) USE HASH(BA BB BC BD )
FULL(BA) PO_DISTRIBUTE(BA HASH HASH) NO_SWAP_JOIN INPUTS(BA)
FULL(BB) PO_DISTRIBUTE(BB HASH HASH) SWAP_ JOIN_INPUTS(BB)
FULL(BC) PQ_DISTRIBUTE(BC HASH HASH) NO_SWAP_JOIN_INPUTS(BC)
FULL(BD) PQ_DISTRIBUTE(BD HASH HASH) NO_SWAP_JOIN_INPUTS (BD)
*/
....
FROM TB_MB. BA -- 20G
, TB_FM BB -- 5G
, TB_FMBR BC -- 8G
, TB_IDM BD -- 13G
WHERE 1 = 1
AND BA.Q_ID IN (
SELECT DISTINCT O_ID
......1.2.1.2 INSERT 절 병렬 힌트 위치[편집]
INSERT /*+ PARALLEL (4) ENABLE_PARALLEL_DML */ -- PQ_DISTRIBUTE(T NONE)
INTO TB_WM_DTLS T1.2.1.3 INSERT 절 병렬 힌트 적용 안되는 경우[편집]
-- insert 앞에 힌트
/*+ PARALLEL (4) ENABLE_PARALLEL_DML*/ -- PQ_DISTRIBUTE(T NONE)
INSERT INTO
TB_XM_DTLS T
....
-- into 뒤에 힌트
INSERT INTO /*+ PARALLEL (4) ENABLE_PARALLEL_DML */ -- PQ_DISTRIBUTE(T NONE)
TB_XM_DTLS T
....1.2.1.4 UPDATE/ DELETE / MERGE 힌트 위치[편집]
UPDATE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ 테이블명 ~
DELETE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ FROM 테이블 ~
MERGE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ INTO 테이블명 ~
1.2.2 DDL 병렬 처리[편집]
SQL> alter session enable parallel ddl;1.2.2.1 CREATE 예시[편집]
-- 테이블 생성
CREATE TABLE name ( column1 [data-type], ... )
Parallel 8;
-- 인덱스 생성 DOP 32
CREATE INDEX CYKIM.IX_TBL_X01
ON (MY_TABLE)
TABLESPACE TS_CY PARALLEL 32 NOLOGGING;
ALTER INDEX CYKIM.IX_TBL_X01 NOPARALLEL LOGGING;1.2.2.2 ALTER 예시[편집]
ALTER TABLE name Parallel 8 ;1.2.3 DML 병렬 처리[편집]
- DML 작업에서는 Paralle 힌트를 주어도 QC 가 작업 담당
- 병렬 DML 가능하도록 처리
- 12c 이전 에는 세션에 적용
SQL> alter session enable parallel dml;- 12c 부터는 힌트로 적용
/*+ ENABLE_PARALLEL_DML */


1.2.3.2 DML 병렬 처리시 주의사항[편집]
android *DML 병렬 처리시 주의사항
- 테이블 전체에 Exclusive 모드로 Lock 획득하므로 주의
- 커밋/롤백을 해야 SELECT 가능 함.
- DML 처리시 플랜에서 항상 QC 아래에 INSERT/UPDATE/DELETE 가 존재 해야 한다. (QC가 아닌 병렬서버에서 처리 토록 해야 한다.)
1.2.4 동일 테이블에 병렬로 입력 하는 방법[편집]
- Oracle에서 파티션 테이블을 이용하여 데이터를 병렬로 입력하는 방법
- 파티션 테이블은 데이터를 물리적 또는 논리적 파티션으로 분할한 테이블입니다.
- 아래 예시에서 INSERT INTO ... SELECT 문을 사용하여 병렬로 데이터를 입력하는 방법을 보여줍니다.
-- 파티션 테이블 생성
CREATE TABLE sales (
sale_id NUMBER,
sale_date DATE,
product_id NUMBER,
quantity NUMBER
)
PARTITION BY RANGE (sale_date) (
PARTITION sales_202301 VALUES LESS THAN (TO_DATE('2023-02-01', 'YYYY-MM-DD')),
PARTITION sales_202302 VALUES LESS THAN (TO_DATE('2023-03-01', 'YYYY-MM-DD'))
);
-- 병렬로 데이터 입력
-- 세션 1에서 데이터 입력
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(sales, 4) */ INTO sales
SELECT sale_id, TO_DATE('2023-01-15', 'YYYY-MM-DD'), product_id, quantity FROM sales_data_january;
commit; -- 커밋을 해야 다른세션에서도 커밋이 가능하다
-- 세션 2에서 데이터 입력
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(sales, 4) */ INTO sales
SELECT sale_id, TO_DATE('2023-02-15', 'YYYY-MM-DD'), product_id, quantity FROM sales_data_february;
commit;- ORA-12838 : 병렬로 수정한 후 객체를 읽거나 수정할 수 없습니다. 오류 발생시 커밋 여부를 확인할것. 같은 세션에서도 커밋하지 않으면 조회도 불가능하다.
1.3 병렬 처리 진행 사항 모니터링[편집]
1.3.1 진행 사항 모니터링 관련 뷰[편집]
- DISK I/O 확인
- - V$SESS_IO
- LONG OPS
- - V$SESSION_LONGOPS
- CURRENT STATMENT
- - V$PX_SESSION
- Session Wait Event
- - V$SESSSION_EVENT
1.3.2 REAL MONITOR[편집]
- 사용법
SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR('5yfzxpu5593jw') FROM DUAL;



- html 포멧으로 출력
select dbms_sqltune.report_sql_monitor(sql_id=>'5yfzxpu5593jw',type=>'html', report_level=>'ALL') from dual;
1.3.3 병렬_쿼리_모니터링[편집]
1.3.3.1 병렬 세션 조회[편집]
select c.sid as qcsid
, s.sid as slasid
, p.server_name
from v$session c
, v$px_session s
, v$px_process p
where c.sid = s.qcsid
and c.sid = &SID_OF_SESSION_1
and p.sid = s.sid;1.3.3.2 병렬 처리 데이터 전송 통계 확인[편집]
select tq_id,server_type,process,num_rows,bytes,waits
from V$PQ_TQSTAT
order by dfo_number
, tq_id
, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3)
, process;1.3.4 토드에서 모니터링 하는 방법[편집]
- Database - Session Browser
- IO 탭
- Waits 탭
- Current Statsment 탭
- Long Ops 탭
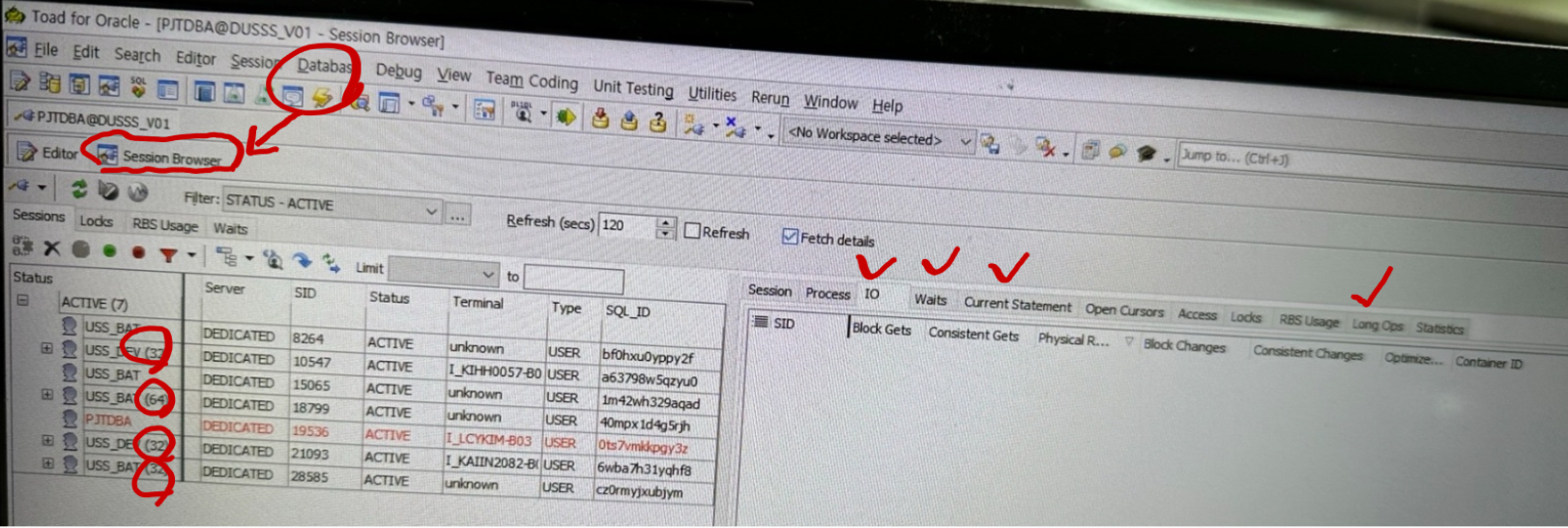

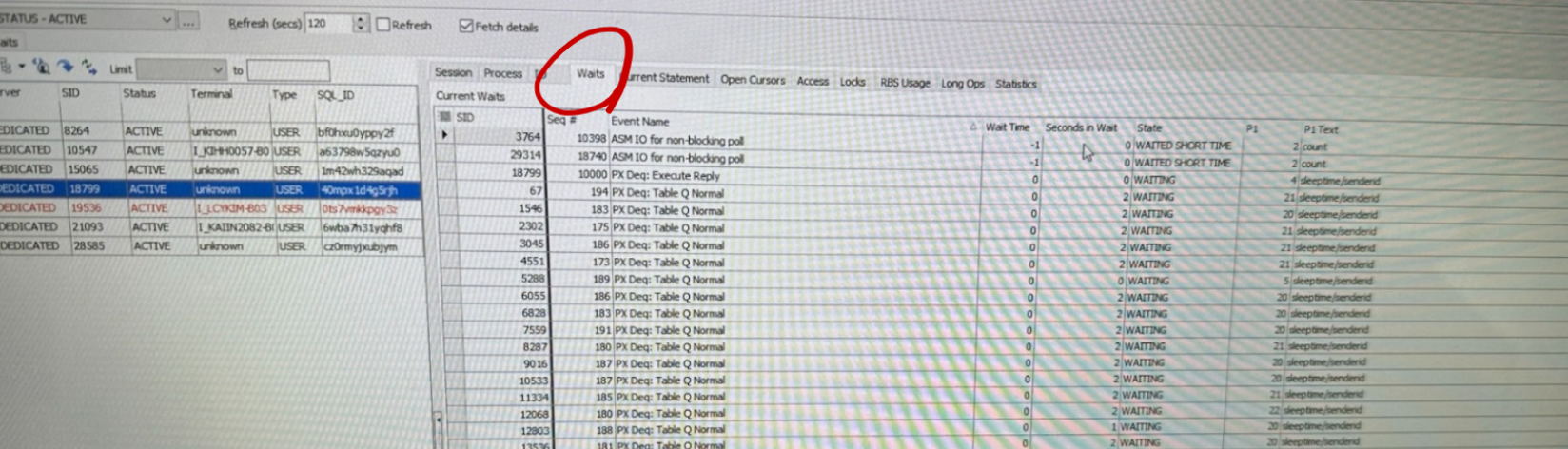

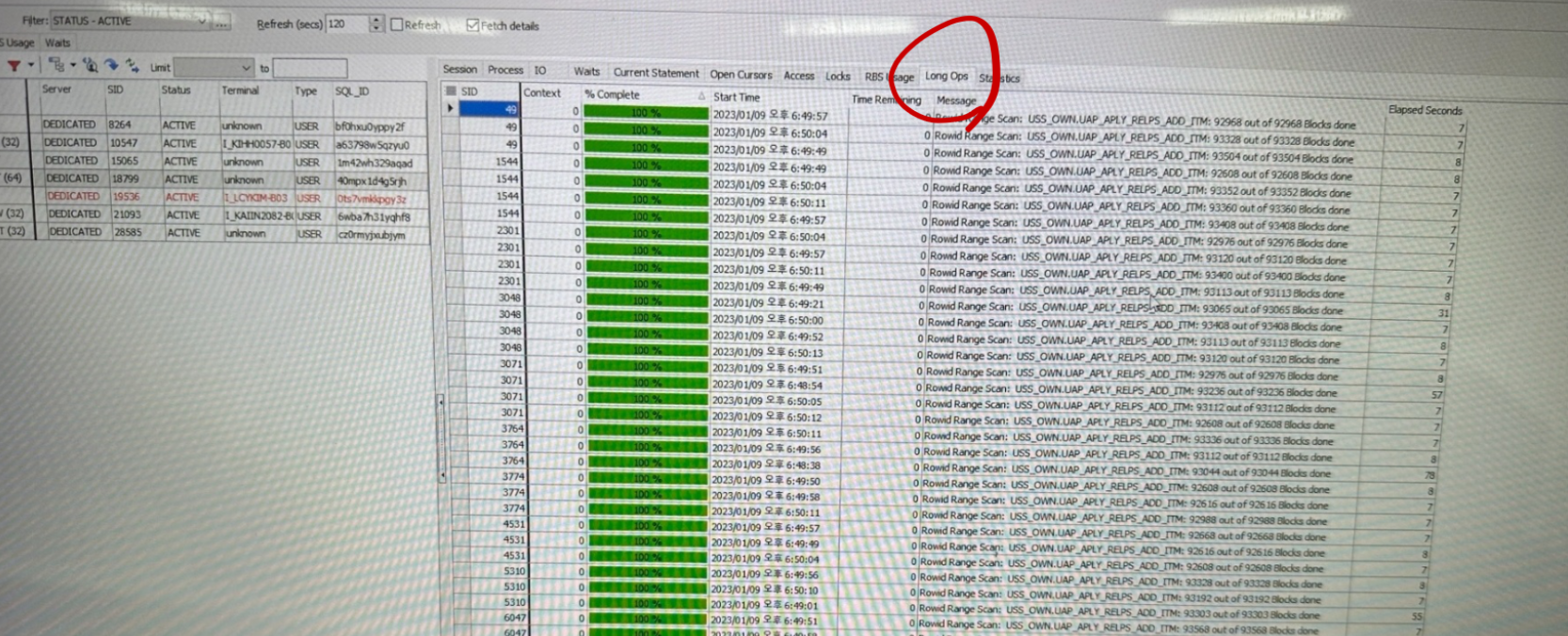
1.3.5 병렬 처리 WAIT EVENT 확인 방법[편집]
1.3.5.1 병렬 처리 대기 이벤트 발생 순서[편집]
- PX Deq: Execute Replay,작업 끝날때까지 대기중
- SQL*Net message from client, 클라이언트로 부터 추가 Fetch Call이 오기를 기다리고 있음을 의미함.
1.3.5.2 병렬 처리 대기이벤트 종류[편집]
- PX Deq: Parse Reply
- - PEC 가 PES 에게 파싱 요청을 한 후 응답이 올 때까지 대기하는 이벤트
- - 10G 에서 도입된 PSC(Parallel Single Cursor) 모델에서는 PEC가 생성한 커서를 공유하기 때문에 이러한 과정은 생략된다.
- - 단. RAC 에서는 여전히 PEC 와 다른 노드에 존재하는 PES는 PEC가 생성한 SQL문을 파싱하는 역할을 수행
- PX Deq: Execute Reply
- - QC가 각 병렬 서버에게 작업을 배분하고 작업이 완료 되기를 기다리는 대기이벤트.
- PX Deq Credit : need buffer
- - 데이터를 전송하기 전에 수신 병렬서버 또는 QC로 부터 credit 비트를 얻으려고 대기하는 상태
- - PX Deq Credit:send blkd(로컬 시스템) 과 PX Deq Credit:need buffer(RAC 에서)은 거의 같은 대기 이벤트임.
- - 오라클은 두 프로세스 중 한 순간에 오직 하나의 프로세스만이 테이블 큐에 데이터를 집어넣을 수 있도록 보장한다.
- - 테이블 큐에 데이터를 집어넣을 수 있는 자격을 확보할 때까지 기다리는 이벤트다.
- PX Deq: Execution Msg
- - 병렬서버가 자신의 작업을 마치고 다른 병렬서버가 일을 끝나기를 기다리는 이벤트.
- - QC 또는 소비자 병렬 서버에게 데이터 전손을 완료했을때 나타남
- PX Deq: Table Q Normal
- - 테이블 큐에 데이터가 들어오기를 기다리는 이벤트
- direct path read
- - 버퍼 캐시를 경유하지 않고 데이터 파일로부터 직접 데이터를 읽는 과정에서 발생하는 이벤트
- - 테이블로부터 데이터를 페치하는 작업은 대부분 데이터 파일에서 직접 데이터를 읽는 방식을 사용.
- enq: TC Contention
- - QC가 Direct Path I/O를 수행하려면, 해당 테이블에 대한 체크 포인트(Checkpoint)작업이 선행 되어야 한다.
- - 버퍼 캐시의 더티 버퍼가 모두 데이타 파일에 기록되어야 버퍼 캐시를 경유하지 않고 데이터 파일에서 직접 데이터를 읽을 수 있기 때문이다.
- - 작업을 지시하기 전에 체크포인트 요청을 하고 작업이 끝날 때 까지 기다려야 하며 그 동안 enq: TC Contention 이벤트 대기
1.3.5.3 병렬 세션 대기,대기 이벤트,대기 클래스 조회[편집]
- V$PX_SESSION + V$SESSION
SELECT DECODE(A.QCSERIAL#, NULL, 'PAREMT', 'CHILD') ST_LVL,
A.SERVER_SET "SET",
A.SID,
A.SERIAL#,
STATUS,
EVENT,
WAIT_CLASS
FROM V$PX_SESSION A,
V$SESSION B
WHERE A.SID = B.SID
AND A.SERIAL# = B.SERIAL#
ORDER BY A.QCSID,
ST_LVL DESC,
A.SERVER_GROUP,
A.SERVER_SET
;1.3.5.4 WAIT EVENT - 상세 대기시간 확인[편집]
- V$SESSION + V$SESSSION_EVENT
SELECT S.INST_ID, S.SID, S.SQL_ID
, S.MACHINE, S.PROGRAM, S.EVENT
, S.BLOCKING_SESSION_STATUS
, SE.EVENT AS EVENT_DTL
, SE.WAIT_CLASS , SE.TIME_WAITED
, SE.MAX WAIT , SE.TOTAL_TIMEOUTS
FROM GV$SESSION S
, GV$SESSION_EVENT SE
WHERE S.SID = SE.SID
AND S.INST ID = 1
AND S SID=8281
-- AND SE.EVENT = 'gc current grant busy'
-- AND S.SQL ID = ''
AND SOL_ID IS NOT NULL
ORDER BY SE.TIME_WAITED DESC1.3.5.5 대기항목별 WAIT CLASS 확인[편집]
- V$SESSION_WAIT + V$SESSSION_WAIT_CLASS
SELECT A.SID, A.SEQ#, A.EVENT,P1TEXT
, A.STATE , A.WAIT_TIME_MICRO
, A.TIME_REMAINING_MICRO
, B.WAIT_CLASS#, B.WAIT_CLASS
, B.TOTAL_WAITS, B. TIME_WAITED
FROM GV$SESSION WAIT A
, GV$SESSION_WAIT_CLASS B
WHERE A.INST_ID = B.INST_ID
AND A.INST_ID =1
AND A.SID = B.SID
AND A.SID = :SID -- 1510
AND A.SERIAL# = B.SERIAL#1.4 PARALLEL 힌트를 사용해도 병렬 처리가 안되는 경우[편집]
1.4.1 병렬 처리 갯수 확인[편집]
1.4.1.1 병렬처리 제약 조건[편집]
SELECT * FROM V$PARAMETER
WHERE NAME IN ('parallel_degree_limit') ; -- CPU- CPU
- 최대 병렬 처리 갯수가 시스템의 CPU 수에 따라 제한(기본값)
- 제한을 계산하는 데 사용되는 공식은 PARALLEL_THREADS_PER_CPU * CPU_COUNT * 사용 가능한 인스턴스 수입니다(기본적으로 클러스터에서 열려 있는 모든 인스턴스이지만 PARALLEL_INSTANCE_GROUP 또는 서비스 사양을 사용하여 제한할 수 있음).
- AUTO
- CPU 값과 동일
- IO
- 옵티마이져가 사용할 수 있는 최대 병렬 처리 갯수은 시스템의 I/O 용량에 따라 제한
- 이 값은 전체 시스템 처리량을 프로세스당 최대 I/O 대역폭으로 나누어 계산
- IO 설정을 사용하려면 시스템에서 DBMS_RESOURCE_MANAGER.CALIBRATE_IO 프로시저를 실행해야 하고 이 절차에서는 전체 시스템 처리량과 프로세스당 최대 I/O 대역폭을 계산함
- 숫자
- 이 파라메터의 숫자값은 자동 병렬 처리 수준이 활성화된 경우 최적화 프로그램이 SQL 문에 대해 선택할 수 있는 최대 병렬 처리 수준을 지정 함
- 자동 병렬 처리 갯수는 PARALLEL_DEGREE_POLICY가 ADAPTIVE, AUTO 또는 LIMITED로 설정된 경우에만 활성화 됨
- DOP 최대 갯수 = parallel_threads_per_cpu * cpu_count
SELECT *
FROM V$PARAMETER
WHERE NAME in ('parallel_threads_per_cpu','cpu_count')1.4.2 병렬 환경 파리미터 상세 조회[편집]
SELECT *
FROM V$PARAMETER
WHERE NAME LIKE '%parallel%'
1.4.3 병렬처리가 안되는경우[편집]
- 병렬 요청/할당 확인
select sid,serial#
, server_group,server_set
, degree , req_degree
from v$PX_SESSION:1.4.3.1 서버에서 프로세스를 할당 받지 못할때[편집]
1.4.3.2 insert ~ select 의 병렬도가 다를때[편집]
1.4.3.3 파티션닝 테이블에 1개파티션만 타는경우[편집]
- 튜닝 전
- LINK_ID 가 파티션키임.
- 플랜


- 튜닝 후
- 튜닝 후 플랜



1.4.3.4 LOB 컬럼 포함시[편집]
- lob 컬럼 포함시 => 오라클 19c 부터기능
1.4.3.5 DB 링크[편집]
1.4.3.6 기타 요소[편집]
- 할당된 process 갯수가 작을때 (오라클 파라미터 확인,v$parameter)
- OS상 디스크 I/O가 너무 느릴때
1.5 병렬 힌트 활용[편집]
1.5.1 PQ_DISTRIBUTE[편집]

1.5.1.1 가능한 조합[편집]
- HASH - HASH : OUTER, INNER 크기가 비슷할 때
- BROADCAST - NONE : OUTER 테이블이 작을때
- NONE - BROADCAST : INNER 테이블이 작을때
- PARTITION - NONE : INNER 테이블 파티션 기준으로 OUTER 테이블을 파티션 하여 분배
- NONE - PARTITION : OUTER 테이블 파티션 기준으로 INNER 테이블을 파티션 하여 분배
- NONE - NONE : 두 테이블이 조인컬럼 기준으로 파티션 되어 있을때
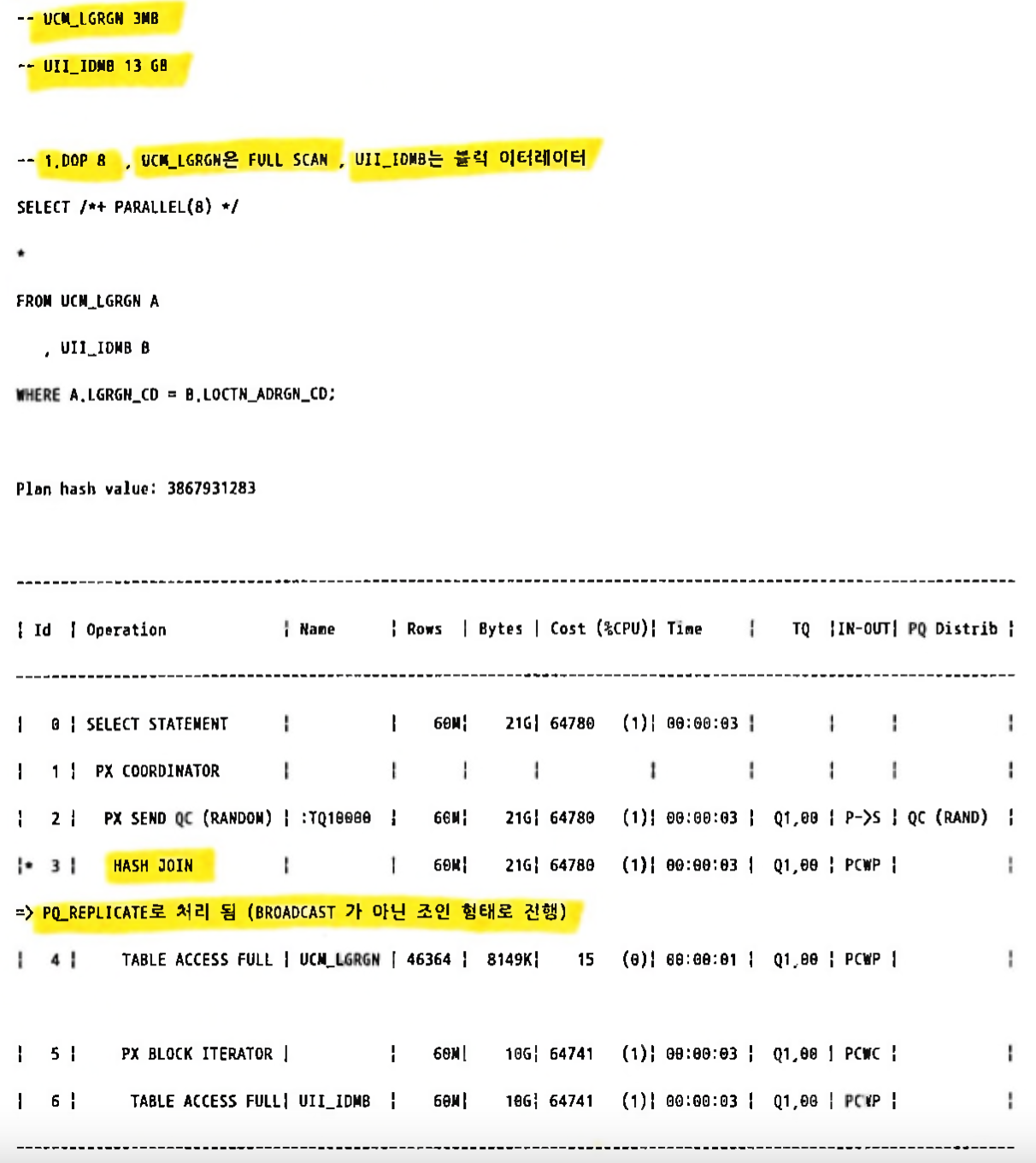
1.5.2 PQ_REPLICATE / NO_PQ_REPLICATE(대량테이블명)[편집]
- 각각 병렬서버에서 테이블 전체를 읽음
- BROADCAST 문제점을 보완 하는 힌트
- BROADCAST처럼 분산 하여 읽지 않음(병렬도가 많을수록 BROADCAST 방식은 분배시 부하 발생)
- 로컬 캐시(SGA) 에서 빠르게 읽는 방식
- 복제라기보다는 조인처럼 생각
- 매우 작은 테이블 처리시 유리
- 튜닝 예시 (소량테이블(3MB)이 BROADCAST 가 아닌 조인 형태로 병렬 처리됨)
- 소량테이블(3MB)이 BROADCAST 처리 하도록 힌트 추가 (NO_PQ_REPLICATE)
- 힌트 사용시 NO_PQ_REPLICATE(소량테이블명) 이 아닌 NO_PQ_REPLICATE(대량테이블명) 임을 주의
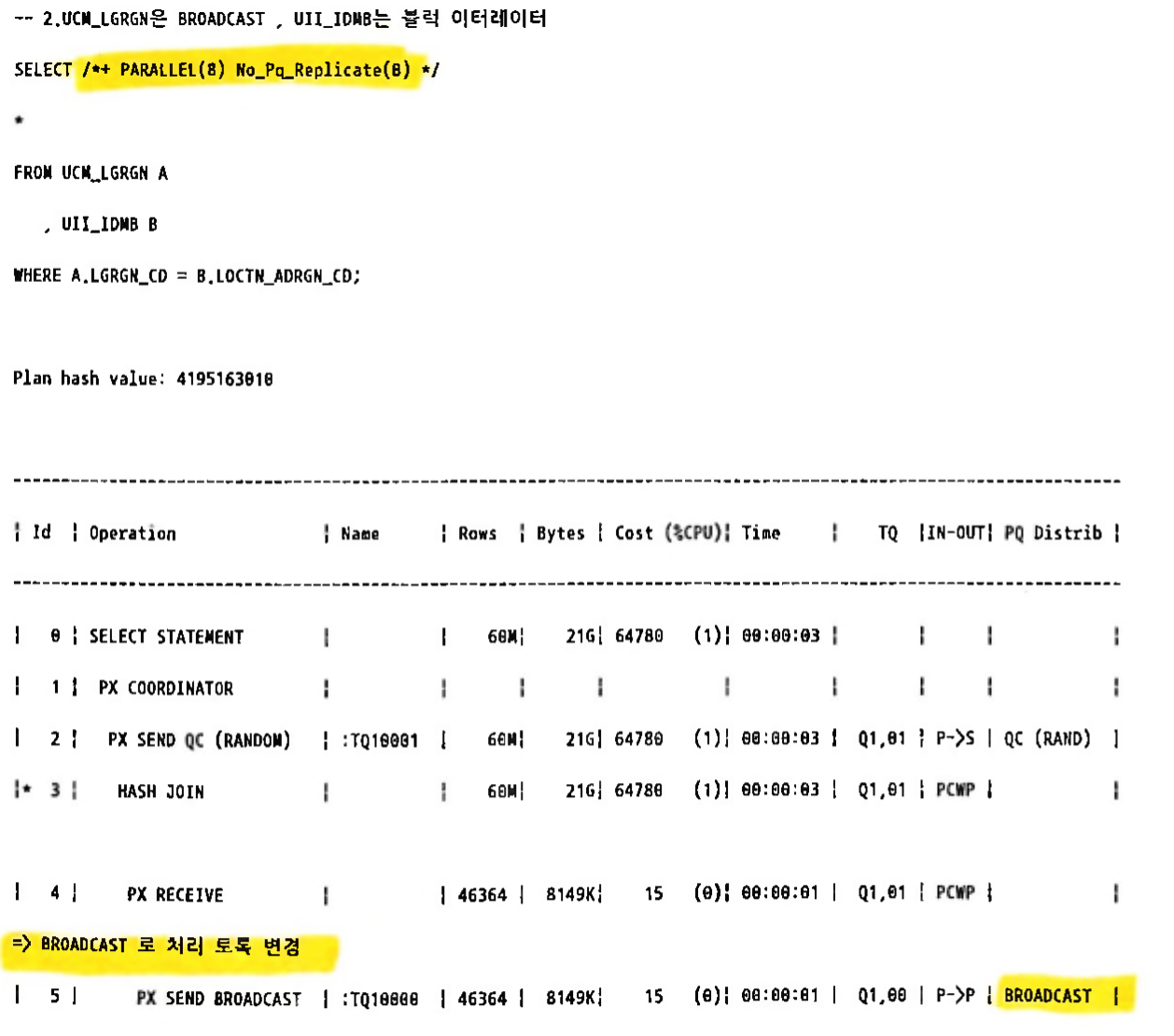
1.5.3 PQ_SKEW/NO_PQ_SKEW[편집]
- 다수의 로우가 같은 조인키값을 가지고 있어서 조인키의 분산값이 한쪽으로 치우친 경우
- 오라클에서 히스토그램을 생성해야 하지만 자동으로 병렬조인시 SKEW를 핸들링함
- 제약사항
- INNER 조인시
- 단일 컬럼 조인시만 가능, 여러개 컬럼은 안됨
- 병렬 HASH JOIN만 가능
- MERGE JOIN 은 안됨
- SKEW테이블은 일반 테이블만 (뷰, 결과셋은 기능제한됨)
- PQ_SKEW 힌트는 옵티마이저에게 병렬 조인에 대한 조인 키 값의 분포가 매우 왜곡되어 있다고 조언합니다.
- 즉, 높은 비율의 행이 동일한 조인 키 값을 가지고 있습니다.
- Tablespec에 지정된 테이블은 해시 조인의 프로브 테이블이다.
1.5.4 BF 블름필터(Bloom Filter)[편집]
- 어떤값이 어떤 집합에 속해 있는가를 검사하는 필터
- 패러럴 조인시 소비자간의 커뮤니케이션 데이터량 과 해시조인시 부하를 감소하기 위해 사용됨
- JOIN FILTER PRUNNING , RESULT CACHE
- 플랜에서 JOIN FILTER CREATE / USE
- :BF0000
1.5.4.1 블름필터 제어 힌트 ( PX_JOIN_FILTER / NO_PX_JOIN_FILTER )[편집]
- 사용 조건
- 해시/머지 조인시
- 파티션 조인시
- 병렬 PARALLEL 쿼리시
- 파티션/PARALLEL 둘다 아닌경우, 인라인뷰의 GROUP BY
- 선행 테이블의 상수조건이 없는 경우 오라클은 블름필터를 사용하지 않는다.
- 블름 필터를 만들때 선행 테이블은 필터집합을 만들때 사용.
1.5.5 PQ_DISTRIBUTE_WINDOW[편집]
- PQ_DISTRIBUTE_WINDOW 힌트는 윈도우 함수에 의해 생성된 행을 분배하는 방법에 대해 옵티마이져에게 지시함.
- PQ_DISTRIBUTE_WINDOW(@Query_block N) => N=1 for hash, N=2 for range, N=3 for list(예전 방식 9i)
- PQ_DISTRIBUTE_WINDOW 힌트는 아직 문서화되지 않았으며 MOS(내 oracle 지원)에는 참조가 없습니다.
select /*+parallel PQ_DISTRIBUTE_WINDOW(1)*/ table_name
, count(1) over (partition by table_name) cnt
from t_tab t\;Plan hash value: 4185789934
----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2426 | 46094 | 4 (25)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | WINDOW SORT | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | P->P | HASH |
| 6 | PX BLOCK ITERATOR | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWC | |
| 7 | INDEX FAST FULL SCAN| T_TAB_IDX1 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWP | |
----------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
PQ_DISTRIBUTE_WINDOW(@"SEL$1" 1)
INDEX_FFS(@"SEL$1" "T"@"SEL$1" ("T_TAB"."OWNER" "T_TAB"."TABLE_NAME"))
OUTLINE_LEAF(@"SEL$1")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/select /*+parallel PQ_DISTRIBUTE_WINDOW(2)*/ table_name
, count(1) over (partition by table_name) cnt
from t_tab tPlan hash value: 1125815052
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2426 | 46094 | 4 (25)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | WINDOW CONSOLIDATOR BUFFER| | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,00 | P->P | HASH |
| 6 | WINDOW SORT | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,00 | PCWP | |
| 7 | PX BLOCK ITERATOR | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWC | |
| 8 | INDEX FAST FULL SCAN | T_TAB_IDX1 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWP | |
------------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
PQ_DISTRIBUTE_WINDOW(@"SEL$1" 2)
INDEX_FFS(@"SEL$1" "T"@"SEL$1" ("T_TAB"."OWNER" "T_TAB"."TABLE_NAME"))
OUTLINE_LEAF(@"SEL$1")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/1.5.6 PQ_EXPAND_TABLE / NO_PQ_EXPAND_TABLE[편집]
- PQ_EXPAND_TABLE
- 파티션테이블인 경우 한곳에 편중된 파티션이 있을때, 옵티마이저가 UNION 절로 변경하여 편중된 파티션과 다른 파티션을 나누어 병렬처리로 수행함.
- (예) 인라인뷰내 파티션테이블을 (GROUP BY하는 경우)발생함
- 19c New Feature
- 튜닝 사례 1 : 한곳에 치중된 파티션을 UNION ALL 로 분리
SELECT *
FROM
(SELECT /*+ PQ_EXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....
- 튜닝 사례 2 : 한곳에 치중된 파티션을 UNION ALL 로 분리 하지 않음.
SELECT *
FROM
(SELECT /*+ NO_PQ_EXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블의 한곳의 파티션에 치중됨, 예를 들어 2000년 이전 데이터는 PT_2001파티션에 1억건 존재 , 나머지는 1백만건
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....1.5.7 PQ_CONCURRENT_UNION[편집]
- UNION ALL 성능향상
- UNION은 각각 SQL을 1개씩 SERIAL 하게 처리하는게 기본방식임
- 12C 부터 병렬쿼리 실행시 동시(CONCURRENT)에 처리토록 함
- 전체데이터 처리시 유리
- 부분범위 처리시 비추
- DEFAULT
select /*+PQ_CONCURRENT_UNION*/ * from (select * from t_obj union all select * from t_obj1)
Plan hash value: 1664138491
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 184K| 64M| 863 (1)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 184K| 64M| 863 (1)| 00:00:01 | Q1,00 | P->S | QC (RAND) |
| 3 | VIEW | | 184K| 64M| 863 (1)| 00:00:01 | Q1,00 | PCWP | |
| 4 | UNION-ALL | | | | | | Q1,00 | PCWP | |
| 5 | PX SELECTOR | | | | | | Q1,00 | PCWP | |
| 6 | TABLE ACCESS FULL| T_OBJ | 92299 | 10M| 431 (1)| 00:00:01 | Q1,00 | PCWP | |
| 7 | PX SELECTOR | | | | | | Q1,00 | PCWP | |
| 8 | TABLE ACCESS FULL| T_OBJ1 | 92299 | 10M| 431 (1)| 00:00:01 | Q1,00 | PCWP | |
----------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$2" "T_OBJ"@"SEL$2")
FULL(@"SEL$3" "T_OBJ1"@"SEL$3")
PQ_CONCURRENT_UNION(@"SET$1")
NO_ACCESS(@"SEL$1" "from$_subquery$_001"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
OUTLINE_LEAF(@"SET$1")
OUTLINE_LEAF(@"SEL$3")
OUTLINE_LEAF(@"SEL$2")
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
OPT_PARAM('_px_concurrent' 'false')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/1.5.8 PQ_FILTER[편집]
/*+ PQ_FILTER(SERIAL | NONE | HASH | RANDOM) */ -- 4개중 택1- 병렬서버에서 서브쿼리를 필터링할수 있는 기능.
- 서브쿼리 필터링은 일반적으로 메인쿼리가 모두 수행된 후 수행함.
- HASH방식과 RANDOM방식은 추가적인 버퍼링이 필요하므로 특별한 경우가 아니면 NONE 방식으로 사용하는것이 일반적일것으로 판단함.
- 다수의 서브쿼리 수행시 2개의 서브쿼리 모두 병렬서버에서 필터링됨.
- PQ_FILTER 사용예시 (with NO_UNNEST 힌트)
select /*+parallel PQ_FILTER(HASH)*/ * from t_obj1 o
where created in (select /*+ NO_UNNEST */last_analyzed
from t_tab t
where tablespace_name like :A)
;Plan hash value: 2440581449
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 110 | 12650 | 22159 (1)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | BUFFER SORT | | 110 | 12650 | | | Q1,01 | PCWP | |
|* 4 | FILTER | | | | | | Q1,01 | PCWP | |
| 5 | PX RECEIVE | | 92299 | 10M| 240 (1)| 00:00:01 | Q1,01 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | P->P | HASH |
| 7 | PX BLOCK ITERATOR | | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | PCWC | |
| 8 | TABLE ACCESS FULL| T_OBJ1 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | PCWP | |
|* 9 | TABLE ACCESS FULL | T_TAB | 2 | 30 | 26 (0)| 00:00:01 | | | |
------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$2" "T"@"SEL$2")
PQ_FILTER(@"SEL$1" HASH)
FULL(@"SEL$1" "O"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
OUTLINE_LEAF(@"SEL$2")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
OPT_PARAM('_px_filter_parallelized' 'false')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
- 서브 쿼리가 2개일 때 순서 조정 예시
- => ORDER_SUBQ 힌트(12c 이후) 로 서브쿼리의 수행순서 조정가능함.
SELECT /*+ PARALLEL(2) PQ_FILTER(NONE)
ORDER_SUBQ(@MAIN @SUB2 @SUB1) QB_NAME(MAIN) */
*
FROM T1 A
WHERE EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB1) */
1
FROM T2 B
WHERE B.C1 = A.C1)
AND EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB2) */
1
FROM T3 C
WHERE C.C1 = A.C1)
1.5.9 파티션에 사용 힌트[편집]
1.5.9.1 USE_PARTITION_WISE_DISTINCT[편집]
- 12c 이상
- USE_PARTITION_WISE_DISTINCT 힌트를 사용하면 파티션 그래뉼로 중복 값을 제거
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_DISTINCT */ DISTINCT c1, c2 FROM t1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
----------- [!!!]
| 4 | HASH UNIQUE | | 0 | | | Q1,00 | PCWP | |
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------1.5.9.2 USE_PARTITION_WISE_GBY[편집]
- USE_PARTITION_WISE_GBY 힌트를 사용하면 파티션 그래뉼로 그룹핑 수행 할 수 있음
- 병렬 서버 간의 데이터가 분배가 발생하지 않음 (P->P 분배가 없음)
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_GBY */ c1, COUNT(c2) FROM t1 GROUP BY c1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
----------> [!!!]
| 4 | HASH GROUP BY | | 0 | | | Q1,00 | PCWP | |
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------1.5.9.3 USE_PARTITION_WISE_WIF[편집]
- 18c 이상
- USE_PARTITION_WISE_WIF 힌트를 사용하면 파티션 그래뉼로 분석 함수 수행
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_WIF */ ROW_NUMBER () OVER (PARTITION BY c1 ORDER BY c2) FROM t1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
| 4 | WINDOW SORT | | 0 | | | Q1,00 | PCWP | | -- !
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------1.6 병렬 쿼리 튜닝 포인트[편집]
1.6.1 테이블 정보를 수집 하라[편집]
- 테이블 사이즈 조사
- 테이블 파티셔닝 여부
- 파티션 키
- 병렬처리가 가능한 인덱스(index_ffs , 파티션 로컬 인덱스)
1.6.2 스칼라퀴리는 인라인뷰로 변경을 검토하라[편집]
- 쿼리 결과를 전송하는 단계에서 수행되는 스칼라 서브쿼리는 QC가 담당
- 스칼라 쿼리를 인라인뷰로 변경 => lateral 쿼리 활용법
- 스칼라쿼리
- 인라인뷰로 변경
- 스칼라쿼리


1.6.3 플랜에서 QC(Query Cordinator) 위치를 확인 하라[편집]
1.6.3.1 DELETE 구문[편집]
- 튜닝전
- 튜닝 후


1.6.3.2 MERGE 구문[편집]
- 튜닝 전
- 튜닝 후



1.6.4 BROADCAST 테이블을 찾아라[편집]
- 대용량 임시/템프 테이블에 주의하라
- - 데이터 전환 이나 인터페이스를 위한 중간(임시) 테이블 생성시 반드시 중간 테이블에 대한 통계정보를 생성토록 한다.
- - 임시테이블은 주로 통계 정보가 생성되어 있지 않아. 통계정보 오류로 인해 브로드캐스트로 처리되는 경우가 많음.
- TEMP테이블 스페이스가 Full 차서 중지(ORA-01652 에러) 되는 경우가 많음
1.6.5 SQL/PLAN에서 튜닝 대상을 찾아라[편집]
- rownum => row_number() 윈도우 함수로 변경
- S->P 분산 프로세스
- round - robin

- 플랜

- - NL조인으로 round - robin 으로 처리중
- 튜닝 조치

- - HASH 조인 으로 변경
- 튜닝 결과 플랜 정보

1.6.6 조인이 효율적인지 검토 하라[편집]



1.6.7 심플하게 튜닝 하는 방법은 없을까?[편집]
- opt_param('_parallel_broadcast_enabled','false')
- pq_distribute(A hash hash)

1.7 입력/수정 성능저하시 검토 사항[편집]
1.7.1 INSERT 처리가 느릴때(SELECT~INSERT시 SELECT는 빠른데 INSERT가 느린경우)[편집]
1.7.2 시퀀스를 사용하는경우[편집]
- sequence cache size 증가 검토
- default 20 => 2000이상
1.7.3 DB링크 병렬처리 체크사항[편집]
- 소스디비의 프로세스 최대갯수 확인 필요
- 옵티마이져가 쿼리 변형을 수행함
- 쿼리 변형 방지 힌트 /*+ no_query_transformation */
- dblink로 가져올때는 병렬처리 불가
1.8 데이터 전환시 사용하는 병렬처리[편집]
1.8.1 데이터 전환을 위한 최적 세션 옵션[편집]
-- 세션에서 병렬 쿼리 작업 절차
ALTER SESSION ENABLE PARALLEL DML;
ALTER SESSION SET HASH_AREA_SIZE = 1024000000;
ALTER SESSION SET SORT_AREA_SIZE = 2147483647; -- 최대 2기가
ALTER SESSION SET SORT_AREA_RETAINED_SIZE = 2147483647;
ALTER SESSION SET WORKAREA_SIZE_POLICY = MANUAL;
-- 사용자가 지정한 sort_area_size가 모든 병렬 서버에게 적용.
-- sort_area_size를 크게 설정한 상태에서 지나치게 큰 병렬도를 지정하면
-- OS 레벨에서 페이징이 발생하고 심할 경우 시스템을 마비시킬 수 있음.
ALTER SESSION SET SKIP_UNUSABLE_INDEXES = TRUE;
ALTER SESSION SET DB_FILE_MULTIBLOCK_READ_COUNT=256; -- AIX는 최대 512
ALTER SESSION SET "_sort_multiblock_read_count" = 256;
ALTER SESSION SET "_db_file_optimizer_read_count" = 256;
ALTER SESSION SET "_db_file_exec_read_count" = 256;
ALTER SESSION SET "_serial_direct_read" = TRUE;
-- 병렬 실행 메시지 사이즈 32K
alter system set parallel_execution_message_size = 32768; -- 16384 -- 기본