효율적인 SQL 작성방법
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 효율적인 SQL 작성방법[편집]
1.1 어떤 SQL이 잘 이해 되는가?[편집]
- 다음 어떤 SQL이 읽기 쉬운가?
- [A 안]
SELECT A.CD_SEC, A.CD_SEC_NM, B.CD_KEY, B.CD_VALUE FROM TB1 A, TB2 B, TB3 C
WHERE A.CD_SEC = B.CD_SEC AND A.CD_SEC = C.CD_SEC AND B.CD_KEY = C.CD_KEY AND C.SYS_CD = ? ORDER BY CD_SEC, CD_KEY- [B 안]
SELECT A.CD_SEC
, A.CD_SEC_NM
, B.CD_KEY
, B.CD_VALUE
FROM TB1 A
, TB2 B
, TB3 C
WHERE A.CD_SEC = B.CD_SEC
AND A.CD_SEC = C.CD_SEC
AND B.CD_KEY = C.CD_KEY
AND C.SYS_CD = ?
ORDER BY CD_SEC, CD_KEY- [A안], [B안] 중 어느것이 더 가독성이 좋습니까? 혹은 이해가 잘되십니까?
- 물론 [B안]이죠?
- SQL을 효율적으로 작성하기위해서 가장 기본은 가독성을 좋게 작성 하는것입니다.
1.2 효율적인 SQL 작성 노하우[편집]
record_voice_over
- SQL 문 작성은 정확히 이해하고 최대한 이해하기 쉽게 작성해야합니다.
- 이해도를 높이기 위해서는 가능하면 인라인뷰 보다는 테이블 조인을 사용합니다.
- 모든 SQL은 바인드 변수를 제외하고 대문자를 사용합니다.
- 가독성을 위해 열을 맞추어 작성 합니다.
- 컬럼 나열시 다음줄에 내려쓸때는 첫줄의 컬럼 시작 위치에서 시작하고 ", "는 컬럼 앞에 적용하도록 합니다.
않좋은 예) DEPT_NO ,
NAME ,
------> |
좋은 예) DEPTNO
, NAME
| <-------- 공백을 일정하게 합니다.
- - TAB문자 대신 스페이스를 사용합니다. ( 에디터 마다 탭크기가 틀리기 때문)
- - " , " 콤마 사용시 뒤에는 반드시 공백을 적용합니다.(맨 마지막 컬럼 제외)
- - 연산자를 기준으로 양쪽 공백을 적용합니다.
- - 연산자 "<" , ">" 은 항상 "=" 과 함께 사용합니다.
- SQL명령어 와 테이블 명 혹은 컬럼명은 서로 좌우로 대칭이 되도록 키워드는 오른쪽 정렬 , 테이블/컬럼명은 왼쪽 정렬을 합니다.
1.2.1 SELECT , INSERT 문 작성법[편집]
- SELECT 문 예시
[명령어] [테이블/ 컬럼명]
------ -----------------------------------
SELECT A.CD_SEC
, A.CD_SEC_NM
, B.CD_KEY
, B.CD_VALUE
FROM TB1 A
, TB2 B
, TB3 C
WHERE A.CD_SEC = B.CD_SEC
AND A.CD_SEC = C.CD_SEC
AND B.CD_KEY = C.CD_KEY
AND C.SYS_CD = ?
ORDER BY CD_SEC, CD_KEY
-----> <----------------------- 좌우로정렬- 컬럼이 많을때는 왼쪽 정렬으로 하도록한다.
SELECT A.CD_SEC , A.CD_SEC_NM
, B.CD_KEY , B.CD_VALUE
, C.SYS_CD
|<------ |<-------- 왼쪽정렬
FROM TB1 A, TB2 B, TB3 C
WHERE A.CD_SEC = B.CD_SEC
AND A.CD_SEC = C.CD_SEC
AND B.CD_KEY = C.CD_KEY
AND C.SYS_CD = ?
ORDER BY CD_SEC, CD_KEY- INSERT 문 작성시
INSERT INTO TB1 (
SYS_CD
, SYS_NM
, PORT_NO
)
VALUES ( ?
, ?
, ?
)또는 , 컬럼이 많을때
INSERT INTO TB2 (
SYS_CD , SYS_NM , PORT_NO
, WEB_PORT_NO , DB_USER_ID , DB_PASS
, LOCATION , ACTIVE
, HOST_CD
)
VALUES ( ? , ? , ?
, ? , ? , ?
, ? , ?
, ?
)- UPDATE 문 작성시
UPDATE TWCM24
SET SYS_NM = ?
, PORT_NO = ?
, WEB_PORT_NO = ?
, DB_USER_ID = ?
, DB_PASS = ?
, LOCATION = ?
, ACTIVE = ?
, HOST_CD = ?
WHERE SYS_CD = ?또는
UPDATE TWCM24
SET SYS_NM = ? , PORT_NO = ? , WEB_PORT_NO = ?
, DB_USER_ID = ? , DB_PASS = ? , LOCATION = ?
, ACTIVE = ? , HOST_CD = ?
WHERE SYS_CD = ?1.2.2 바인드 변수 처리[편집]
record_voice_over
- DB성능 향상에 매우 중요합니다.
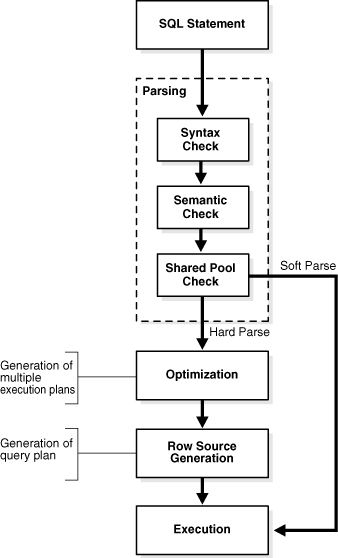
- 상용 RDBMS에서는 쿼리의 실행 단계는 크게 단계로 나뉩니다.
1) PARSING(문법검사)
2) >> EXECUTE(내부적인 실행)
3) >> 패치(결과값 리턴)- 위 3단계에서 1)문법검사단계를 파싱단계라고 하는데 이는 문법의 오류를 검사하고 내부적으로 컴파일 하는 파싱 단계를 줄이기 위해서 메모리에 기존에쿼리들을 캐싱해 놓습니다.
- 기존에 사용한적이 있는 쿼리는 파싱하지 않고 바로 다음단계를 처리 하게 됩니다.(이를 소프트파싱이라 한다, 반면 파싱하는것은 하드 파싱이라한다.)
- 예를 들어 아래의 쿼리는 같은 결과과 나오지만 각 다른 쿼리라고 판단하여 작업을 하게 됩니다.
SELECT EMP_NO FROM EMPLOYEE WHERE EMPID = 10;
SELECT emp_no FROM employee WHERE empid = 10 ;
SELECT emp_no FROM employee WHERE empid = 20 ;
SELECT EMP_NO
FROM EMPLOYEE
WHERE EMPID = 20 ;- 즉, 100% 동일해야 SQL파싱이 발생하지 않습니다.
- 이를 동일한 쿼리로 인식시키기 위해서 바인드 변수를 사용하여야 합니다.
SELECT EMP_NO FROM EMPLOYEE WHERE EMPID = ?- 이렇게 물음표(?) 등의 예약된 문자로 바인드 변수를 지정하여 사용하면 동일 SQL이 있다면 파싱단계를 거치지 않고 바로 쿼리가 실행되게 되어 성능이 향상 됩니다.
1.2.3 공통코드[편집]
record_voice_over 나홀로 프로그램을 개발할때 크게 관련이 없지만 여러사람이 공동으로 개발하는 프로젝트라면 공통코드 테이블 만들어서 사용합니다.
예를 들어 배송 진행 단계를 코드화 하고 싶다면 , 배송이라는 코드를 0.기본,1.배송신청,2.배송 진행중,3.배송완료.. 등으로 코드를 공통코드 테이블에 등록하여 만들면 됩니다. 통상 [공통코드 그룹],[공통코드 상세] 2개의 테이블을 만들어서 서로 조인하여 데이터를 가져오도록 설계합니다. [공통코드 그룹] 코드그룹아이디,코드그룹명,사용유무 [공통코드 상세] 코드그룹아이디,상세코드,상세코드명,사용유무,생성일자....
- 이렇게 하여 실제사용하는 업무테이블과 조인하여 사용 하면 프로그래밍시 별도 코드를 관리할 필요가 없어집니다.
1.2.4 서브쿼리[편집]
- 스칼라 서브쿼리 (Scala SubQuery)
- :Select 절에서 사용하는 서브쿼리
- 인라인뷰 (Inline View)
- :From 절에서 사용하는 서브쿼리
- 서브쿼리
- :Where 절에서 사용하는 서브쿼리(일반적인 서브쿼리)
SELECT AAA
, (SELECT BBB FROM C) AS BBB => 여기 SELECT절에 사용된 서브쿼리는 스칼라 서브쿼리 입니다.
FROM D , (SELECT ...FROM ) => 여기 FROM절에 사용된 서브쿼리는 인라인 뷰 라고 합니다.
WHERE A IN ( SELECT .... FROM ... C) => 여기 WHERE절에 사용된 서브쿼리는 서브쿼리 라합니다1.2.4.1 스칼라 서브쿼리[편집]
- 쉽게 설명하자면 스칼라 서브쿼리는 함수와 같은 표현방식입니다.
- 장점은 함수처럼 손쉽게 원하는 결과를 얻을수 있다는것입니다.
- 예를 들어서 직원별로 총월급여 합계를 가져오는 쿼리 실행시
- 직원을 가져오는 쿼리에서 스칼라 서브쿼리로 해당직원은 월급여 합계를 구하면 됩니다.
- 예를 들어서 직원별로 총월급여 합계를 가져오는 쿼리 실행시
- 단점은 프로그래밍 시 FOR문이나 WHILE 문처럼 반복적으로 처리 되기 때문에 해당 레코드가 100건이면 똑같은 스칼라 서브쿼리가 100번 실행하게 됩니다.
1.2.5 함수[편집]
record_voice_over
- 프로그래밍이 사용하는 함수와 같은 개념으로 이해하시면 됩니다.
- 다만 차이점이 있다는 함수가 시스템 내장 함수와 사용자가 만든 함수가 있는데 일반적으로 시스템 내장함수가 속도가 빠르게 동작합니다.
- 함수도 내부적으로 입력값이 같은건에 대해서 캐싱이 발생하여 빠르게 처리 하기도합니다.
- 한번 함수를 생성하면 컴파일되어 DB에 내장됨으로 추후 다른사용자가 별도로 컴파일 없이 사용할수 있다는 장점이 있습니다.
1.2.6 데이타 타입 유의사항[편집]
record_voice_over
- 문자열을 저장하는 타입은 DBMS마다 조금은 다르지만 CHAR,VARCHAR 형을 지원합니다.
- CHAR 타입은 고정형 문자열을 저장시 사용됩니다.
- 예를 들어 성별은 '남','여' 이므로 1자리를 지정하게 됩니다.
- => CHAR(1)
- 예를 들어 성별은 '남','여' 이므로 1자리를 지정하게 됩니다.
- VARCHAR 타입은 비고정형 문자열을 저장하게 됩니다.
- 예를 들어 1 ~ 10자의 문자가 되겠습니다.
- => VAHRCHAR(10)
- 저장공간을 줄여주기 때문에 일반적으로 많이 사용합니다.
- 예를 들어 1 ~ 10자의 문자가 되겠습니다.
- 문자열의 저장하는 데이타 타입에 따라 우리가 같은 값이 들어 있다라고 생각하지만 다르게 처리되는 경우가 있습니다.
- 예를 들어 'ABC' 이라는 문자열을 CHAR(10) , VARCHAR(10) 에 저장한다고 할때
- CHAR(10) 자리에는 'ABC_______' 처럼 ABC뒤에는 공백이 들어가게 됩니다.
- VARCHAR(10) 은 'ABC'만 저장되어있습니다.
- 예를 들어 'ABC' 이라는 문자열을 CHAR(10) , VARCHAR(10) 에 저장한다고 할때
- 서로 비교하면 다르다는것입니다. 'ABC_______' != 'ABC' 가 되게됩니다.
1.3 사용금지 및 제한해야하는 SQL[편집]
record_voice_over SQL 성능을 결정하는 요소들
- 1) 어플리케이션에 WHERE 조건 전체를 넘기는 방식
예) SELECT ... FROM A WHERE 1=1 AND ... [동적으로 발생되는 쿼리문]
: SQL 쿼리문을 봐서 개발의도를 파악할수 없음- 조건이 인덱스 키일경우에는 튜닝할수 없음
- 2) * 사용금지
: 꼭 필요한 컬럼나 가져와서 사용할것
데이타가 많을수록 성능부하가 발생함.
- 3) WHERE 절에 사용되는 컬럼 변형금지
: 왼쪽에 기술되는 컬럼은 변형을 하지 않도록 하고 오른쪽에 오는 상수/변수를
변형하여 사용한다.
예) TRIM(A) = B => 사용금지
A = TRIM(B) => 형태로 변경 하여야 인덱스를 타게됨.컬럼을 변형할경우 비교 대상이 인덱스에 없기 때문에 인덱스를 활용할수 없게 된다.
- 4) 습관적인 혹은 불필요한 함수 사용금지
습관적으로 컬럼에 NVL(),TRIM()등의 함수를 적용하는경우가 있는데 사용을
자제해야한다.
널이거나 공백이 들어가는 경우는 프로그램에서 제어를 하거나
DB설계시 DEFAUL 0 등으로 처리 하면 해결할수 있다.
- 5) SUBSTR() 함수
실무에서 문자를 해당 길이 많큼 잘라서써는 경우에 많이 사용되는 함수.
예를들어 년월일 컬럼에서 년월만 사용하고자 할경우
SELECT .... FROM A
WHERE SUBSTR(TO_CHAR(DATE형 날짜컬럼,'YYYYMMDD'),0.8) = '20140601' FROM TABLE1;
-- 이경우는 DATE형 컬럼에 인덱스가 있더라고 함수사용으로 인하여
변형 되었기 때문에 인덱스를 타지 못함.(튜닝 후)
SELECT DATE형 날짜 컬럼 BETWEEN TO_DATE('20140601',YYYYMMDD')
AND TO_DATE ('20140601'||' 235959','YYYYMMDD HH24MISS')
-- 인덱스가 타도록 변경- 6) GROUP BY , ORDER BY , MIN /MAX FLOOR ,TOP ,UNION 사용이 전체 데이터를 처리하므로 사용시
주의가 필요함. 어떻게 대체할수 있는지 고민해야함.
- 7) LIKE '앞%'는 인덱스 타지 못함.
%가 앞쪽에 퉅여사용하는 쿼리는 인덱스 사용할수 없음. LIKE ' 뒤%'는 사용가능
- 8) 부정형 비교
<> , != , NOT IN , NOT LIKE 를 사용하는 경우 인덱스를 사용하지 못하게 된다.
가능하면 긍정적인 쿼리로 변경하여 처리 토록 한다.
- 10) 암묵적인 형변환에 주의 할것 (INDEX 타지 못함)
- WHERE 문자 컬럼 = 숫자 사용시 암묵적인 형변환 발생 => to_number(문자 컬럼) = 숫자 로 변경됨- WHERE 숫자 컬럼 = 문자 사용시 암묵적인 형변환 발생 => 숫자 컬럼 = to_number('문자') 로 변경됨- WHERE 숫자 컬럼 LIKE '10%' 는 암묵적으로 형변환 발생 => WHERE TO_CHAR(숫자 컬럼) LIKE '10%'