SQL 실행원리
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 SQL 실행 원리[편집]
1.1 SELECT 문장의 실행 원리[편집]
(SELECT 문장의 실행 4단계) [1] Parse(구문 분석 단계) [2] BIND(바인드) [3] Execute(실행) [4] Fetch |
1.1.1 Parse(구문 분석 단계)[편집]
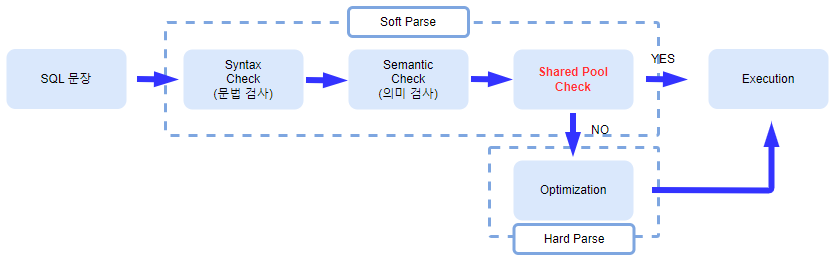
- 사용자가 SQL 문장을 수행하면 사용자 PC 쪽에 User Process라는 프로세스가 해당 SQL 문장을 서버의 Server Process로 전달
- (User Process: SQL 실행 프로그램(SQL*PLUS, SQL Developer, Toad, Orange))
- User Process는 결과가 나올 때까지 기다림.
- SQL 문장을 받은 Server Process는 Syntax Check(문법 검사) -> Semantic Check(의미검사)를 수행한 후 권한 검사(어떤 사용자가 해당 오브젝트에 접근할 수 있는 권한이 있는지 확인하는 과정)를 수행
- Syntax Check(문법 검사): SELECT, FROM, WHERE 같이 Oracle 키워드,문법 검사
- Semantic Check(의미 검사): Oracle 키워드 사이사이에 테이블 이름, 컬럼 이름과 같은 오브젝트 검사
- Shared Pool의 Library Cache에서 공유되어 있는 실행계획이 존재하는지 검사(여기까지가 Soft Parse 단계임.)
- (Library Cache: 한 번이라도 실행된 SQL, PL/SQL 문장과 해당 문장의 실행계획이 공유되어 있는 SGA 내부에 존재하는 공간)
- 공유되어 있는 실행계획이 있다면 바로 Execution 단계로 넘어가고, 아니면 옵티마이저를 찾아가서 실행계획 생성 요청.
- Optimizer(옵티마이저): Server Process로부터 요청을 받은 옵티마이저는 Data Dictionary 등을 참조해 실행계획을 생성(Soft Parse에 비해 시간도 오래 걸리고 힘든 과정이라 Hard Parse 이라 함)
- 옵티마이저는 실행계획을 만들 때 여러 개를 만들고, 거기서 비용을 따져서 가장 효율적인 실행계획 1가지를 선택함.
- 실행계획을 받은 Server Process는 실행계획을 Library Cache에 등록하고, PGA로 복사해서 가져온 후 Execution 단계로 넘어감.
1.1.1.1 Soft Parse[편집]
- User Process(사용자 PC)가 SQL 문장을 Server Process(서버)로 전달하면 Server Process는 SQL Parser를 통해서 각 SQL 문장에 쓰인 키워드나 컬럼명 등을 분석해서 Parse Tree를 생성.
- Parse Tree 생성 과정에서 Syntax Check 를 수행하고, 이상이 없으면 Semantic Check를 수행
- 키워드의 스펠링,문법이 틀렸을 경우 Parse Tree 생성 과정에서 오류가 발생하게 되고, Syntax Check를 했으나 없는 오브젝트(테이블)을 조회하려고 했을 경우에는 Semantic Check에서 오류가 발생함.
- Syntax Check와 Semantic Check 과정을 거치면서 해당 문법이 올바른지, 해당 테이블이 존재하는지 여부를 알기 위해 Data Dictionary를 사용
- 자주 사용하는 Data Dictionary는 SGA의 Shared Pool 안에 있는 Dictionary Cache에 캐싱함.
- SQL 문장에 오류가 없다면 SQL 문장을 ASCII 값(숫자 값)으로 변경한 후 해당 숫자 값을 HASH 함수를 통해 특정 HASH 값으로 변경함.
- 여기서 얻은 HASH 값과 Shared Pool 안에 있는 Library Cache에 있는 HASH 값들을 비교해서 동일한 값이 있는지 확인(이 과정을 커서 공유(Cursor Sharing) 또는 Soft Parse라고 함.
- HASH 값이 들어가 있는 부분을 Hash Bucket(해쉬 버킷)이라고 함. 해쉬 버킷 안에는 커서(cursor)들이 들어있음.
- 커서란 메모리에 어떤 데이터를 저장하기 위해 만드는 임시 저장 공간임.
- 일반적으로 공유 커서, 세션 커서, 어플리케이션 커서가 있음.
- 공유 커서의 역할은 이미 한 번 수행되었던 SQL 문장의 실행계획과 관련 정보를 보관하고 있다가 재활용 함으로써 Hard Parse의 부담을 줄여 SQL 문장의 수행 속도를 빠르게 하는 것임.
- 공유 커서는 부모 커서와 자식 커서로 나뉘게 되는데, SQL 문장 자체에 대한 값은 부모 커서에 있지만 사용자나 옵티마이저 모드 같은 정보는 자식 커서에 있음.
- 따라서, A와 B가 각각 다른 계정으로 DB에 로그인 한 후 동일한 SQL 문장을 실행했다면 같은 부모 커서를 조회하더라도 자식 커서가 서로 달라서 커서 공유를 할수 없음.
- 일반적으로 Library Cache에는 수많은 SQL 문장과 실행 계획이 들어있기 때문에 실행 계획을 찾을 때 커서를 하나씩 찾아보는 것은 시간이 너무 오래 걸립니다.
- 그래서 Oracle은 어떤 커서에 어떤 데이터가 들어있는 지를 Hash List를 통해 관리.
- Hash List에 들어있는 정보들은 Chain 구조로 데이터가 연결되어 있음.
- Hash 값을 통해 Library Cache에서 일치하는 값을 찾는 과정은 Hash Bucket을 찾은 것입니다.
- 그 안에 커서를 조회하여 빈자리가 있으면 그 자리에 저장하는 Heap 구조(불연속적으로 저장됨).
- Heap 구조는 데이터를 저장할 때는 속도가 빠르지만 데이터를 찾을 때는 시간이 오래 걸린다는 단점이 있음.
- Hash List에서 연관된 데이터를 Chain 구조로 저장해서 데이터를 찾기 쉽게 함.
- 문제는 Hash List는 1개 밖에 없다는것 . 많은 사용자가 하나의 Hash List를 동시에 조회하려 하는 문제를 해결하기 위해 래치를 부여함.(대기 번호표 같은)
- 그래서 Oracle에서는 Library Cache를 탐색하기 위해서는 반드시 Library Cache Latch를 갖도록 합니다.
- Hash List를 조회하기 위한 번호표를 받아 차례대로 조회할 수 있도록 함.
- 순서가 될 때까지 다른 사용자는 기다려야 하기에 성능이 저하될 수 밖에 없음(이 문제를 해결하기 위해서 Session_Cached_Cursors 파라미터 제공).
- 그 안에 커서를 조회하여 빈자리가 있으면 그 자리에 저장하는 Heap 구조(불연속적으로 저장됨).
1.1.1.2 Hard Parse[편집]
- Library Cache에 실행 계획이 존재하지 않는다면, 옵티마이저를 통해 실행 계획을 받고 Execution 단계로 넘어감.
- 옵티마이저는 크게 Rule Based Optimizer(RBO)와 Cost Based Optimizer(CBO)로 나눠짐
1.1.1.2.1 RBO (Rule Based Optimizer)[편집]
| Level | 접근 경로 |
|---|---|
| 1 | Single Row by Rowid |
| 2 | Single Row by Cluster Join |
| 3 | Single Row by Hash Cluster Key with Unique or Primary Key |
| 4 | Single Row by Unique or Primary Key |
| 5 | Clustered Join |
| 6 | Hash Cluster Key |
| 7 | Indexed Cluster Key |
| 8 | Composite Index |
| 9 | Single-Column Indexes |
| 10 | Bounded Range Search on Indexed Columns |
| 11 | Unbounded Range Search on Indexed Columns |
| 12 | Sort-Merge Join |
| 13 | MAX or MIN of Indexed Column |
| 14 | ORDER BY on Indexed Column |
| 15 | Full Table Scan |
- 요청된 SQL문이 있다면 15번부터 하나씩 대입하면서 적당한 실행 계획을 찾게 됩니다.
- RBO의 문제는 모든 SQL이 15가지 경우 안에서만 실행 계획을 만들어야 한다는 것입니다.
- 11g 버전 부터 RBO는 지원되지 않습니다.
1.1.1.2.2 CBO (Cost Based Optimizer)[편집]
- CBO는 실행 계획을 세울 때 Data Dictionary 정보를 확인
- Hard Parse는 Soft Parse에 비해 수행 시간이 오래 걸리기 때문에 가능한 Soft Parse를 할 수 있도록 쿼리를 작성해 주는 것이 중요
- 만약 Hard Parse를 수행 해야 한다면, 옵티마이저가 실행 계획을 잘 세울 수 있도록 통계정보 생성,좋은 인덱스 생성, 공간 관리 같은 일을 통해 좋은 실행 계획을 세울 수 있도록 관리해야 함.
1.1.2 BIND(바인드)[편집]
- Bind 변수를 사용하여 Hard Parse를 줄이고 성능을 향상 시킬 수 있는 최선의 방법임으로 반드시 사용토록 함.
- 학번과 이름을 Bind 변수값을 :a와 :b 형태로 만들어 Soft Parse가 가능하도록 함.
select *
from 학생
where 학번 = :a
and 이름 = :b;
1.1.3 Execute(실행)[편집]
- Execute 단계에서는 SGA 내 Database Buffer Cache의 블록들 중에 SQL 문장에 대해 캐싱되어 있는 값이 있는지 조회하고 캐싱되어 있다면 바로 Fetch를 수행함.
- Server Process가 DB Buffer Cache에서 데이터를 조회하는 원리는 찾는 블록의 주소를 Hash 값으로 만들고 이 Hash 값과 일치하는 값을 DB Buffer Cache의 Hash List에서 탐색.
- 캐싱되어 있지 않다면 Server Process는 Database의 Data File에서 해당하는 블록을 DB Buffer Cache로 복사함.
emoji_objects 블록(Block) : Oracle은 Data File -> DB Buffer Cache / DB Buffer Cache -> Data File로 데이터를 복사할 때 가장 최소 단위는 블록임
* DB_BLOCK_SIZE: 블록 크기를 결정하는 파라미터
* 10g 부터 DB_BLOCK_SIZE의 디폴트값은 8K
1.1.4 Fetch[편집]
- DB Buffer Cache의 Block에서 원하는 데이터를 골라내서 User Process에 가져다 주는 과정이 Fetch(인출) 과정
- 정렬(sort)이 필요하다면 PGA에서 수행 (PGA 내 SQL Work Area의 Sort Area)
1.2 Update 문장의 실행 원리[편집]
- update의 경우 Parse, Bind까지는 동일한 과정을 거치나 Execute 과정이 select에 비해 좀 더 복잡함.
- DB Buffer Cache에 Server Process가 원하는 블록이 존재하는지 확인하고, 존재하지 않는다면 Data File에서 데이터 블록을 복사해오는 것까지는 동일.
- 하지만 update(insert, delete까지 모두 포함)의 경우 데이터가 변경된다는 것을 의미.
- Server Process는 변경되는 데이터의 변경 내역을 Redo Log Buffer에 기록.
- 그 후 Undo Segment에 이전 이미지를 기록한 후 DB Buffer Cache에 변경 사항을 기록.
- 트랜잭션(Transaction): 데이터의 변경