"병렬 쿼리 튜닝"의 두 판 사이의 차이
DB CAFE
(→병렬 처리 개수 조회) |
(→데이터 전환시 사용하는 병렬처리) |
||
| 806번째 줄: | 806번째 줄: | ||
ALTER SESSION SET "_db_file_exec_read_count" = 256; | ALTER SESSION SET "_db_file_exec_read_count" = 256; | ||
ALTER SESSION SET "_serial_direct_read" = TRUE; | ALTER SESSION SET "_serial_direct_read" = TRUE; | ||
| + | ==== 병렬 처리 개수 조회 ==== | ||
| + | -- 패러럴 실행 메시지 사이즈 32K | ||
alter system set parallel_execution_message_size = 32768; -- 16384 -- 기본 | alter system set parallel_execution_message_size = 32768; -- 16384 -- 기본 | ||
| − | |||
| − | |||
---- | ---- | ||
2023년 1월 17일 (화) 08:00 판
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
1 병렬 쿼리 튜닝[편집]
1.1 병렬처리 핵심은?[편집]
1.1.1 그래뉼[편집]
android The basic unit of work in parallelism is a called a granule.
Oracle Database divides the operation executed in parallel (for example, a table scan, table update, or index creation) into granules.
- 병렬로 처리할때 일의 최소 단위
1.1.1.1 블록 그래뉼[편집]
- PX BLOCK ITERATOR 라고 표시
- QC는 테이블로부터 읽어야할 범위의 블록 GRANULE로서 각 병렬 서버에게 할당
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
==========> 블록 이터레이터로 표시됨
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------1.1.1.2 파티션 그래뉼[편집]
- PX PARTITION RANGE ALL 또는 PX PARTITION RANGE ITERATOR 라고 표시
- 사용되는 시기
- Partition-Wise조인 시
- 파티션 인덱스를 병렬로 스캔할 시
- 파티션 인덱스를 병렬로 갱신할 때
- 파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
---------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000| 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
==========> 파티션 RANGE ... 로 표시됨
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES| 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST|26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
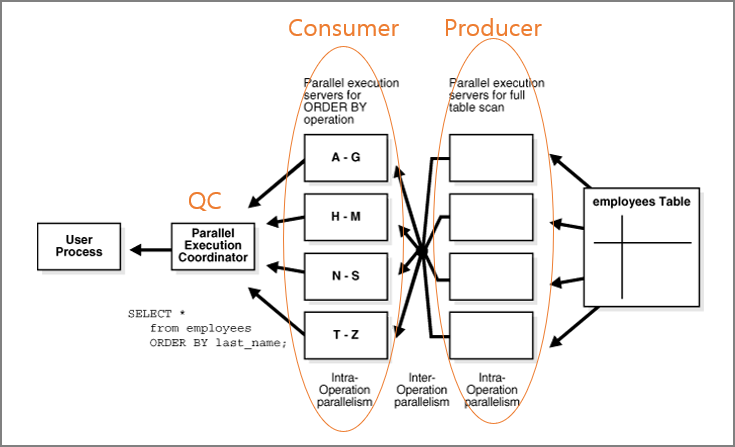
---------------------------------------------------------------------------------------------------1.1.2 생산자 VS 소비자[편집]
1.1.3 DOP 많을수록 좋을까?[편집]
- 테스트 예제
1.1.5 병렬 PLAN 해석하는 방법[편집]
-- 병렬 쿼리 확인
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST ADAPTIVE PARTITION PARALLEL OUTLINE'));--------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1638 | 7 (29)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (ORDER) | :TQ10002 | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | P->S | QC (ORDER) |
| 3 | SORT ORDER BY | | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | PCWP | |
| 4 | PX RECEIVE | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,02 | PCWP | |
| 5 | PX SEND RANGE | :TQ10001 | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | P->P | RANGE |
|* 6 | HASH JOIN | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | PCWP | |
| 7 | BUFFER SORT | | | | | | Q1,01 | PCWC | |
| 8 | PX RECEIVE | | 4 | 120 | 3 (0)| 00:00:01 | Q1,01 | PCWP | |
| 9 | PX SEND BROADCAST | :TQ10000 | 4 | 120 | 3 (0)| 00:00:01 | | S->P | BROADCAST |
| 10 | TABLE ACCESS FULL| DEPT | 4 | 120 | 3 (0)| 00:00:01 | | | |
| 11 | PX BLOCK ITERATOR | | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWC | |
| 12 | TABLE ACCESS FULL | EMP | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
--------------------------------------------------------------------------------------------------------------------
1.1.5.1 SQL 플랜상 튜닝 검토 사항[편집]
android # broadcast 는 소량테이블에 적합
- hash 는 대량 테이블에 적합
- P->S 는 튜닝 대상임. P->P로 바꿀수 있는 방법을 검토.sql수정도 좋다.
- round-robin 은 튜닝 대상임
- merge 나 insert ,delete문에만 주로 Parallel 힌트 사용. 하위 select 문에서는 가급적 지양 , 1:1 관계를 지향한다
- part key 플랜도 튜닝 대상. pq_disiribute(A hash hash) 힌트로 검토
- 오라클은 내부적 으로 어떤 힌트를 사용하고 있는지 볼까 ?
- OUTLINE
1.2 병렬처리 올바른 사용법은?[편집]
- 병렬도를 같게 지정하는 것이 바람직 함.
1.2.1 병렬 힌트를 어디에 어떻게 써야 하나?[편집]
1.2.2 DDL, DML 병렬처리[편집]
- DML
- SELECT
- INSERT
- UPDATE
- DELETE
- DDL
- : CREATE TABLE [테이블명] (.......) PARALLEL ( DEGREE [병렬범위] ) ;
- : CREATE TABLE [인덱스명] PARALLEL ( DEGREE [병렬범위] ) ;
- : ALTER TABLE [테이블명] PARALLEL ( 병렬범위 ) ;
- : ALTER INDEX[테이블명] PARALLEL ( 병렬범위 ) ;
- CREATE 예시
-- 테이블 생성
CREATE TABLE name ( column1 [data-type], ... )
Parallel 8;
-- 인덱스 생성 DOP 32
CREATE INDEX CYKIM.IX_TBL_X01
ON (MY_TABLE)
TABLESPACE TS_CY PARALLEL 32 NOLOGGING;
ALTER INDEX CYKIM.IX_TBL_X01 NOPARALLEL LOGGING;- ALTER 예시
ALTER TABLE name Parallel 8 ;1.2.3 DML문 에서도 SELECT 절만 PARALLEL 힌트를 사용하면 될까?[편집]
- DML에서 CONVENTIONAL / DIRECT PATH 차이점?
- Conventional Path
- :버퍼캐시에 적재, Default 방식
- 처리 속도 느림
- Row-level Lock
- Direct Path
- :병렬방식으로 Full Scan 할 때는 버퍼 캐시를 거치지 않고 곧바로 PGA 영역으로 읽어들이는 Direct Path Read 방식을 사용
- Table-level lock
- /*+ append */
- Conventional Path
12c 에서 처리 방법
- DML 병렬 처리
- DML 작업에서는 Paralle 힌트를 주어도 QC 가 작업 담당
- 병렬 DML 가능하도록 처리
- 12c 이전 에는 세션에 적용
SQL> alter session enable parallel dml;- 12c 부터는 힌트로 적용
/*+ ENABLE_PARALLEL_DML */- DML 병렬 처리시 주의사항
android #DML 병렬 처리시 주의사항
- 테이블 전체에 Exclusive 모드로 Lock 획득하므로 주의
- 커밋/롤백을 해야 SELECT 가능 함.
- DML 처리시 플랜에서 항상 QC 아래에 INSERT/UPDATE/DELETE 가 존재 해야 한다. (QC가 아닌 병렬서버에서 처리 토록 해야 한다.)
1.3 진행중인 병렬 처리가 잘되는지 궁금한데 ?[편집]
1.3.2 토드에서 모니터링 하는 방법[편집]
- Database - Session Browser
- IO 탭
- Waits 탭
- Current Statsment 탭
- Long Ops 탭
1.3.3 REAL MONITOR[편집]
- 사용법
SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR('5yfzxpu5593jw') FROM DUAL;- html
select dbms_sqltune.report_sql_monitor(sql_id=>''5yfzxpu5593jw'',type=>'html', report_level=>'ALL') from dual;1.3.4 병렬_쿼리_모니터링[편집]
1.3.5 병렬 처리 WAIT EVENT 확인 방법은?[편집]
1.3.5.1 병렬 처리 대기이벤트 종류[편집]

1.3.5.2 병렬 세션 대기,대기 이벤트,대기 클래스 조회[편집]
SELECT DECODE(A.QCSERIAL#, NULL, 'PAREMT', 'CHILD') ST_LVL,
A.SERVER_SET "SET",
A.SID,
A.SERIAL#,
STATUS,
EVENT,
WAIT_CLASS
FROM V$PX_SESSION A,
V$SESSION B
WHERE A.SID = B.SID
AND A.SERIAL# = B.SERIAL#
ORDER BY A.QCSID,
ST_LVL DESC,
A.SERVER_GROUP,
A.SERVER_SET
;1.3.5.3 WAIT EVENT - 상세 대기시간 확인[편집]
- V$SESSION + V$SESSSION_EVENT
SELECT S.INST_ID, S.SID, S.SQL_ID
, S.MACHINE, S.PROGRAM, S.EVENT
, S.BLOCKING_SESSION_STATUS
, SE.EVENT AS EVENT_DTL
, SE.WAIT_CLASS , SE.TIME_WAITED
, SE.MAX WAIT , SE.TOTAL_TIMEOUTS
FROM GV$SESSION S
, GV$SESSION_EVENT SE
WHERE S.SID = SE.SID
AND S.INST ID = 1
AND S SID=8281
-- AND SE.EVENT = 'gc current grant busy'
-- AND S.SQL ID = ''
AND SOL_ID IS NOT NULL
ORDER BY SE.TIME_WAITED DESC1.3.5.4 대기항목별 WAIT CLASS 확인[편집]
- V$SESSION_WAIT + V$SESSSION_WAIT_CLASS
SELECT A.SID, A.SEQ#, A.EVENT,P1TEXT
, A.STATE , A.WAIT_TIME_MICRO
, A.TIME_REMAINING_MICRO
, B.WAIT_CLASS#, B.WAIT_CLASS
, B.TOTAL_WAITS, B. TIME_WAITED
FROM GV$SESSION WAIT A
, GV$SESSION_WAIT_CLASS B
WHERE A.INST_ID = B.INST_ID
AND A.INST_ID =1
AND A.SID = B.SID
AND A.SID = :SID -- 1510
AND A.SERIAL# = B.SERIAL#1.4 병렬 처리가 왜 안되지 ?[편집]
1.4.1 병렬 처리 갯수 확인[편집]
- DOP 최대 갯수 = parallel_threads_per_cpu * cpu_count
SELECT *
FROM V$PARAMETER
WHERE NAME in ('parallel_threads_per_cpu','cpu_count')- DOP 최대 제약
SELECT * FROM V$PARAMETER
WHERE NAME IN ('parallel_degree_limit') ; -- CPU- DOP 최적 갯수
/*+ PARALLEL(auto) */
--- 플랜에서 확인 --
Note
I
automatic DOP: Computed Degree of Parallelism is 266
----------------------------------------------------1.4.2 병렬 환경 파리미터 상세 조회[편집]
SELECT *
FROM V$PARAMETER
WHERE NAME LIKE '%parallel%'
1.4.3 병렬처리가 안되는경우[편집]
1.4.3.1 서버에서 프로세스를 할당 받지 못할때[편집]
1.4.3.2 insert ~ select 의 병렬도가 다를때[편집]
1.4.3.3 파티션닝 테이블에 1개파티션만 타는경우[편집]
- 튜닝 실제 예시
1.4.3.4 LOB 컬럼 포함시[편집]
- lob 컬럼 포함시 => 오라클 19c 부터기능
1.4.3.5 DB 링크[편집]
1.5 병렬 힌트사용 방법[편집]
1.5.1 PQ_DISTRIBUTE[편집]

1.5.2 가능한 조합[편집]
- HASH - HASH : OUTER, INNER 크기가 비슷할 때
- BROADCAST - NONE : OUTER 테이블이 작을때
- NONE - BROADCAST : INNER 테이블이 작을때
- PARTITION - NONE : INNER 테이블 파티션 기준으로 OUTER 테이블을 파티션 하여 분배
- NONE - PARTITION : OUTER 테이블 파티션 기준으로 INNER 테이블을 파티션 하여 분배
- NONE - NONE : 두 테이블이 조인컬럼 기준으로 파티션 되어 있을때
1.5.3 PQ_REPLICATE / NO_PQ_REPLICATE(대량테이블)[편집]
- 각각 병렬서버에서 테이블 전체를 읽음
- BROADCAST 분산 하여 읽지 않음
- 로컬 캐시(SGA) 에서 빠르게 읽는 방식
- 복제라기보다는 조인처럼 생각
- 매우 작은 테이블 처리시 유리
- 튜닝 예시
1.5.4 PQ_SKEW/NO_PQ_SKEW[편집]
- 다수의 로우가 같은 조인키값을 가지고 있어서 조인키의 분산값이 한쪽으로 치우친 경우
- 오라클에서 히스토그램을 생성해야 하지만 자동으로 병렬조인시 SKEW를 핸들링함
- 제약사항
- INNER 조인시
- 단일 컬럼 조인시만 가능, 여러개 컬럼은 안됨
- 병렬 HASH JOIN만 가능
- MERGE JOIN 은 안됨
- SKEW테이블은 일반 테이블만 (뷰, 결과셋은 기능제한됨)
1.5.5 BF 블름필터(Bloom Filter)[편집]
- 어떤값이 어떤 집합에 속해 있는가를 검사하는 필터
- 패러럴 조인시 슬래이브(소비자)간의 커뮤니케이션 데이러량 과 해시조인시 부하를 감소하기 위해 사용됨
- JOIN FILTER PRUNNING , RESULT CACHE
1.5.5.1 PX_JOIN_FILTER / NO_PX_JOIN_FILTER[편집]
- 사용 조건
- 해시/머지 조인시
- 파티션 조인시
- PARALLEL 쿼리시
- 파티션/PARALLEL 둘다 아닌경우, 인라인뷰의 GROUP BY
- 선행 테이블의 상수조건이 없는 경우 오라클은 블름필터를 사용하지 않는다.
- 블름 필터를 만들때 선행 테이블은 필터집합을 만들때 사용.
1.5.6 PQ_DISTRIBUTE_WINDOW[편집]
PQ_DISTRIBUTE_WINDOW(@Query_block N) => N=1 for hash, N=2 for range, N=3 for list(예전 방식 9i)
rem ##################################
rem # Objects #
rem ##################################
alter session set optimizer_adaptive_plans = false;
alter system flush shared_pool;
drop table asc_dmy1;
drop table asc_dmy3;
create table asc_dmy1
parallel 8
as
select 'AAA' f001
from xmltable('1 to 300');
--note: this table has no parallel degree
create table asc_dmy3
as
select 'AAA' f001, 1 acc206
from dual;
rem #############################################
rem # SORT then distribute by HASH (Bug) #
rem #############################################
/*
leads to a HASH JOIN in Line 7, which imo must be a HASH JOIN BUFFERED (due to 2 active PX SENDs at 9 and 13)
This SQL hangs and never finishes
https://oracle-randolf.blogspot.com/2012/12/hash-join-buffered.html
"At most one data distribution can be active at the same time"
"Since it doesn't seem to be supported to have two PX SEND operations active at the same time,
some artificial blocking operation needs to be introduced, in this case the HASH JOIN BUFFERED,
that first consumes the second row source completely before starting the actual probe phase"
*/
select /*+ pq_distribute_window(@"SEL$1" 2) */
max(v.acc206) over (partition by v.f001) max_bew
from asc_dmy3 v,
asc_dmy1 e
where e.f001 = v.f001
and v.f001 = e.f001;
/*
-----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 419 | 6 (17)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 | 1 | 419 | 6 (17)| 00:00:01 | Q1,03 | P->S | QC (RAND) |
| 3 | WINDOW CONSOLIDATOR BUFFER| | 1 | 419 | 6 (17)| 00:00:01 | Q1,03 | PCWP | |
| 4 | PX RECEIVE | | 1 | 419 | 6 (17)| 00:00:01 | Q1,03 | PCWP | |
| 5 | PX SEND HASH | :TQ10002 | 1 | 419 | 6 (17)| 00:00:01 | Q1,02 | P->P | HASH |
| 6 | WINDOW SORT | | 1 | 419 | 6 (17)| 00:00:01 | Q1,02 | PCWP | |
|* 7 | HASH JOIN | | 1 | 419 | 5 (0)| 00:00:01 | Q1,02 | PCWP | |
| 8 | PX RECEIVE | | 1 | 415 | 3 (0)| 00:00:01 | Q1,02 | PCWP | |
| 9 | PX SEND HASH | :TQ10000 | 1 | 415 | 3 (0)| 00:00:01 | Q1,00 | S->P | HASH |
| 10 | PX SELECTOR | | | | | | Q1,00 | SCWC | |
| 11 | TABLE ACCESS FULL | ASC_DMY3 | 1 | 415 | 3 (0)| 00:00:01 | Q1,00 | SCWP | |
| 12 | PX RECEIVE | | 300 | 1200 | 2 (0)| 00:00:01 | Q1,02 | PCWP | |
| 13 | PX SEND HASH | :TQ10001 | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | P->P | HASH |
| 14 | PX BLOCK ITERATOR | | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | PCWC | |
| 15 | TABLE ACCESS FULL | ASC_DMY1 | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
-----------------------------------------------------------------------------------------------------------------------
*/
rem #############################################
rem # distribute by HASH then SORT (Success) #
rem #############################################
/*
leads to a HASH JOIN *BUFFERED* in Line 6, which is inevitably necessary imo
This SQL finishes immediately
*/
select /*+ pq_distribute_window(@"SEL$1" 1) */
max(v.acc206) over (partition by v.f001) max_bew
from asc_dmy3 v,
asc_dmy1 e
where e.f001 = v.f001
and v.f001 = e.f001;
/*
------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time | TQ |IN-OUT| PQ Distrib | OMem | 1Mem | O/1/M |
------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| | | | | | | |
| 1 | PX COORDINATOR | | | | | | | | | 73728 | 73728 | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 | 1 | 419 | 6 (17)| 00:00:01 | Q1,03 | P->S | QC (RAND) | | | |
| 3 | WINDOW SORT | | 1 | 419 | 6 (17)| 00:00:01 | Q1,03 | PCWP | | 20480 | 20480 | 8/0/0|
| 4 | PX RECEIVE | | 1 | 419 | 5 (0)| 00:00:01 | Q1,03 | PCWP | | | | |
| 5 | PX SEND HASH | :TQ10002 | 1 | 419 | 5 (0)| 00:00:01 | Q1,02 | P->P | HASH | | | |
|* 6 | HASH JOIN BUFFERED | | 1 | 419 | 5 (0)| 00:00:01 | Q1,02 | PCWP | | 3400K| 3091K| 8/0/0|
| 7 | PX RECEIVE | | 1 | 415 | 3 (0)| 00:00:01 | Q1,02 | PCWP | | | | |
| 8 | PX SEND HASH | :TQ10000 | 1 | 415 | 3 (0)| 00:00:01 | Q1,00 | S->P | HASH | | | |
| 9 | PX SELECTOR | | | | | | Q1,00 | SCWC | | | | |
| 10 | TABLE ACCESS FULL| ASC_DMY3 | 1 | 415 | 3 (0)| 00:00:01 | Q1,00 | SCWP | | | | |
| 11 | PX RECEIVE | | 300 | 1200 | 2 (0)| 00:00:01 | Q1,02 | PCWP | | | | |
| 12 | PX SEND HASH | :TQ10001 | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | P->P | HASH | | | |
| 13 | PX BLOCK ITERATOR | | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | PCWC | | | | |
|* 14 | TABLE ACCESS FULL| ASC_DMY1 | 300 | 1200 | 2 (0)| 00:00:01 | Q1,01 | PCWP | | | | |
------------------------------------------------------------------------------------------------------------------------------------------------
*/1.5.7 PQ_EXPAND_TABLE / NO_PQ_EXPAND_TABLE[편집]
- PQ_EXPAND_TABLE
- 파티션테이블인 경우 한곳에 편중된 파티션이 있을때, 옵티마이저가 UNION 절로 변경하여 편중된 파티션과 다른 파티션을 나누어 병렬처리로 수행함.
- (예) 인라인뷰내 파티션테이블을 (GROUP BY하는 경우)발생함
- 튜닝 사례 1 : 한곳에 치중된 파티션을 UNION ALL 로 분리
SELECT *
FROM
(SELECT /*+ PQEXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....- 튜닝 사례 2 : 한곳에 치중된 파티션을 UNION ALL 로 분리 하지 않음.
SELECT *
FROM
(SELECT /*+ NO_PQEXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블의 한곳의 파티션에 치중됨, 예를 들어 2000년 이전 데이터는 PT_2001파티션에 1억건 존재 , 나머지는 1백만건
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....1.5.8 PQ_CONCURRENT_UNION[편집]
- UNION ALL 성능향상
- UNION은 각각 SQL을 1개씩 SERIAL 하게 처리하는게 기본방식임
- 12C 부터 병렬쿼리 실행시 동시(CONCURRENT)에 처리토록 함
- 전체데이터 처리시 유리
- 부분범위 처리시 비추
- DEFAULT
1.5.9 PQ_FILTER[편집]
/*+ PQ_FILTER(SERIAL | NONE | HASH | RANDOM) */ -- 4개중 택1- 병렬서버에서 서브쿼리를 필터링할수 있는 기능.
- 서브쿼리 필터링은 일반적으로 메인쿼리가 모두 수행된 후 수행함.
- HASH방식과 RANDOM방식은 추가적인 버퍼링이 필요하므로 특별한 경우가 아니면 NONE 방식으로 사용하는것이 일반적일것으로 판단함.
- 다수의 서브쿼리 수행시 2개의 서브쿼리 모두 병렬서버에서 필터링됨.
- => ORDER_SUBQ 힌트(12c 이후) 로 서브쿼리의 수행순서 조정가능함.
- PQ_FILTER 사용예시 (with NO_UNNEST 힌트)
SELECT /* + PARALLEL(2) PQ_FILTER(HASH) */
*
FROM T1 A
WHERE EXISTS (SELECT /*+ NO_UNNEST */
1
FROM T2 B
WHERE B.C1 = A.C1)- 서브 쿼리가 2개일 때 순서 조정 예시
SELECT /*+ PARALLEL(2) PQ_FILTER(NONE)
ORDER_SUBQ(@MAIN @SUB2 @SUB1) QB_NAME(MAIN) */
*
FROM T1 A
WHERE EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB1) */
1
FROM T2 B
WHERE B.C1 = A.C1)
AND EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB2) */
1
FROM T3 C
WHERE C.C1 = A.C1)
FILTER
PX COORDINATOR
PX SEND QC(RANDOM)
PX BLOCK ITERATOR
TABLE ACCESS FULL T1
INDEX RANGE SCAN IX_T2
PX COORDINATOR
PX SEND QC(RANDOM)
FILTER
PX BLOCK ITERATOR.
TABLE ACCESS FULL 11
INDEX RANGE SCAN IX_12PX COORDINATOR
PX SEND QC(RANDOM)
FILTER
PX BLOCK ITERATOR
TABLE ACCESS FULL T1
INDEX RANGE SCAN X_13
INDEX RANGE SCAN IX_12
PX COORDINATOR
PX SEND QC(RANDOM)
BUFFER SORT
FILTER
PX RECEIVE
PX SEND HASH
PX BLOCK ITERATOR
TABLE ACCESS FULL T1
INDEX RANGE SCAN IX_T2
PX COORDINATOR
PX SEND QC(RANDOM)
BUFFER SORT
FILTER
PX RECEIVE
PX SEND ROUND-ROBIN
PX BLOCK ITERATOR
TABLE ACCESS FULL T1
INDEX RANGE SCAN IX_T21.5.10 파티션[편집]
- USE PARTITION_WISE_DISTINCT
- USE PARTITION_WISE_GBY
- USE PARTITION_WISE_WIF
1.6 튜닝포인트를 찾아라[편집]
1.6.1 테이블 정보를 수집 하라[편집]
- 테이블 사이즈 조사
- 테이블 파티셔닝 여부
- 파티션 키
- index_ffs , 파티션 로컬 인덱스
1.6.2 스칼라퀴리는 인라인뷰로 변경을 검토하라[편집]
- lateral 쿼리 활용법
1.6.3 BROADCAST 테이블을 찾아라[편집]
- 임시테이블에 주의하라
- : 임시테이블은 주로 통계 정보가 생성되어 있지 않아. 통계정보 오류로 인해 브로드캐스트로 처리되는 경우가 많음.
1.6.4 튜닝 대상을 찾아라[편집]
- rownum => row_number 윈도우 함수로 변경
- S->P 분산 프로세스
- round - robin
- 튜닝 실제 예시
1.6.5 조인이 효율적인지 검토 하라[편집]
- 튜닝 실제 예시 참조
1.6.6 심플하게 튜닝 하는 방법은 없을까?[편집]
- opt_param('_parallel_broadcast_enabled','false')
- pq_distribute(A hash hash)
- 튜닝 실제 예시
1.7 입력/수정 성능저하시 검토 사항[편집]
1.7.1 INSERT 처리가 느릴때(SELECT~INSERT시 SELECT는 빠른데 INSERT가 느린경우)[편집]
- hwm / reorg
1.7.2 시퀀스를 사용하는경우[편집]
1.7.3 V$SESSION_WAIT_CLASS[편집]
1.7.4 DB링크 병렬처리 주의사항[편집]
1.7.5 데이터 전환시 사용하는 병렬처리[편집]
<source lang=sql> -- 세션에서 병렬 쿼리 작업 절차 ALTER SESSION ENABLE PARALLEL DML; ALTER SESSION SET HASH_AREA_SIZE = 1024000000; ALTER SESSION SET SORT_AREA_SIZE = 2147483647; ALTER SESSION SET SORT_AREA_RETAINED_SIZE = 2147483647; ALTER SESSION SET WORKAREA_SIZE_POLICY = MANUAL; -- 사용자가 지정한 sort_area_size가 모든 병렬 서버에게 적용. -- sort_area_size를 크게 설정한 상태에서 지나치게 큰 병렬도를 지정하면 -- OS 레벨에서 페이징이 발생하고 심할 경우 시스템을 마비시킬 수 있음. ALTER SESSION SET SKIP_UNUSABLE_INDEXES = TRUE; ALTER SESSION SET DB_FILE_MULTIBLOCK_READ_COUNT=256; -- AIX는 최대 512
ALTER SESSION SET "_sort_multiblock_read_count" = 256; ALTER SESSION SET "_db_file_optimizer_read_count" = 256; ALTER SESSION SET "_db_file_exec_read_count" = 256; ALTER SESSION SET "_serial_direct_read" = TRUE;