오라클 아키텍처
DB CAFE
thumb_up 추천메뉴 바로가기
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
목차
- 1 데이터베이스
- 2 오라클 환경 설정
- 3 클라이언트 어플리케이션
- 4 서버 프로세스
- 5 데이터파일 과 테이블스페이스
- 6 리두 로그(REDO)
- 7 서버파라미터
- 8 컨트롤 파일
- 9 메모리관리
- 10 백그라운드 프로세스
- 11 패스워드 파일
- 12 로그파일 위치 정보
- 13 데이터 딕셔너리 뷰
- 14 스키마 오브젝트 와 데이터 저장방식
- 15 테이블
- 16 데이터 타입
- 17 인덱스 구조
- 18 뷰
- 19 시퀀스
- 20 시노님
- 21 디비링크
- 22 SQL 처리 과정
- 23 쿼리 처리 원리
- 24 변경 처리 원리
- 25 트랜잭션 처리 과정
- 26 락
- 27 인스턴스 시작 과 종료
- 28 복구 처리 과정
- 29 오라클 NET SERVICE
- 30 리스너
- 31 tnsnames.ora
- 32 sqlnet.ora
- 33 오라클 JOB, SCHEDULES
1 데이터베이스[편집]
- OS별 차이점
- 오라클은 이식이 매우 편리하도록 설계되었으나 물리 구조는 OS마다 다름 (윈도우, 유닉스, 메인프레임 등)
| OS | 특징 |
|---|---|
| 유닉스 | 멀티 프로세스 |
| 윈도우 | 스레드(단일 프로세스) |
| IBM 메인프레임 | 복수의 '주소 공간(address space)', 단일 인스턴스 |
1.1 데이터베이스 와 인스턴스 개념[편집]
| 구분 | 정의 | 비고 |
|---|---|---|
| 데이터베이스 | 물리적인 파일/디스크 집합 | DBF, ASM, RAW |
| 인스턴스 | 프로세스(스레드) + 공유 메모리 영역 | 하나 이상의 인스턴스는 하나의 데이터베이스를 마운트/오픈(RAC) |
2 오라클 환경 설정[편집]
- 오라클 실행에 필요한 환경 변수
- $ORACLE_SID
- $ORACLE_BASE
- $ORACLE_HOME
- 환경 변수 확인 방법
-- 유닉스/리눅스 환경 , oracle 계정 로그인
env|grep ORA2.1 ORACLE_HOME[편집]
- 오라클 환경변수($ORACLE_HOME, $ORACLE_SID)
- $ORACLE_HOME (or $HOME) : 오라클 관련 S/W가 설치되어 있는 기본 경로
android * $ORACLE_HOME의 이하의 중요한 디렉터리
- /database : 윈도우 서버 파라미터 파일이나 패스워드 파일이 존재
- /dbs : 유닉스/리눅스 버전 오라클의 서버 파라미터 파일이나 패스워드 파일이 존재
- /network/admin : 네트워크 접속과 관련된 설정 파일이 존재
- /bin : SQL*PIus 등 오라클 관련 프로그램과 오라클을 운영하고 관리하는데 유용한프로그램들 존재
- /sqlplus : SQL*Plus 관련 파일이 존재
- /rdbms/admin : 오라클 관련 SQL 파일이 존재
- /inventory : 설치한 도구들에 관한 정보나 ORACLE_HOME에 관련된 정보가 존재
2.2 ORACLE_BASE[편집]
- 오라클 환경변수 : $ORACLE_BASE
- OFA(Optimal Flexible Architecture)를 위한 오라클 기본 디렉토리 구조
- 이 경로 밑으로 오라클 프로그램을 설치
- controll file, redo log file, data file 이 있는 곳. (다른 files은 저장되지 않는다)
- $ORACLE_BASE/diag/rdbms/{DB명}/trace 에 트레이브 파일과 Alert{DB명}.log 파일이 위치한다.
- 이 경로 밑으로 오라클 프로그램을 설치
2.3 DBCA[편집]
- DBCA(Database Configuration Assistant) , DB 설치 도우미
- DBCA를 이용 Database 생성
2.4 SID[편집]
- SID(System Identifier) : 오라클 데이타베이스명
2.4.1 SID 와 서비스명(Service name)[편집]
- 테스트 환경이나 소규모 사이트의 경우 데이타베이스가 하나만으로 구성되어 있고 이런 경우라면 SID와 서비스명(service name) 을 구분할 필요가 없기 때문에 데이터베이스 이름(service name)이 SID가 된다
- RAC 로 구성하여 데이타베이스 두개가 동시 가동되는 경우라면 이 SID 가 서로 다를 수 있음
- 서비스명(Service Name) 이 더 큰 개념으로 SID 2개를 합쳐서 Service name으로 서비스가 가능
2.5 TNS 정보[편집]
- DB에 접속하는 클라이언트 프로그램의 경우에 접속하고자 하는 오라클 인스턴스 정보를 필요
- 서버IP , 오라클SID , 접속 프로토콜 같은 정보가 필요
- 이 정보를 하나로 묶어서 서비스명으로 대표하고, 이 서비스명으로 클라이언트 프로그램이 서버에 접속하는데 사용.
- 해당 정보는 클라이언트 서버의 tnsnames.ora 파일에 기재되어 있음.
2.6 오라클 클라이언트 접속 과정[편집]
1. 오라클 데이타베이스에 SQLPLUS로 접속(sys유저 + sysdba 권한으로 ).
sqlplus " / as sysdba"
-- or
sqlplus / as sysdba2. 오라클 데이타베이스 'service name'를 확인
SQL> SELECT NAME -- DB Name
, DB_UNIQUE_NAME -- Service Name
FROM v$database;3. 오라클 SID 확인.
SQL> SELECT instance FROM v$thread;2.7 인스턴스[편집]
select instance_name from v$instance;2.8 데이터베이스 확인[편집]
- 데이터베이스 체크사항
- $ORACLE_HOME/dbs 디렉토리 확인
$ ls -al
- oracle 사용자 관련 프로세스 확인
$ ps -aef | grep oracle
- oracle 관련 공유 메모리 확인
$ ipcs -a
- SQL*Plus 접속
$sqlplus / as sysdba
- 접속 실패 오류 예시
- $ORACLE_HOME/dbs 디렉토리 확인
SQL*Plus: Release 11.2.0.3.0 Production on Thu Sep 25 07:48:28 2014
Copyright (c) 1982, 2011, Oracle. All rights reserved.
ERROR:
ORA-12162: TNS:net service name is incorrectly specified
Enter user-name:2.9 인스턴스 시작[편집]
- Oracle 시작 단계 명령
| 단계 | 주요 특징 | 주요 수행 작업 |
|---|---|---|
| nomount |
|
|
| mount |
|
|
| open |
|
|
| read only | 읽기 상태로만 DB 열기 | |
| read write | 읽기 / 쓰기 상태로 DB 열기 |
2.9.1 NOMOUNT 단계까지만 시작 후 나머지 단계 진행[편집]
SQL> startup nomount;
SQL> alter database mount;
SQL> alter database open;2.9.2 MOUNT 단계까지 시작 한 후 나머지 단계 진행[편집]
SQL> startup mount;
SQL> alter database open;2.9.3 읽기전용인 상태로 Open[편집]
SQL> startup mount;
SQL> alter database open read only;2.9.4 Restricted Mode(제한된 모드)로 Open[편집]
데이터 생성이나 수정 등 모두 할 수 있지만 허가 받은 사용자(Restricted Session 이란 권한)만 접속 할 수 있도록 함
SQL> startup restrict;
-- 현재 open되어 있는 Instance를 restricted mode로 변경 하려면
SQL> alter system enable restricted session;
SQL> alter system disable restricted session;3 클라이언트 어플리케이션[편집]
4 서버 프로세스[편집]
4.1 세션[편집]
4.3 세션과 서버프로세스 확인[편집]
4.3.1 세션 확인[편집]
select * from v$resource_limit
where resource_name in ('sessions');4.3.2 서버 프로세스 확인[편집]
SQL> show parameter processes
NAME TYPE VALUE
------------------------------------ ----------- -----
aq_tm_processes integer 1
cell_offload_processing boolean TRUE
db_writer_processes integer 1
gcs_server_processes integer 0
global_txn_processes integer 1
job_queue_processes integer 1000
log_archive_max_processes integer 4
processes integer 150select * from v$resource_limit
where resource_name in ('processes');4.3.3 서버 프로세스 변경[편집]
SQL> alter system set processes=200 scope=spfile;
-- 서버 restart
SQL> shutdown immediate;
...
SQL> startup;5 데이터파일 과 테이블스페이스[편집]
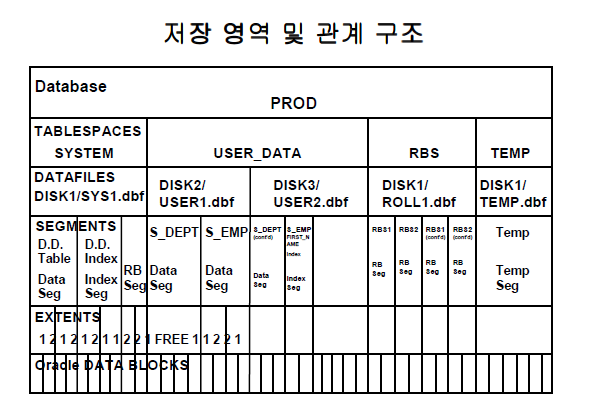
5.1 테이블스페이스 종류[편집]
5.2 데이터 파일[편집]
5.2.1 데이터파일 구성[편집]
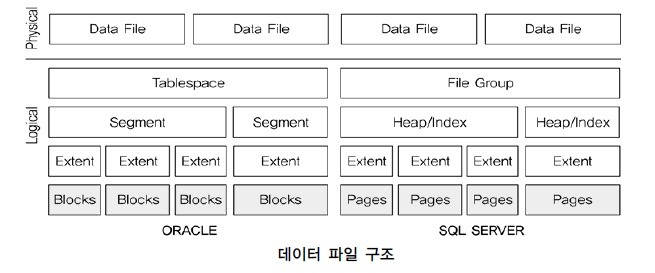
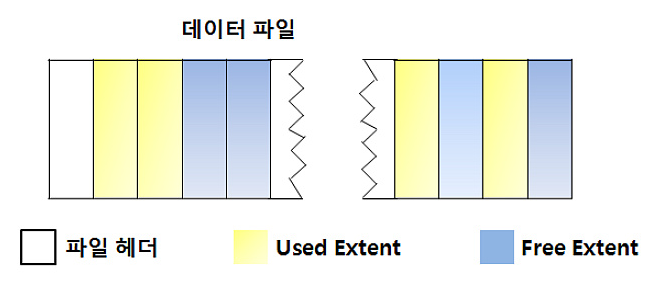
5.2.2 데이터 블럭 (Block)[편집]

5.2.3 익스텐트 (Extent)[편집]
- 확장 영역 할당 및 할당 해제
- 세그먼트가 extent를 할당 받는 경우
- - 생성될때(Created)
- - 확장될때(Extended)(계속해서 데이터가 들어와서 확장영역이 더 필요할때)
- - 변경될때(Altered)
- 세그먼트가 extent가 할당 해제되는 경우
- - 삭제될 경우(Dropped)
- - 변경될 경우(Altered)(그러나 하이워터마크의 바깥쪽 부분이 extents가 없기때문에 할당 해제 되는 경우가 없다.)
- - 잘릴경우
- 데이터베이스 버퍼캐시
5.4 테이블 스페이스[편집]
5.4.1 TABLESPACE 삭제[편집]
5.4.1.1 인덱스/테이블 TABLESPACE 변경 스크립트[편집]
5.4.2 언두 테이블스페이스 [편집]
5.4.3 템프 테이블스페이스 [편집]
5.4.3.1 TEMPORARY TABLESPACE 삭제[편집]
6 리두 로그(REDO)[편집]
- v$log 로 확인 가능
- 리두로그 버퍼가 가득 차면 아카이브파일로 기록
6.1 리두로그 파일[편집]
6.1.1 리두로그 버퍼 와 LGWR[편집]
6.1.1.1 아카이브 로그 모드 특징[편집]
- 데이터베이스를 운영중인 상태에서 백업이 가능.
- 시스템 테이블스페이스 외에는 온라인 복구가 가능하고, 복구중인 것은 제외한 다른 테이블스페이스는 복구중에도 운영 가능.
- 부분 복구가 가능.
- 백업파일과 아카이브 로그를 모두 유지해야 하며, 아카이브 로그는 많은 용량을 차지할 수 있으므로 디스크 용량 관리 필요
6.1.1.2 아카이브 로그모드 확인[편집]
SQL> ARCHIVE LOG LIST;6.1.1.3 아카이브 REDO 로그[편집]
- 파일 크기 , 파일 사용 위치
SELECT group#
, members
, bytes
, archived
, status
FROM v$log;6.1.1.4 아카이브 REDO 로그파일[편집]
SELECT group#
, status
, member
FROM v$logfile;6.2 리두로그 다중화 추가[편집]
alter database add logfile group 3
('/u01/app/oracle/oradata/testdb/disk1/redo03a.log',
'/u01/app/oracle/oradata/testdb/disk2/redo03a.log') size 30m;6.3 리두로그 그룹확인[편집]
select group#, thread#, sequence#, bytes/1024/1024 mbyte, members, status
from v$log
order by thread#, group#;6.4 리두로그 파일확인[편집]
- redo 로그 파일 위치 와 갯수 확인
SELECT group#
, status
, member
FROM v$logfile;- 로그 파일 포맷 변경
alter system set log_archive_format='%t_%s_%r.arc' scope=spfile;
- 로그스위치 실행
- 아카이브로그 모드 확인(sqlplus)
ARCHIVE LOG LIST;6.5 아카이브로그 모드 변경[편집]
- DB종료
shutdown immediate;
- DB MOUNT 모드로 시작
startup mount;
- 아카이브 로그모드로 변경
alter database archivelog;
- DB 오픈
alter database open;
- 아카이브 로그 파일 확인
-- 1. 데이터베이스 종료
SQL> shutdown immediate;
-- 2. 데이터베이스 마운트
SQL> startup mount
-- 3. 아카이브 로그 모드로 변경
SQL> alter database archivelog;
-- 4. 데이터베이스 오픈
SQL> alter database open;
-- * DB가 start 안될경우 pfile 확인(spfile 오류,삭제된경우 => pfile로 spfile 생성 [[오라클_pfile_spfile|pfile->spfile 생성방법]])
-- 아카이브 로그 파일 확인
select GROUP#,A.MEMBERS
, BYTES/1048576 MB, STATUS
from V$LOG A;6.6 일일 DB사용량(아카이빙 데이터) 계산[편집]
select trunc(first_time),count(*)*200,count(*)
from v$log_history
group by trunc(first_time)
order by 2 desc
;6.7 일별 시간당 로그 스위칭 처리 건리[편집]
SELECT TO_CHAR(FIRST_TIME,'YYYY-MM-DD')
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'00',1,0)),'999') "00"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'01',1,0)),'999') "01"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'02',1,0)),'999') "02"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'03',1,0)),'999') "03"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'04',1,0)),'999') "04"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'05',1,0)),'999') "05"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'06',1,0)),'999') "06"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'07',1,0)),'999') "07"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'08',1,0)),'999') "08"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'09',1,0)),'999') "09"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'10',1,0)),'999') "10"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'11',1,0)),'999') "11"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'12',1,0)),'999') "12"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'13',1,0)),'999') "13"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'14',1,0)),'999') "14"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'15',1,0)),'999') "15"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'16',1,0)),'999') "16"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'17',1,0)),'999') "17"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'18',1,0)),'999') "18"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'19',1,0)),'999') "19"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'20',1,0)),'999') "20"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'21',1,0)),'999') "21"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'22',1,0)),'999') "22"
, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'23',1,0)),'999') "23"
FROM V$LOG_HISTORY
GROUP BY TO_CHAR(FIRST_TIME,'YYYY-MM-DD')
ORDER BY TO_CHAR(FIRST_TIME,'YYYY-MM-DD') DESC7 서버파라미터[편집]
- 서버파라미터 조회
show parameter 파라미터명7.1 초기화파라미터[편집]
7.2 초기화파라미터 변경[편집]
7.3 초기화 파라미터 확인[편집]
7.4 텍스트 형식 초기화 파라미터 파일[편집]
8 컨트롤 파일[편집]
8.1 Control file 관리[편집]
8.1.1 control file 확인[편집]
- SQL> show parameter control_files
SQL> show parameter control_files
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
control_files string /app/ora11g/oradata/DB11/control01.ctl,
/app/ora11g/flash_recovery_area/DB11/control02.ctl- v$spparameter
SQL> select value from v$spparameter where name='control_files';
VALUE
--------------------------------------------------------------------------------
/app/ora11g/oradata/DB11/control01.ctl
/app/ora11g/flash_recovery_area/DB11/control02.ctl- v$controlfile
SQL> desc v$controlfile;
Name Null? Type
----------------------------------------- -------- ----------------------------
STATUS VARCHAR2(7)
NAME VARCHAR2(513)
IS_RECOVERY_DEST_FILE VARCHAR2(3)
BLOCK_SIZE NUMBER
FILE_SIZE_BLKS NUMBER
SQL> select name from v$controlfile;
SQL> !ls /app/ora11g/oradata/DB11/*.ctl
/app/ora11g/oradata/DB11/control01.ctl
SQL> !ls /app/ora11g/flash_recovery_area/DB11/*.ctl
/app/ora11g/flash_recovery_area/DB11/control02.ctl8.2 SPfile 환경에서 Control file 다중화[편집]
8.2.1 환경변수중에서 ORACLE이 들어가는 환경변수 출력[편집]
SQL> !env | grep ORACLE
ORACLE_OWNER=ora11g
ORACLE_SID=DB11
ORACLE_HOSTNAME=DB11
ORACLE_BASE=/app/ora11g
ORACLE_TERM=xterm
ORACLE_HOME=/app/ora11g/11g
SQL> !ls $ORACLE_HOME/dbs
hc_DB11.dat init.ora lkDB11 orapwDB11 peshm_DB11_0 spfileDB11.ora8.2.2 control_files의 값을 변경 control_files 위치 확인[편집]
SQL> select name,value from v$parameter where name like 'control_files';
NAME VALUE
-------------------- ------------------------------------------
control_files /app/ora11g/oradata/DB11/control01.ctl,
/app/ora11g/flash_recovery_area/DB11/control02.ctl
SQL> ALTER SYSTEM SET control_files = '/app/ora11g/oradata/disk4/control.ctl','/app/ora11g/oradata/disk5/control.ctl' scope=spfile;
System altered.8.2.3 control_file 은 오픈된 상태에서 이동시키지 못함으로 오라클을 종료[편집]
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
-- control 파일을 각각 disk4, disk5로 이동
SQL> !mv /app/ora11g/oradata/DB11/control01.ctl /app/ora11g/oradata/disk4/control.ctl
SQL> !mv /app/ora11g/flash_recovery_area/DB11/control02.ctl /app/ora11g/oradata/disk5/control.ctl
-- 컨트롤 파일이 제대로 이동됬는지 확인
SQL> !ls /app/ora11g/oradata/disk4
control.ctl
SQL> !ls /app/ora11g/oradata/disk5
control.ctl8.2.4 오라클 startup[편집]
SQL> startup
ORACLE instance started.
Total System Global Area 849530880 bytes
Fixed Size 9824 bytes
Variable Size 507514448 bytes
Database Buffers 335544320 bytes
Redo Buffers 5132288 bytes
Database mounted.
Database opened.
-- 컨트롤 파일 확인
SQL> select name, value from v$parameter where name like 'control_files';
NAME VALUE
-------------------- ------------------------------------------
control_files /app/ora11g/oradata/disk4/control.ctl,
/app/ora11g/oradata/disk5/control.ctl9 메모리관리[편집]

9.1 PGA[편집]
- PGA 관련 파라미터
- WORKAREA_SIZE_POLICY는 PGA Run-Time 메모리 할당 방식을 지정해 주는 파라미터로, MANUAL과 AUTO 관리 방식으로 나뉜다.
9.1.1 MANUAL 방식[편집]
- SORT_AREA_SIZE : Sort 작업을 위해 Oracle 프로세스가 최대로 사용할 수 있는 메모리 영역
- SORT_AREA_RETAINED_SIZE : Sort 작업이 완료된 후 결과 값을 유저 프로세스로 전달하는 패치 작업이 완료될 때까지 유지할 메모리 영역
- HASH_AREA_SIZE : Hash-Join 작업을 위해 Oracle 프로세스가 최대로 사용할 수 있는 메모리 영역
- BITMAP_MERGE_AREA_SIZE : 비트맵 인덱스에 대한 Range Scan을 통해 추출된 비트맵들의 병합(Merge)을 위해 Oracle 프로세스가 최대로 사용할 수 있는 메모리 영역
- CREATE_BITMAP_AREA_SIZE : 비트맵 인덱스 생성 시 Oracle 프로세스가 최대로 사용할 수 있는 메모리 영역
9.1.2 AUTO 방식[편집]
- PGA_AGGREGATE_TARGET : DB에 접속된 모든 Oracle 서버 프로세스들의 가용 PGA Target 크기이며, 값이 0 이상 할당될 경우 WORKAREA_SIZE_POLICY는 AUTO로, 메모리 사용 후 즉시 OS로 반납시키는 _USE_REALFREE_HEAP는 TRUE로 자동 변경된다.
- PGA_MAX_SIZE : 하나의 Oracle 프로세스당 최대로 사용할 수 있는 PGA 메모리 크기(Default 200MB)
- SMM_MAX_SIZE : Serial 오퍼레이션을 위한 최대 Work Area 크기이며, PGA_AGGREGATE_TARGET과 _PGA_MAX_SIZE에 의해 자동으로 계산된다.
- _SMM_PX_MAX_SIZE : Parallel 오퍼레이션을 위한 개별 Slave 프로세스들의 최대 Work Area 크기이며, PGA_AGGREGATE_TARGET과 _PGA_MAX_SIZE에 의해 자동으로 계산된다. 6 DOP(Degree Of Parallelism)보다 큰 경우에만 적용되며, 6 DOP 이하일 경우 모든 Slave Process는 _SMM_MAX_SIZE 이내로 적용된다.
- _SMM_MAX_SIZE와 _SMM_PX_MAX_SIZE의 계산 방식 : Oracle 11g R2 자체 TEST 결과 _SMM_MAX_SIZE의 경우 _PGA_MAX_SIZE 값의 50%가 할당됐고, _SMM_PX_MAX_SIZE는 PGA_AGGREGATE _TARGET 값의 50%가 할당됐다. Oracle 내부의 계산방식이라 확신할 수는 없으나 자체 Test 결과 일정한 비율은 확인되고 있어 파라미터 값에 대한 예측이 어느 정도 가능하다.
9.3 메모리 관리방식[편집]
9.3.1 AMM(Auto Memory Management)[편집]
[편집]
9.3.3 APMM[편집]
- 수동공유 메모리 관리
- 수동 PGA 메모리 관리
11 패스워드 파일[편집]
12 로그파일 위치 정보[편집]
-- alert,trace,incident,cdump 위치
SELECT *
FROM V$DIAG_INFO
-- WHERE NAME LIKE 'Diag%';12.3 net service 로그[편집]
13 데이터 딕셔너리 뷰[편집]
13.1 딕셔너리/뷰 정보 조회[편집]
14 스키마 오브젝트 와 데이터 저장방식[편집]
14.2 롤[편집]
14.2.1 롤 생성 삭제 관리[편집]
14.3 오라클 기본계정[편집]
14.3.1 SYS 와 SYSTEM 유저[편집]
14.3.2 SYSDBA 와 SYSOPER 시스템 권한[편집]
15 테이블[편집]
- row
- column
- PCTFREE
- PCTUSED
- 로우 마이그레이션
- 로우 체이닝
- 로우 마이그레이션/체이닝 확인
- 로우 저장 블럭
- ROWID
- 테이블 확인
- 테이블의 컬럼 정의 확인
- 제약 (constraints)
- 제약 확인
- 키 (PK/FK)
15.1 테이블 사이즈 계산[편집]
20 시노님[편집]
20.1 시노님_권한_관리_프로시져[편집]
21 디비링크[편집]
21.1 DBLINK 생성 수정[편집]
22 SQL 처리 과정[편집]
23 쿼리 처리 원리[편집]
24 변경 처리 원리[편집]
26 락[편집]
27 인스턴스 시작 과 종료[편집]
28 복구 처리 과정[편집]
29 오라클 NET SERVICE[편집]
30 리스너[편집]
31 tnsnames.ora[편집]
32 sqlnet.ora[편집]
33 오라클 JOB, SCHEDULES[편집]
- ORACLE JOB과 ORACLE SCHEDULER 가장 큰 차이점이라면 OS상의 crontab에 등재되는 shell프로그램도 ORACLE SCHEDULER에서 실행 가능
33.1 DBMS_JOB[편집]
- 특정 시간 및 간격으로 특정 작업을 수행
33.2 DBMS_SCHEDULER[편집]
- 매우 복잡하고 정교한 수준의 스케줄 작업 가능
33.2.1 프로그램(Program)[편집]
- 실행 가능한 프로그램(Program)을 말함
- DBMS_JOB 은 PL/SQL 블록, 저장 프로시저(Stored Procedure)만 가능
- DBMS_SCHEDULER는 외부 프로그램까지 사용 가능
- - ( PL/SQL 블록, 저장 프로시저(Stored Procedure), 실행 파일(Executable, Unix Shell, Windows 실행 파일) )
- - DBMS_SCHEDULER.CREATE_PROGRAM 프로시져를 통해 등록 가능하며 [ALL/DBA/USER]_SCHEDULER_PROGRAMS 뷰를 통해서 확인 가능
- 스케줄링에 의해서 실행 ( 프로그램 이름, 타입, Argument 갯수 등 )
33.2.2 스케줄(Schedule) - DBMS_SCHEDULER.CREATE_SCHEDULE[편집]
- 작업을 수행할 스케줄을 말함.
- 작업 시작 시간, 종료 시간, 간격 등을 지정.
- DBMS_JOB에 비해 유연함
EX ) "FREQ=YEARLY; BYMONTH=4; BYMONTHDAY=15; BYHOUR=9; BYMINUTE=0; BYSECOND=0" -- 매년 4월 15일 9시에 작업 수행
- DBMS_SCHEDULER.CREATE_SCHEDULE 프로시져로 등록 가능
- [ALL/DBA/USER]_SCHEDULER_SCHEDULES 뷰를 통해서 확인 가능
- 구문 설명
- USING PL/SQL Expression
예시) repeat_interval =>'sysdate+36/24'
- Using Calendar Expression
예시 1) repeat_interval => 'FREQ=HOURLY;INTERVAL=4' ( Indiates a repeat interval of every four hours )예시 2) repeat_interval => 'FREQ=YEARLY;BYMONTH=MAR,JUN,SEP,DEC;BYMONTH=15'- ( indicate as repeat interval of every year on Mar 15th, Jun 15th, Sep 15th and Dec 15th )
- USING PL/SQL Expression
notifications_active [인터벌 설정법]
Execute daily 'SYSDATE + 1'
Execute once per week 'SYSDATE + 7'
Execute hourly 'SYSDATE + 1/24'
Execute every 10 min. 'SYSDATE + 10/1440'
Execute every 30 sec. 'SYSDATE + 30/86400'
Do not re-execute NULL1) 10분간격으로 실행
SYSDATE + 1/24/62) 현재 시간으로 부터 다음 날 현재 시간에 실행 (매일)
SYSDATE + 1 -- 지금이 오후3시면 다음날 오후 3시 에 매일매일 실행됩니다.3) 매일 새벽 5시
TRUNC(SYSDATE) + 1 + 5 / 244) 매일 밤 10시
TRUNC(SYSDATE) + 20 / 2433.2.3 잡(Job) - DBMS_SCHEDULER.CREATE_JOB[편집]
- 주어진 프로그램과 스케줄에 따라 수행할 작업을 말함
- 명시적으로 생성된 프로그램(프로시져,함수등) 과 스케줄을 이용할 수도 있고, 작업을 생성하면 암묵적인 프로그램과 스케줄을 생성할 수도 있다.
- DBMS_SCHEDULER.CREATE_JOB 프로시져를 통해 등록 가능
- [ALL/DBA/USER]_SCHEDULER_JOBS 뷰를 통해 확인 가능
- 작업이 수행되면서 남는 로그 데이터는 [ALL/DBA/USER]_SCHEDULER_JOB_LOG 뷰나 [ALL/DBA/USER]_SCHEDULER_JOB_RUN_DETAILS 뷰를 통해 확인 가능
33.2.4 작업 클래스(Job Class)[편집]
- 작업의 공통 속성을 묶어서 만든 분류를 말한다.
- Resouce Consumer Group, Service, Logging Level, Log History 의 속성을 조합해서 하나의 클래스 생성 한다.
- Resource Consumer Group 은 DBMS_RESOURCE_MANGER 패키지를 통해서 생성,자원을 얼마나 사용 가능하게 할지를 지정
- Service는 작업이 특정 서비스에 대한 리소스 친화도(Resource Affinity)를 가지도록 지정
- Service는 RAC 에서 클러스터 내의 여러 노드를 묶은 논리적인 그룹
- Logging Level 은 작업 실행에 대한 로그 데이터의 레벨을 지정
- Log History 는 로그 데이터를 얼마나 저장할 지를 지정한다
- 같은 작업 클래스에 속하는 작업은 같은 속성을 공유하기 때문에 관리상의 편의점을 제공
- 하나의 JOB 은 하나의 JOB CLASS 에만 속함
33.2.5 윈도우(Window)[편집]
- 특정 리소스 플랜(Resoure Plan)을 적용하는 시간 단위를 의미
- 리소스 플랜은 오라클이 자원을 관리하는 단위로, 작업의 종류에 따라 CPU 등의 자원을 얼마나 부여할 지를 지정하는 역할
- - 윈도우를 지정하면 해당 윈도우 안에서 실행되는 작업은 윈도우 생성시 지정한 리소스 플랜을 사용하게 된다
33.2.6 체인(Chain )[편집]
- 프로그램의 집합을 의미
- 일련의 프로그램들을 순서대로 수행하고자 할 경우에 사용.
33.2.7 스케줄작업과 RAC Instance[편집]
- DBMS_JOB ==> 작업을 실행할 인스턴스 번호를 지정 // 한노드로 지정 시에 좀 더 편리
- DBMS_SCHEDULER => Instance_Stickness 라는 개념을 통해 좀 더 지능적으로 인스턴스를 할당
- INSTANCE_STICKSNESS = TRUE ( DBMS_SCHEDULER.SET_ATTRIBUTE ) 의미
- - 작업 수행 시 현재 가장 부하가 적은 인스턴스에 작업을 분배 한다.
- - 이후 작업 수행 시에는 가능한 최초에 지정된 인스턴스에서 작업을 수행하도록 한다.
- - 이 매커니즘을 일컬어 인스턴스 접착도라고 하며 리소스 친화도를 구현하는 방법
- - 최초에 지정된 인스턴스가 다운되거나, 부하가 심해서 작업을 수행할 수 없을 경우 다른 인스턴스에서 작업을 수행
- - 만일 INSTANCE_STICKNESS 속성 값이 FALSE 이면 오라클은 인스턴스 순서대로 작업을 수행한다.
- - DBMS_JOB 패키지를 이용해 작업을 수행하되 인스턴스 번호를 지정하지 않은 경우와 거의 같은 방식으로 작동한다.
33.3 오라클스케쥴러 등록을 위한 권한[편집]
GRANT CREATE ANY JOB TO 계정명;33.4 명령어[편집]
- DBMS_SCHEDULER.CREATE_PROGRAM
- - JOB이 스케쥴러에 맞게 돌면서 실제로 동작하는 프로그램(외부의 shell이나 SP, PLSQL_BLOCK 등) 을 등
- DBMS_SCHEDULER.CREATE_SCHEDULER
- - 주기적으로 돌아갈 스케쥴을 등록
- DBMS_SCHEDULER.CREATE_JOB
- - 수행할 작업을 등록한다.
33.5 사용 방법[편집]
33.5.1 동작할 프로그램 등록[편집]
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(
program_name => 'STATS_MAIN_BATCH_PROGRAM',
program_action => 'STATS_MAIN_BATCH',
program_type => 'STORED_PROCEDURE',
comments => 'Service desk stats main batch program',
enabled => TRUE);
END;33.5.1.1 매개변수가 있는 경우[편집]
BEGIN
/*-------------------------------------------------------------------------------------------------------------------
program_name: 프로그램 이름
program_action: 실제 액션이 일어나는 SP(미리 등록되어있어야 한다). 여기서 shell 프로그램등을 돌릴 수도 있다.
program_type: SP 라고 명시
number-of_arguments: 사용할 인수 개수
comments: 코멘트.부가설명
enabled: 사용가능 설정
argument_position: 몇번째 인수인지
argument_name: 인수이름
argument_type: 인수타입
argument_value: 인수값
--------------------------------------------------------------------------------------------------------------------*/
DBMS_SCHEDULER.CREATE_PROGRAM (
PROGRAM_NAME => 'STATS_MAIN_BATCH_PROGRAM'
,PROGRAM_TYPE => 'STORED_PROCEDURE'
,PROGRAM_ACTION => 'STATS_MAIN_BATCH'
,NUMBER_OF_ARGUMENTS => 1
,ENABLED => FALSE
,COMMENTS => 'SERVICE DESK STATS MAIN BATCH PROGRAM');
DBMS_SCHEDULER.DEFINE_PROGRAM_ARGUMENT (
PROGRAM_NAME => 'STATS_MAIN_BATCH_PROGRAM'
,ARGUMENT_POSITION => 1
,ARGUMENT_NAME => 'I_DT'
,ARGUMENT_TYPE => 'VARCHAR2'
,DEFAULT_VALUE => 'TO_CHAR(SYSDATE-1, ''YYYYMMDD'')'
);
DBMS_SCHEDULER.ENABLE(NAME => 'STATS_MAIN_BATCH_PROGRAM');
END;
33.5.2 스케줄 등록[편집]
/*-------------------------------------------------------------------------------------------------------------------
schedule_name : 스케쥴 이름
start_date: 스케쥴이 작동을 시작 할 시각. 입력한 시점부터 스케쥴러가 시작된다. AM 03시로 설정함
end_date: 스케쥴이 작동을 멈출 시간.
repeat_interval: 'FREQ=DAILY/DAILY/;INTERVAL=1; -- 매실행 ' 참고) 매 1회만 시/분/초 실행 BYHOUR/BYMINUTE/BYSECOND=0;
comments:
--------------------------------------------------------------------------------------------------------------------*/
BEGIN
SYS.DBMS_SCHEDULER.CREATE_SCHEDULE
(
schedule_name => 'RTIS_DBA.RTIS_TBL_DAILY_BKUP_SCHE'
,start_date => TO_TIMESTAMP_TZ('2019/05/02 20:50:58.423332 +09:00','yyyy/mm/dd hh24:mi:ss.ff tzh:tzm')
,repeat_interval => 'freq=daily;byhour=01;byminute=10;bysecond=0;'
,end_date => NULL
,comments => '매일 01:10 JOB 실행'
);
END;
/33.5.3 JOB 등록, 실제 수행 될 작업으로 스케쥴러와 프로그램 명시[편집]
BEGIN
/*-------------------------------------------------------------------------------------------------------------------
job_name: 작업이름
program_name: 구동 될 프로그램이름 명시. 위에서 등록한 프로그램이름을 적어준다.
schedule_name: 어떤 스케쥴러가 돌면서 이 작업을 수행 할 것인가. 위에 등록한 스케쥴러이름을 적어준다.
job_class: JOB을 Class 라는 단위로 그룹핑해서 관리한다. 많은 양의 스케쥴러 관리를 위해 추가 할 수 있다.
enabled: 사용가능 설정
comments: 코멘트.부가설명
--------------------------------------------------------------------------------------------------------------------*/
DBMS_SCHEDULER.CREATE_JOB (
job_name =>'STATS_MAIN_BATCH_JOB',
program_name =>'STATS_MAIN_BATCH_PROGRAM',
schedule_name =>'SCHEDULE_DAILY_AM_3_HOUR',
comments => 'Service desk stats main batch program',
--job_class =>'SCHEDULER_JOB_CLASS',
enabled =>TRUE);
END;33.5.4 스케줄러 삭제[편집]
execute dbms_scheduler.drop_job('FRG_BALANCE_HIST_UPDATE_JOB',false);
execute dbms_scheduler.drop_program('FRG_BALANCE_HIST_UPDATE_PRG',false);
execute dbms_scheduler.drop_schedule('SCHEDULE_30_MIN',false);- job먼저 지우고 program 삭제
- program 먼저 지우려고 하면 종속된 객체라면서 안지워짐.
BEGIN
DBMS_SCHEDULER.DROP_JOB(
JOB_NAME => 'STATS_MAIN_BATCH_JOB',
FORCE => FALSE);
END;
BEGIN
DBMS_SCHEDULER.DROP_PROGRAM(
PROGRAM_NAME => 'STATS_MAIN_BATCH_PROGRAM',
FORCE => FALSE);
END;33.5.5 스케줄러 등록/실행 정보 조회 뷰[편집]
SELECT * FROM DBA_SCHEDULER_JOBS; --등록된 job
SELECT * FROM DBA_SCHEDULER_JOB_ARGS; --job의 arguments
SELECT * FROM DBA_SCHEDULER_RUNNING_JOBS; --현재 running중인 job들의정보
SELECT * FROM DBA_SCHEDULER_JOB_LOG; --job의 log
SELECT * FROM DBA_SCHEDULER_JOB_RUN_DETAILS; --job의수행된정보및Error 정보
SELECT * FROM DBA_SCHEDULER_PROGRAMS; -- 등록된 Program
SELECT * FROM DBA_SCHEDULER_PROGRAM_ARGS; -- 프로그램의 매게변수
SELECT * FROM DBA_SCHEDULER_SCHEDULES; --등록된 스케쥴러33.5.6 참고사항[편집]
- JOB_CLASS 생성
# JOB_CLASS 설정
BEGIN
DBMS_SCHEDULER.CREATE_JOB_CLASS (
job_class_name =>'SCHEDULER_JOB_CLASS',
logging_level =>DBMS_SCHEDULER.LOGGING_FULL,
log_history =>1,
comments =>'SCHEDULER_JOB_CLASS');
END;- PROGRAM, SCHEDULE, JOB 세 개로 세분화하여 등록하는 형태.
- 하지만 세개 모두 등록하지 않고 CREATE_JOB 한 개만 등록하여 사용하는 방법도 있다.
- DBA_SCHEDULER_JOBS/USER_SCHEDULER_JOBS
select * from user_scheduler_jobs;- - CREATE_PROGRAM 에서 사용했던 program_type, program_action과 같이 job_type, job_action 컬럼 존재
- - CREATE_SCHEDULE에서 사용했던 start_date, end_date, repeat_interval이 존재.
- API
http://docs.oracle.com/cd/B19306_01/appdev.102/b14258/d_sched.htm
33.6 스케줄 등록 예시[편집]
33.6.1 샘플 테이블 생성[편집]
- 테이블 DBCAFE.CHECK_SCHEDULE 생성
CREATE TABLE CHECK_SCHEDULE (
INST_ID NUMBER, ACT_DATE DATE DEFAULT SYSDATE, ACT_DESC VARCHAR2(100)
) ;33.6.2 샘플 프로시져 생성[편집]
- 프로시져 DBCAFE.SP_SCHD_TEST 생성
CREATE OR REPLACE PROCEDURE SP_SCHD_TEST
IS V_SID NUMBER ; V_INST NUMBER ;
BEGIN
SELECT INSTANCE_NUMBER INTO V_INST FROM V$INSTANCE ;
INSERT INTO CHECK_SCHEDULE ( INST_ID, ACT_DATE, ACT_DESC ) VALUES ( V_INST, SYSDATE, 'DO SCHEDULEING') ;
END ;33.6.3 스케줄러 생성[편집]
- 스케줄러 SCHD_DBCAFE 생성
EXEC DBMS_SCHEDULER.CREATE_SCHEDULE(schedule_name=>'SCHD_DBCAFE',repeat_interval=>'FREQ=MINUTELY'); -- 매분마다 실행33.6.4 스케줄러 현재상태 확인[편집]
- DBA_SCHEDULER_SCHEDULES
SELECT SCHEDULE_NAME, REPEAT_INTERVAL
FROM DBA_SCHEDULER_SCHEDULES
WHERE OWNER ='DBCAFE'
AND SCHEDULE_NAME='SCHD_DBCAFE';33.6.5 프로그램 등록[편집]
EXEC DBMS_SCHEDULER.CREATE_PROGRAM(
PROGRAM_NAME=>'SP_SCHD_PROG_DBCAFE'
, PROGRAM_TYPE=>'STORED_PROCEDURE'
, PROGRAM_ACTION=>'DO_SCHEDULE_PROG');33.6.6 프로그램 Enable[편집]
EXEC DBMS_SCHEDULER.ENABLE('SP_SCHD_PROG_DBCAFE');33.6.7 프로그램 등록 확인[편집]
SELECT PROGRAM_NAME, PROGRAM_ACTION, ENABLED
FROM DBA_SCHEDULER_PROGRAMS
WHERE OWNER ='DBCAFE' AND PROGRAM_NAME='SP_SCHD_PROG_DBCAFE';33.6.8 잡 등록[편집]
EXEC DBMS_SCHEDULER.CREATE_JOB(
JOB_NAME => 'SCHD_JOB_DBCAFE'
, PROGRAM_NAME => 'SP_SCHD_PROG_DBCAFE'
, SCHEDULE_NAME=> 'SCHD_DBCAFE'
, AUTO_DROP => FALSE );33.6.10 스케줄러 실행 / 진행 사항 조회[편집]
-- 잡 등록/생성 확인
SELECT JOB_NAME, PROGRAM_NAME, SCHEDULE_NAME, ENABLED
FROM DBA_SCHEDULER_JOBS
WHERE OWNER ='DBCAFE'
AND JOB_NAME='SCHD_JOB_DBCAFE';
-- 작업 결과 확인
SELECT LOG_DATE, ACTUAL_START_DATE, JOB_NAME, STATUS
FROM DBA_SCHEDULER_JOB_RUN_DETAILS
WHERE JOB_NAME ='SCHD_JOB_DBCAFE';
-- 실제 결과 확인
SELECT * FROM CHECK_SCHEDULE ;
-- 등록된 job 확인
SELECT * FROM DBA_SCHEDULER_JOBS;
-- job의 arguments
SELECT * FROM DBA_SCHEDULER_JOB_ARGS;
--현재 running중인 job들의정보
SELECT * FROM DBA_SCHEDULER_RUNNING_JOBS;
--job의 log
SELECT * FROM DBA_SCHEDULER_JOB_LOG;
--job의수행된정보및Error 정보
SELECT * FROM DBA_SCHEDULER_JOB_RUN_DETAILS;
-- 등록된 Program
SELECT * FROM DBA_SCHEDULER_PROGRAMS;
-- 프로그램의 매개변수
SELECT * FROM DBA_SCHEDULER_PROGRAM_ARGS;
--등록된 스케쥴러
SELECT * FROM DBA_SCHEDULER_SCHEDULES;33.6.11 스케쥴 삭제[편집]
BEGIN
DBMS_SCHEDULER.DROP_JOB(
JOB_NAME => 'SCH_PROC_MSG_STATE',
FORCE => false);
END ;33.6.12 스케쥴 시작[편집]
EXECUTE DBMS_SCHEDULER.ENABLE('SCH_PROC_MSG_STATE');33.6.13 스케쥴 정지[편집]
EXECUTE DBMS_SCHEDULER.DISABLE('SCH_PROC_MSG_STATE');33.6.14 잡 관련 기타 프로시져[편집]
DBMS_JOB.submit : job 등록
DBMS_JOB.remove : 제거
DBMS_JOB.change : 변경
DBMS_JOB.next_date : job의 다음 수행시간 변경
DBMS_JOB.interval : job의 실행 cycle 지정
DBMS_JOB.what : job 수행 으로 등록된 object 를 변경
DBMS_JOB.run : job을 수동으로 실행33.6.15 [등록 예제2][편집]
DECLARE
X NUMBER;
BEGIN
SYS.DBMS_JOB.SUBMIT
( job => X
,what => '실행할 object'
,next_date => to_date('17-11-2007 09:00:00','dd/mm/yyyy hh24:mi:ss')
,interval => 'TRUNC(SYSDATE) + 1 + 9/24'
,no_parse => TRUE
);
SYS.DBMS_OUTPUT.PUT_LINE('Job Number is: ' || to_char(x)); -- 이부분은 job큐의 번호가 됩니다.
END;BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'SCH_PROC_MSG_STATE_TO_DAY',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN MEM_NPRO.TEST_PROC (TO_CHAR(SYSDATE , ''YYYYMMDD'')); END;',
start_date => TO_DATE('2011-12-14 17:30:00' , 'YYYY-MM-DD HH24:MI:SS'),
repeat_interval => 'FREQ=MINUTELY;INTERVAL=30',
end_date => NULL,
enabled => TRUE,
comments => 'HJ SCH_PROC_MSG_STATE_TO_DAY');
END;
33.6.16 RAC에서 2번 노드에서만 실행 예제[편집]
SYS.DBMS_SCHEDULER.SET_ATTRIBUTE
( name => 'RTIS_DBA.SCH_RTIS_SQL_GATHER'
,attribute => 'INSTANCE_ID'
,value => 2);