대문
DB CAFE
- DBA { Oracle DBA 명령어 > DBA 초급 과정 > DBA 고급 과정 }
- 튜닝 { 오라클 튜닝 목록 }
- 모델링 { 데이터 모델링 가이드 }
 디비 카페 - 데이터 전문가로 가는 길
디비 카페 - 데이터 전문가로 가는 길
DBCAFE (http:// [dbcafe.co.kr] :: sensing) visited
notifications_active 주제별 등록건수 / 총 1,022건
오라클: 515 건 / 파이썬: 73 건 / R : 14 건 / MySQL: 23 건 / Window: 12 건 / Linux: 12 건 / 주식: 40 건 / 머신러닝: 3 건 / 자동화: 5 건 / WEB: 1 건 / 도서: 5 건
1.1 DBA 오브젝트 관리(테이블/컬럼/인덱스/뷰/....)[편집]
- 테이블/컬럼 CRUD
- PK/FK 제약조건(CONSTRAINT)
- 인덱스
- 뷰(View)
- DBLINK
- 시퀀스(Sequence) 관리
- 트리거 CRUD
- 오라클 / Unix FAQ
1.2 SQL 명령어[편집]
- 데이터 추가/변경/병합
- 조인(join)
- 조인 LATERAL Inline Views (12C)
- CROSS APPLY Join
- OUTER APPLY Join
- 조인 LATERAL Inline Views (12C)
1.3 PL/SQL[편집]
- PL/SQL
1.3.1 함수/프로시져/트리거 오브젝트 추출 쿼리[편집]
1.3.2 사용자 관리[편집]
1.3.3 오라클 ASM 관리[편집]
1.3.4 오라클 RAC 관리[편집]
1.3.5 파라미터 관리[편집]
1.3.6 저장공간/용량 관리[편집]
2.1 DBA[편집]
- DB구축
- 오브젝트(테이블,인덱스,시노님,뷰..) 생성/관리
- 오라클 DDL 생성/감시
- 테이블 관리
- 테이블 변경 신청서 양식
- 인덱스 관리
- 인덱스 신청서 양식
- 시노님 관리
- 시노님 신청서 양식
- 권한 관리
- 권한 신청서 양식
- 시퀀스 관리
- 프로시져/함수 관리
- 개인정보 암호화
- 모니터링(락,세션,부하)
- 스케줄 관리
- 데이터 이관
- 오라클 데이터펌프(impdp/expdp) 작업절차
- Oracle 데이터펌프
- 백업/복구
- 산출물 작성
- 데이터베이스 설계서
- 데이터베이스 사용 설명서
- 테이블 변경 신청서
2.2 DB 모델링/DA[편집]
- 표준 모델링 작성 가이드
- ERD 사용법
2.3 표준화/META[편집]
2.3.1 메타웍스(MetaWork) 엔터티[편집]
2.4 DB 튜닝[편집]
- 퍼포먼스란 ?
- 서버 튜닝 대상
- SQL 튜닝 대상
- 오라클 힌트 전체
- 인덱스
- RANGE SCAN
- 클러스터링 팩터
- 엑세스 VS 필터 조건
- 인덱스 콤비네이션
- 인덱스 조인
- 인덱스 콤바인
- 인덱스 필터링
- 조인
- 서브쿼리
- 부분처리
- 중복데이터 반복 처리
- 실행 계획 분리
- PGA 튜닝
- 기타 응용 튜닝
- ORACLE_모니터링#하드파싱(leteral,리터럴) 찾기
- CPU를 과다사용 세션 조회
- 대량 Disk Read SQL 조회
- 오래수행되는 FULL SCAN TABLE
- CPU 과다사용 SQL 조회
- 현재 세션에서 10초이상 SQL
- 현재세션에서 PGA,UGA,CPU사용조회
- 병렬처리,5초이상 IO발생쿼리 모니터링
- ORACLE_모니터링#총 CPU Time 대비 SQL Parsing Time
- ORACLE_모니터링#롤백 세그먼트 경합 조회
- ORACLE_모니터링#Buffer Cache Hit Ratio
- ORACLE_모니터링#Library Cache Hit Ratio
- ORACLE_모니터링#Data Dictionary Cache Hit Ratio
- Log file sync 대기 조회
- 다이니믹 SQL 바인드 변수 처리
- SQL PLAN 사용법
- AWR 이용 튜닝
- ORACLE_모니터링#AWR을 이용한 literal SQL 추출 방법
- ORACLE_모니터링#AWR SQL ordered BY Elapsed Time
- ORACLE_모니터링#AWR SQL ordered BY CPU Time
- ORACLE_모니터링#AWR SQL ordered BY USER I/O Wait Time
- ORACLE_모니터링#AWR SQL ordered BY Gets
- ORACLE_모니터링#AWR SQL ordered BY READS
- ORACLE_모니터링#AWR SQL ordered BY Sharable Memory
- ORACLE_모니터링#AWR SQL ordered BY VERSION COUNT
- ASH 이용 튜닝
- 오라클 통계정보
- 오라클 히스토그램
- ORACLE 튜닝#엑세스 VS FILTER 비교
- ORACLE_모니터링#중복 인덱스 찾기
- 튜닝 사례
2.5 DB 진단[편집]
- 파라미터 진단
- 디스크 진단
- 네트워크 진단
- SQL 진단
- WAIT EVENT 진단
- ALERT LOG 진단
2.6 데이터 전환 이행[편집]
- 전환 전략 수립 #
- 데이터 이행 DDL 작업절차
- 데이터 전환 시나리오
2.7 데이터 품질(DQ) 진단[편집]
- 컬럼속성 불일치 분석현황
- 행정표준용어사용현황
- 행정표준코드사용
- 표준도메인준수
- 표준용어준수
- 미사용테이블현황
- 미사용컬럼현황
- 중복테이블현황
- 기본키미정의테이블현황
- 값진단_코드도메인
- DQ_도메인별_리포트_출력
- PDQ_05_C_진단대상_테이블컬럼정보
- P_DIAG_COLUMN_CODE
- P_DIAG_COLUMN_DTM
- P_DIAG_COLUMN_EAN
- P_DIAG_COLUMN_MONEY
- P_DIAG_COLUMN_NAME
- P_DIAG_COLUMN_NNULL
- P_DIAG_COLUMN_NUMBER
- P_DIAG_COLUMN_PATTERN
- P_DIAG_COLUMN_RATIO
- P_DIAG_COLUMN_YN
- P_DIAG_COLUMN_YYYYMM
- P_DIAG_COLUMN_YYYYMMDD
- P_DIAG_PROC_LOG
- P_TABLE_ROWS
- P_UNUSED_COLUMNS_CALL_NEW
- P_UNUSED_COLUMNS_NEW
- WAA_COL_TOT
- WDQ_HAN_CHK
- 표준코드_사전
- 한글값진단
2.8 데이터 웨어하우스/DW[편집]
2.8.1 DW 용어 및 설명[편집]
3.1 조인[편집]
- 조인 개념 이해
- 조인 튜닝
3.3 병렬 쿼리 튜닝[편집]
3.4 인덱스 튜닝[편집]
3.5 오라클 퍼포먼스 튜닝[편집]
3.8 튜닝 고려 사항[편집]
3.9 SQL 튜닝 노하우[편집]
3.10 뷰 머징(View Merging)[편집]
3.10.1 뷰 머징 이란?[편집]
emoji_objects 옵티마이저는 최적화 쿼리 수행을 위해 서브 쿼리블록을 풀어서 메인 쿼리와 결합(MERGE) 하려는 특성이 있음
arrow_downward SQL 원본
SELECT *
FROM ( SELECT * FROM EMP WHERE JOB = 'SALESMAN' ) A
, ( SELECT * FROM DEPT WHERE LOC = 'CHICAGO' ) B
WHERE A.DEPTNO = B.DEPTNO;- 서브쿼리나 인라인 뷰처럼 쿼리를 블록화 할 시, 가독성이 더 좋기 때문에 습관적으로 사용
arrow_downward View Merging 으로 오라클 내부에서 아래 형태로 SQL 변환
SELECT *
FROM EMP A
, DEPT B
WHERE A.DEPTNO = B.DEPTNO
AND A.JOB = 'SALESMAN'
AND B.LOC = 'CHICAGO';- View Merging 이유 : 옵티마이저가 더 다양한 액세스 경로를 조사대상으로 삼을 수 있음
3.10.2 View Merging 제어 힌트[편집]
- /*+ MERGE */
- /*+ NO_MERGE */
3.10.3 단순 뷰(Simple View) Merging[편집]
- 가능한 조건
- 조건절과 조인문만을 포함하는 단순 뷰(Simple View)일 경우, no_merge 힌트를 사용하지 않는 한 언제든 Merging 발생
- group by, distinct 연산을 포함하는 복합뷰(Complex View)는 파라미터 설정 또는 힌트 사용에 의해서만 뷰 Merging 가능
- 불가능한 조건
- 집합 연산자, connect by, rownum 등을 포함한 복합 뷰(Non-mergeable Views)는 뷰 Merging 불가능
-- Simple View 예제
create or replace view emp_salesman as
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where job = 'SALESMAN';3.10.3.1 Simple View 뷰 No Merging 최적화[편집]
SQL> select /*+ no_merge(e) */ e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp_salesman e, dept d
3 where d.deptno = e.deptno
4 and e.sal >= 1500 ;
EMPNO ENAME JOB MGR SAL DNAME
---------- ---------- --------- ---------- ---------- --------------
7844 TURNER SALESMAN 7698 1500 SALES
7499 ALLEN SALESMAN 7698 1600 SALES
Execution Plan
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 156 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 156 | 4 (0)| 00:00:01 |
| 3 | VIEW | EMP_SALESMAN | 2 | 130 | 2 (0)| 00:00:01 |
|* 4 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 7 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("JOB"='SALESMAN')
5 - access("SAL">=1500)
6 - access("D"."DEPTNO"="E"."DEPTNO")3.10.3.2 Simple View 뷰 Merging 최적화[편집]
SQL> select /*+ merge(e) */ e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp_salesman e, dept d
3 where d.deptno = e.deptno
4 and e.sal >= 1500 ;
Execution Plan
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 84 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 84 | 4 (0)| 00:00:01 |
|* 3 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("JOB"='SALESMAN')
4 - access("SAL">=1500)
5 - access("D"."DEPTNO"="DEPTNO")arrow_downward 일반 조인문
SQL> select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp e, dept d
3 where d.deptno = e.deptno
4 and e.job = 'SALESMAN'
5 and e.sal >= 1500;
Execution Plan
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 84 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 84 | 4 (0)| 00:00:01 |
|* 3 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("E"."JOB"='SALESMAN')
4 - access("E"."SAL">=1500)
5 - access("D"."DEPTNO"="E"."DEPTNO")* 단순 뷰를 Merging 할 경우, 파라미터 or 힌트 설정을 하지 않을 경우 일반 조인문과 똑같은 형태로 변환 후 처리
3.10.4 복합 뷰(Complex View) Merging[편집]
- group by절 , select-list에 distinct연산자 포함하는 복합 뷰
- _complex_view_merging 파라미터 값이 true로 설정할 때만 Merging 발생
- 10g에서는 복합 뷰 Merging을 일단 시도하지만, 원본 쿼리에 대해서도 비용을 같이 계산해 Merging했을 때의 비용이 더 낮을 때만 그것을 채택 (비용기반 쿼리 변환)
- 10g 이전 _complex_view_merging 파라미터 기본 값 (8i : false, 9i : true)
- complex_view_merging 파라미터를 true로 설정해도 Merging 될 수 없는 복합 뷰
- 집합(set)연산자( union, union all, intersect, minus )
- connect by절
- ROWNUM pseudo 컬럼
- select-list에 집계 함수(avg, count, max, min, sum)사용 : group by 없이 전체를 집계하는 경우를 말함
- 분석 함수
- 복합뷰를 포함한 쿼리 (뷰 머징 발생 시)
SQL> select d.dname, avg_sal_dept
2 from dept d
3 ,(select deptno, avg(sal) avg_sal_dept from emp group by deptno) e
4 where d.deptno = e.deptno
5 and d.loc='CHICAGO';
DNAME AVG_SAL_DEPT
-------------- ------------
SALES 1566.66667
Execution Plan
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 81 | 5 (20)| 00:00:01 |
| 1 | HASH GROUP BY | | 3 | 81 | 5 (20)| 00:00:01 |
| 2 | NESTED LOOPS | | | | | |
| 3 | NESTED LOOPS | | 5 | 135 | 4 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | DEPT | 1 | 20 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_IDX_DEPTNO | 5 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 35 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("D"."LOC"='CHICAGO')
5 - access("D"."DEPTNO"="DEPTNO")
arrow_downward 복합뷰를 일반 조인절로 변경한 쿼리
SQL> select d.dname,avg(sal)
2 from dept d,emp e
3 where d.deptno=e.deptno
4 and d.loc='CHICAGO'
5 group by d.rowid,d.dname;
DNAME AVG(SAL)
-------------- ----------
SALES 1566.66667
Execution Plan
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 5 (20)| 00:00:01 |
| 1 | HASH GROUP BY | | 1 | 27 | 5 (20)| 00:00:01 |
| 2 | NESTED LOOPS | | | | | |
| 3 | NESTED LOOPS | | 5 | 135 | 4 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | DEPT | 1 | 20 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_IDX_DEPTNO | 5 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 35 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("D"."LOC"='CHICAGO')
5 - access("D"."DEPTNO"="E"."DEPTNO")
- 뷰머징이 발생 할 경우
- dept테이블에서 loc컬럼이 'CHICAGO'인 데이터를 먼저 필터링하고 조인, 조인대상 집합만 group by 실행
- 뷰머징이 발생되지 않을 경우
- emp 테이블의 모든 테이블을 group by 한 후 필터링하게 되면서 불필요한 레코드 엑세스 발생
3.10.5 비용기반 쿼리 변환의 필요성[편집]
9i : 복합 뷰를 무조건 머징 => 대부분 더 나은 성능 제공하지만 복합뷰 머징 시 그렇지 못할 때가 많음
- no_merge 힌트 등 뷰안에 rownum 을 넣어주는 튜닝 기법 활용
10g 이후 비용기반 쿼리 변환 방식으로 처리
- _optimizer_cost_based_transformation 파라미터 사용 → 설정값 5가지 (on, off, exhaustive, linear, iteraive)
on : 적절한 것을 스스로 선택 exhaustive : cost가 가장 저렴한 것 선택 linear : 순차적 비교 후 선택 literation : 변환이 수행 유무에 따른 cost를 비교하기 위한 경우의 수로 listeration 정의
opt_param 힌트 이용으로 쿼리 레벨에서 파라미터 변경가능 (10gR2부터 제공)
3.10.6 Merging 되지 않은 뷰의 처리방식[편집]
- 1단계 : 뷰머징 시행 시 오히려 비용이 증가된다고 판단(10g이후) 되거나, 부정확한 결과 집합 가능성이 있을 시 뷰머징 포기
- 2단계 : 뷰머징이 포기 할 경우 조건절 Pushing 시도
- 3단계 : 뷰 쿼리 블록을 개별적으로 최적화된 개별 플랜을 전체 실행계획에 반영 (즉, 뷰 쿼리 수행 결과를 엑세스 쿼리에 전달)
SQL> select /*+ leading(e) use_nl(d) */ *
2 from dept d
3 ,(select /*+ NO_MERGE */ * from emp) e
4 where e.deptno = d.deptno;
14 개의 행이 선택되었습니다.
Execution Plan
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1498 | 17 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 14 | 1498 | 17 (0)| 00:00:01 |
| 3 | VIEW | | 14 | 1218 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 20 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("E"."DEPTNO"="D"."DEPTNO")
※ 실행계획의 "VIEW" 로 표시된 오퍼레이션 단계가 추가 되었을 시, 실제로 다음 단계로 넘어가기 전 중간집합을 생성하는 것은 아님3.11 오라클 라이브러리 캐시(Library Cache) 튜닝 방법[편집]
3.11.1 SQL 작성 과 파싱[편집]
- SQL문을 실행하면, 데이터베이스는 아스키 값으로 계산
- :대문자, 띄어쓰기, 주석에 따라 아스키 값이 다르므로 표현이 달라지면 다른 SQL문으로 인식
- 같은 결과를 얻지만 표현이 다른 SQL문은 실행할때마다 library Cache에서 하드파싱 됨.
- 하드파싱은 SQL문의 검색과 공간확보를 위해 Shared Pool Latch 와 Library Cache Latch를 필요로 함.
- : 잦은 하드파싱은 리소스를 과도하게 사용하고 래치를 오래 점유하므로 SQL문의 수행에 지연이 발생
- 하드파싱을 피하기 위해서는 SQL문을 재사용하는 소프트 파싱이 필요.
- - SQL문 작성시, 대문자, 띄어쓰기, 주석에 대한 원칙을 세워야 함.
- - 바인드 변수를 사용하면 변수에 들어가는 값에 관계없이 파싱 함.
- - 파싱이 끝나면 바인드값( :value )을 대입하게 되는데, 적용되는 값에 상관없이 SQL을 공유할 수 있게 되는 것.
- SQL을 수행하게되면 Library Cache에서 해당 래치를 획득하고 수행하려는 SQL 실행정보(LCO:Library Cache Object)가 있는지 검색.
- - SQL이 있으면 LCO의 생성과정을 거치지 않고 바로 실행할 수 있음. 이것을 소프트파싱이라고 함.
- 그런데, SQL이 Library Cache에 존재하지 않는 새로운 SQL이라면 LCO를 만들어 실행정보를 저장 함.
- - Shared Pool 래치를 획득하여 저장할 공간을 확보 해야 함.
- - 공간이 마련되면 SQL의 LCO가 생성되고, 여기에 SQL문과 실행계획 등의 정보를 저장.
- - 이렇게 만들어진 LCO를 통해 SQL이 수행.
- 이와 같이 SQL문이 Library Cache 내에 존재하지 않아 LCO를 만들고, 여기에 실행정보를 저장하는 과정을 하드 파싱이라고 함.
- - 하드파싱과 소프트파싱은 Library Cache 내의 SQL 존재유무에 따라서 구별.
- 최초로 수행되는 SQL은 하드파싱을 피할 순 없음. 그러나 두번째 수행부터는 소프트파싱을 하는게 보다 빠르고 적은 리소스를 사용하니 보다 효율적 임.
3.11.2 Child LCO (Library Cache Objects) 생성[편집]
- SQL이 parsing이 되면, LCO를 만듬.
- - LCO도 같은 SQL이라고 해서 하나로 같이 쓰는것이 아니라, 유저가 다르고, 환경이 달라도 따로 LCO를 만들어서 관리.
- - 조건이 다르면 전부 다르게 LCO를 만들게 됨.
- child LCO가 다르게 만들어지는 이유는 V$SQL_SHARED_CURSOR란 뷰를 보면 확인이 가능.
- 오라클 프로시저나 테이블과 같은 객체에 대해서는 스키마명을 항상 같이 저장하기 때문에 유일성이 보장 됨.
- 하지만, SQL 문장의 경우에는 SQL 텍스트 자체가 이름으로 사용되기 때문에 유일성이 보장되지 않음.
- 따라서 오라클 SQL 텍스트를 이름으로 갖는 부모 LCO를 생성하고 실제 SQL 커서에 대한 정보는 자식 LCO에 저장.
- 가령 두 개의 다른 스키마 A, B에서 텍스트는 동일하지만, 실제로 참조하는 객체는 다른 SQL문장을 수행한 경우, #: 오라클은 SQL 텍스트에 해당하는 부모 LCO와 스키마 A가 수행한 SQL 커서에 해당하는 자식 LCO,
- 스키마 B가 수행한 SQL 커서에 해당하는 자식 LCO, 총 세개의 LCO를 생성 함.
3.11.3 LATCH: library cache[편집]
- latch: library cache 대기 이벤트는 libarary cache 래치를 획득하는 과정에서 경합이 발생하여 나타나는 대기 이벤트.
- Shared Pool 래치가 프리 청크(Free chunk)를 찾기 위해 프리리스트(Free List)를 스캔하고, 적절한 청크를 할당하는 작업을 보호한다면, library cache 래치는 SQL을 수행하기 위해 libarary cache 메모리 영역을 탐색하고 관리하는 모든 작업을 보호.
- 이 때, libarary cache 래치는 CPU count 보다 큰 소수(Prime Number) 중 가장 작은 수만큼 자식 래치(child latch)를 가집니다.
3.11.4 Wait Time[편집]
- 이벤트의 대기시간을 기하급수적으로 증가한다.
- Parameter
P1(프로세스가 대기하고 있는 래치의 메모리 주소), P2(래치 번호), P3(래치를 획득하기 위해 프로세스가 시도한 횟수)
3.11.4.1 일반적인 문제상황 및 대처방안[편집]
3.11.4.1.1 원인: 파싱이 과다한 경우[편집]
3.11.4.1.1.1 진단방법: 파싱이 과다한 경우[편집]
- latch: library cache 대기가 높은 시점의 파싱에 소요된 시간(parse time elapsed)
- 발생한 파싱 횟수(parse count(total), parse count(hard), SQL 수행 횟수(execute count)를 확인)
3.11.4.1.1.2 개선방법: 파싱이 과다한 경우[편집]
- 바인드 변수 사용, Web Application Server의 경우, Statement Cache 기능 사용
- 애플리케이션 수정, Static SQL을 사용
- session_cached_cursors 파라미터의 조정
3.11.4.1.2 원인: 버전 카운트(Version count)가 높은 경우[편집]
3.11.4.1.2.1 진단방법: 버전 카운트(Version count)가 높은 경우[편집]
- V$SQLAREA 뷰에서 latch: libarary cache의 보유 시간이 긴 SQL의 VERSION_COUNT 칼럼 값을 확인
3.11.4.1.3 원인: SGA(System Global Area) 영역의 페이지 아웃(Page out)이 발생하는 경우[편집]
3.11.4.1.3.1 진단 방법: latch: library cache 대기가 높은 시점 O/S에서 스왑(Swap) 발생[편집]
3.11.4.1.3.2 개선 방법[편집]
- Memory 과다 사용 프로세스 검출
- HP-UX, AIX: LOCK_SGA 파라미터값을 TRUE 값으로 변경(DEFAULT = FALSE)
- SunOS: _USE_ISM 파라미터 값이 TRUE 인지 확인(DEFAULT = TRUE)
Scott 유저 조회 SQL: select * from emp where empno = 1;
Mary 유저 조회 SQL: select * from emp where empno = 1;
John 유저 조회 SQL: select * from emp where empno = 1;- 위의 세 SQL 문장은 Text가 완전히 동일하므로 SQL 해시 값이 동일함.
- 따라서 동일한 해시 체인(Hash Chain)의 동일한 핸들에 할당됩니다.
- 하지만 emp 테이블이 모두 스키마가 다른 테이블(scott.emp , mary.emp , john.emp)이므로 실제로는 다른 SQL문장 임.
- 이 경우 오라클은 Text에 해당하는 부모 LCO를 두고 그 밑에 세 개의 자식 LCO를 만들어 개별 SQL 정보를 관리합니다.
- - 세 개의 자식 LCO는 실제로는 익명 리스트(Anonymous List)라고 하는 별도의 리스트에 저장됩니다.
- - 세 개의 자식 LCO를 가지므로 V$SQLAREA 뷰의 VERSION_COUNT(버전 카운트) 칼럼 값이 자식 LCO의 개수와 같은 3의 값을 가지게 됩니다.
- 버전 카운트가 높다는 것은 자식 LCO 탐색으로 인해 library cache를 탐색하는 시간이 그만큼 증가한다는 것이며, 이로 인해 library cache 래치 경합이 증가할 수 있다는 것을 의미합니다.
- 만일 특정 SQL 문장에서 library cache 래치 경합이 많이 발생한다면 해당 SQL의 버전 카운트 값을 확인해 볼 필요가 있습니다.
- 오라클의 버그로 인해 버전 카운트가 불필요하게 높아지는 경우가 있기 때문.
3.11.4.1.4 원인: 비효율적인 SQL문장 사용[편집]
3.11.4.1.4.1 진단 방법[편집]
- cache buffers chains 래치 대기가 발생하는 시기에 V$SQLAREA 뷰를 통하여 SQL을 확인, TRACE를 통하여 과다한 처리범위를 발생시키지 않는지에 대한 여부를 확인
3.11.4.1.4.2 개선 방법: SQL문장 튜닝[편집]
3.11.4.1.5 원인: 핫 블록(HOT Block)에 의한 문제[편집]
3.11.4.1.5.1 진단 방법[편집]
- V$LATCH_CHILDREN 뷰에서 cache buffers chains 래치에 해당하는 특정 자식 래치의 CHILD#과 GETS, SLEEPS 값이 높은지 확인
- V$SESSION_WAIT 뷰에서 래치의 주소를 얻어 과다하게 중복된 주소가 있는지 확인
3.11.4.1.5.2 개선 방법: PCTFREE를 높게 주거나 작은 크기의 블록을 사용[편집]
- 파티셔닝 적용, 해당 블록의 로우들에 대해서만 삭제 후, 재삽입 작업 수행
LATCH: cache buffers lru chain
latch: cache buffers lru chain은 cache buffers lru chain 래치를 획득하는 과정에서 경합이 발생하여 나타나는 이벤트입니다. Working Set(lru + lruw)을 탐색하거나 변경하려는 프로세스는 항상 해당 Working Set을 관리하는 cache buffers lru chain 래치를 획득해야 하는데, 이 때 경합이 발생하면 latch: cache buffers lru chain 이벤트를 대기하게 됩니다.
- Wait Time
이벤트의 대기시간은 기하급수적으로 증가한다.
- Parameter
P1(프로세스가 대기하고 있는 래치의 메모리 주소), P2(래치번호), P3(래치를 획득하기 위해 프로세스가 시도한 횟수)
- 일반적인 문제상황 및 대처방안
- 원인: 비효율적인 SQL문장 사용
- 진단 방법: cache buffers lru chain 래치 대기가 발생하는 시기에 V$SQLAREA 뷰를 통하여 SQL을 확인, TRACE를 통하여 과다한 처리범위를 발생시키지 않는지에 대한 여부를 확인
- 개선 방법: SQL문장 튜닝
- 원인: 버퍼 캐시 크기가 너무 작은 경우
- 진단 방법: 버퍼 캐시의 히트율을 확인하기 위해서는 V$SYSSTAT, V$SESSTAT을 확인하고, 버퍼 캐시 영역을 분석하기 위해서 V$BUFFER_POOL, V$BUFFER_POOL_STATISTICS를 확인
- 개선 방법: 버퍼 캐시의 크기를 충분히 크게 한다.
- 원인: 체크 포인트 주기가 지나치게 짧은 경우
- 진단 방법: 버퍼 캐시의 히트율을 확인하고, FAST_START_MTTR_TARGET 또는 LOG_CHECKPOINT_TIMEOUT 파라미터를 통해 체크 포인트 주기를 확인
- 개선 방법: FAST_START_MTTR_TARGET 파라미터를 조정하여, 체크 포인트 주기를 합리ㅏ적으로 지정
cache buffers chains 래치와 cache buffers lru chain 래치 경합간의 차이
cache buffers chains 래치와 cache buffers lru chain 래치 경합간의 차이점에 대해서 이해라 필요가 있습니다. 만일 동일 테이블이나 인덱스를 여러 세션이 동시에 스캔하는 경우라면, cache buffers chains 래치 경합이 발생할 확률이 높습니다. 동일 체인에 대한 경합이 발생하기 때문입니다. 하지만, 다른 테이블이나 인덱스들을 여러 세션이 동시에 스캔하는 경우라면 cache buffers lru chain 래치 경합이 발생할 확률이 높습니다. 여러 세션들이 모두 다른 블록들을 메모리에 올리는 과정에서 프리 버퍼를 확보하기 위한 요청이 많아지고 이로 인해 Working Set에 대한 경합이 발생할 확률이 높아집니다. 특히 데이터의 변경이 빈번해서 더티 버퍼의 개수가 많고 이로 인해 DBWR가 체크 포인트를 위해 lruw 리스트를 탐색하는 횟수가 잦다면 cache buffers lru chain 래치의 경합은 더욱 심해집니다. cache buffers lru chain 래치 경합의 또다른 중요한 특징은 물리적 I/O를 수반한다는 것입니다. 비효율적인 인덱스 스캔에 의한 문제라면 db file sequential read 대기와 lru chain 래치 경합이 함께 발생하게 되고, 불필요한 풀테이블스캔이 많다면 db file scattered read 대기와 lru chain 래치 경합이 함께 발생하게 됩니다.
실제로는 cache buffers chains 래치 경합과 cache buffers lru chain 래치 경합이 같이 발생하는 경우가 많은데, 복잡한 애플리케이션들에서는 위에서 언급한 패턴들이 복합적으로 사용되기 때문입니다.
버퍼 캐시 크기 증가 여부 판단
select to_char((sum(decode(name, 'consistent gets', value, 0)) +
sum(decode(name, 'db block gets', value, 0)) -
sum(decode(name, 'physical reads', value, 0)) -
sum(decode(name, 'physical reads direct', value, 0))) /
(sum(decode(name, 'consistent gets', value, 0)) +
sum(decode(name, 'db block gets', value, 0))) *
100, '999.99') || ' %' "Buffer Cache Hit Ratio"
from v$sysstat; 다수의 비효율적인 SQL로 인한 프리버퍼를 과도하게 요청하는 경우 버퍼 캐시 히트율을 떨어뜨리는 주요 원인이 됩니다. 그리고 버퍼 캐시의 크기가 지나치게 작을 경우 또한 히트율을 떨어뜨리는 주요 원인입니다. 버퍼 캐시 크기 증가를 고려하기 위해 버퍼 캐시 히트율을 확인해 볼 필요가 있습니다. 또한 free buffer waits, buffer deadlock, buffer busy waits 이벤트 다수 발생 시에도 버퍼 캐시 크기 증가를 고려해 볼 필요가 있습니다.
library cache pin
library cache pin 이벤트 대기는 Library Cache Object의 실행정보를 바꾸거나 참조하는 과정에서 경합이 발생할 때 관찰됩니다. 가령 특정 SQL에 대해 최초로 하드파싱을 수행하는 세션은 해당 Library Cache Object에 대해 library cache pin을 Exclusive 모드로 획득합니다. 하드파싱이 이루어지는 동안 같은 SQL을 수행하고자 하는 세션들을 library cache pin을 Shared 모드로 획득하기 위해 대기해야 합니다. 이때 library cache lock 이벤트를 대기합니다.
- Wait Time
PMON 프로세스는 1초까지 대기하며, 다른 프로세스들은 3초까지 대기합니다. 해당 대기시간 후에도 핀을 획득하지 못할 경우 반복적으로 대기합니다.
- Parameter
참고) library cache pin 대기 이벤트는 대기 파라미터를 사용하지 않습니다.
P1(핀(pin) 대기와 관련된 오브젝트의 메모리 주소), P2(핀(pin)의 메모리 주소), P3(모드(mode)와 네임스페이스(namespace))
- Common Causes and Actions
- 원인: 현재 많이 사용되는 오브젝트에 대한 DDL 명령을 수행
- 진단 방법: library cache lock/pin 경합 중 x$kglk, x$kglpn, x$kglob, v$session을 통하여 Holder Session 확인, library cache lock/pin 경합 종료 후 사후 분석 시 DBA_HIST_ACTIVE_SESS_HISTORY 뷰를 통하여 Blocking Session을 확인
- 개선 방법: 업무시간 중 과도한 오브젝트의 변경을 제한
library cache lock과 library cache pin의 상관관계
select a.sid, kglpnmod "Mode", kglpnreq "Req" from x$kglpn p, v$session s where p.kglpnuse = s.saddr and kglpnhdl='$P1RAW';
library cache pin 이벤트의 P1=handle address, P2=lock address, P3=mode*100+namespace로 어떤 객체에 대해 어떤 모드로 락을 획득하는 과정에서 경합이 발생했는지 파악할 수 있습니다.
library cache pin은 library cache lock을 획득한 후, library cache 객체에 대해 추가작업이 필요할 "때 획득하게 됩니다. 가령 특정 프로시저나 SQL 문장을 수행하고자 하는 프로세서는 library cache lock을 Shared 모드로 획득한 후에 library cache pin을 Shared 모드로 획득해야 하며, 프로시저를 컴파일(alter procedure ... compile ...)하는 경우에는 library cache pin을 Exclusive하게 획득해야 합니다. 핀(pin)이라는 용어의 의미는 LCO에 핀을 꽂는다는 것으로, 핀이 꽂혀있는 동안 LCO의 값이 변동되지 않도록 보장받는 역할을 합니다. 한 가지 기억할 사실은 하드파싱이 발생하는 경우, 하드파싱이 이루어지는 동안 해당 SQL 커서에 대해 library cache pin을 Exclusive하게 획득한다는 것입니다. 해당 이벤트가 발생할 경우, 위의 SQL을 수행하여 핀을 점유하고 있는 세션 및 모드를 확인할 수 있습니다.
업무시간 중 DDL의 수행을 피하라
library cache lock 대기에 의한 성능저하 현상은 대부분 부적절한 DDL(create, alter, flush 등)에 의해 발생합니다. 따라서 트랜잭션이 왕성한 시스템에 대해서 DDL을 수행할 때는 이 내용을 충분히 수행해야 합니다. 간혹 하드 파싱이 많은 시스템에서 Shared Pool 메모리 고갈을 피하기 위해(ORA-4031 에러를 피하기 위해) flush를 수행하는 경우가 있으나 시스템에 악영향을 주는 경우가 많습니다. 하드 파싱도 나쁘지만, 하드 파싱이 발생하는 도중에 DDL을 수행하는 것은 피해야 합니다.
LATCH: shared pool(bind mismatch)
Shared Pool 래치는 Shared Pool의 기본 메모리 구조인 힙을 보호하는 역할을 합니다. 프리 청크를 찾기 위해 프리 리스트를 탐색하고, 적절한 청크를 할당하고, 필요한 경우 프리 청크를 분할(Split)하는 일련의 작업들은 모두 Shared Pool 래치를 획득한 후에만 가능합니다. Shared Pool 래치를 획득하는 과정에서 경합이 발생하면 latch: shared pool 이벤트를 대기합니다.
- Wait Time
이벤트의 대기시간은 기하급수적으로 증가한다.
- Parameter
P1(프로세스가 대기하고 있는 래치의 메모리 주소), P2(래치번호), P3(래치를 획득하기 위해 프로세스가 시도한 횟수)
- 일반적인 문제상황 및 대처방안
- 원인: 동시에 여러 세션이 청크를 할당 받아야 하는 경우
Shared Pool 단편화가 일어날 경우
Literal SQL로 인한 Hard Parsing의 과다 수행
- 진단 방법: Hard Parsing 추이를 확인하기 위하여 V$SYSSTAT 뷰를 통하여 parse count(hard),
parse time cpu, parse time elapsed 지표 값 확인
Hard Parsing이 높게 나타난 세션에 수행된 SQL의 Literal SQL 여부 확인
- 개선 방법: 바인드 변수 사용
_KGHDSIDX_COUNT 히든 파라미터를 이용하여 서브풀 생성
Shared Pool의 크기 감소 후 dbms_shared_pool 패키지 사용
Cursor Sharing 기법 사용
Prepared Statement의 사용을 통해 JDBC PKG 내의 Literal SQL을 제거
서브풀의 사용
오라클 9i 이상부터는 shared Pool을 여러 개의 서브풀로 최대 7개가지 나누어서 관리할 수 있습니다. _KGHDSIDX_COUNT 히든 파라미터를 이용하면 서브풀의 개수를 관리할 수 있습니다. 오라클은 CPU 개수가 4 이상이고, Shared Pool의 크기가 250M 이상인 경우 _KGHDSIDX_COUNT의 값만큼 서브풀을 생성해서 Shared Pool을 관리합니다. 서브풀은 그 자체가 독립적인 Shared Pool로 관리되며 독자적인 프리리스트(Freelist), lru 리스트, Shared Pool 래치를 가집니다. 따라서 shared Pool의 크기가 큰 경우에는 서브풀로 쪼개서 관리함으로써 Shared Pool 래치 경합을 줄일 수 있습니다.
Shared Pool 크기 감소
하드파싱에 의해 Shared Pool 래치 경합이 발생하는 경우 또 다른 해결책은 Shared Pool의 크기를 줄이는 것입니다. Shared Pool의 크기가 줄어든 만큼 프리리스트에 딸린 프리 청크들의 개수도 감소하고 따라서 프리리스트 탐색에 소요되는 시간이 줄어들기 때문입니다. 하지만 이 경우 ORA-4031 에러가 발생할 확률이 높아지며 Shared Pool에 상주할 수 있는 객체의 수가 줄어들어서 부가적인 하드파싱이 유발될 수 있다는 단점이 있습니다. 이 단점을 해소하기 위해서 dbms_shared_pool.keep 프로시저를 이용해서 자주 사용되는 SQL 커서나 패키지, 프로시저 등을 shared Pool에 영구 상주시키는 방법을 사용할 수 있습니다. dbms_shared_pool.keep을 이용해 지정된 객체들은 Shared Pool에 영구적으로 상주하게 되며, alter system flush shared_pool 명령으로도 내려가지 않습니다. 요약하면, Shared Pool의 크기를 줄이고 동시에 dbms_shared_pool 패키지를 이용해 자주 사용되는 객체를 메모리에 상주시키는 것이 또하나의 방법이 됩니다.
Cursor Sharing 사용
Cursor Sharing 기법을 사용합니다. Cursor Sharing이란 상수(Literal)을 사용한 SQL 문장을 자동으로 바인드 변수를 사용하게끔 치환해서 커서가 공유되도록 해주는 기능을 말합니다. Curosr Sharing 기능은 기존의 Literal SQL을 바인드변수로 변환할 간적 여유가 없는 경우에만 사용하는 것이 바람직합니다.
kksfbc child completion
SQL Cursor 객체는 Parent/Child의 관계로 이루어져 있습니다. Parent Cursor 객체가 여러개의 Child Cursor 객체를 거느립니다. Server Process가 현재 생성(Built) 중인 Child Cursor를 사용하려면 Cursor 생성이 완료될 때까지 기다려야 합니다. 이때 보고되는 이벤트가 kksfbc child completion 이벤트입니다.
- 과도한 Hard Parse는 kksfbc child completion 대기 이벤트의 가장 중요한 원인
1. Hard Parse가 많은 경우(Parse count 통계값 및 V$SQLAREA.VERSION_COUNT 값 참조)
2. Parse failure가 많은 경우
3. 병렬 실행이 발생하는 경우에도 Child Cursor를 공유하는 과정에서 대기가 발생하는 경우
- kksfbc child completion 대기 이벤트 해소 방법(Hard Parse의 최소화)
1. Dynamic SQL을 Static SQL로 변환한다.
2. Literal SQL 사용을 최소화하고 Bind Variable을 사용한다.
3. Bind Mismatch에 의한 Hard Parse가 발생하는지 확인한다.
CURSOR: pin s wait on x
오라클 10g 이후부터, Shared Cursor Operation에 대해 기본적으로 Mutex가 동기화 객체로 사용되면서 나타나는 Wait Event입니다. 일종의 library cache pin 이벤트 발생과 성격이 비슷합니다.
- Shared Cursor Operation이란?
- library cache latches, library cache pin latches, library cache pinsd를 의미합니다.
- 뮤텍스(Mutual exclusion)란?
- 다수의 프로세스가 동일한 리소스를 공유할 때 동시 사용을 피하기 위해 사용되는 알고리즘입니다.
- 프로그램이 요청한 리소스를 위한 mutext를 하나 생성합니다.
- 시스템이 고유 ID를 부여합니다.(no wait mode의 latch와 비슷함)
- latch와 달리 mutext는 시스템이 관장합니다.
- latch의 spin을 수행하지 않기 때문에 가벼울 수 있습니다.
- 문제발생 oracle의 해결범위를 넘어섭니다.
- mutext의 경우 복구가 안됩니다.
뮤텍스의 기능을 이용함으로, Mutex pin을 사용하는 과정에서 이와 같은 현상이 발생하고, cursor pin s wait on x 대기가 발생합니다. 이는 library cache pin 개념과 동일합니다.
Mutex Holder 찾기
Oracle 10g부터 cursor: pin ...과 같은 이름의 대기 이벤트가 많이 관찰됩니다. Mutex가 동기화 객체로 사용되면서 나타난 현상인데, 이 Mutex의 문제는 Holder를 관찰하기가 쉽지 않습니다.
하지만 아래 Metalink Note를 읽어보면 의외로 쉽게 Mutext Holder를 찾을 수 있다는 것을 알 수 있습니다.
-- 64비트 시스템에서는 8자리, 32비트 시스템에서는 4자리를 취한다.
SELECT p2raw, to_number(substr(to_char(rawtohex(p2raw)), 1, 8), 'XXXXXXXX') sid
FROM v$session
WHERE event = 'cursor: pin S wait on X';
P2RAW SID
-------------
0000001F00000000 31
31은 첫8자리 0000001F 값의 10진수 값입니다. 즉, 현재 Holder가 31번 세션이라는 것을 의미합니다. 10GR2 부터는 V$SESSION.BLOCKING_SESSION 컬럼에 Holder 정보가 기록되어 더욱 손쉽게 Holder Session을 찾을 수 있습니다.
latch free(simulator lru latch)
DB Cache Advisor 기능이 사용하는 메모리 영역을 보호하는 latch입니다.
* 일반적인 문제상황 및 대처방안
- 원인: 큰 크기(수 GB이상)의 Buffer Cache를 사용 시 simulator lru latch 경함
- 진단 방법: DB Cache Advisor 기능이 활성화되어 있는지 확인
- 개선 방법: DB_CACHE_ADVICE 파라미터를 통하여 DB Caiche Advisor 기능 비활성화
* Latch란?
Latch는 특성상 획득할 때까지 게속해서 CPU를 점유하면서 스핀하여 Latch 획득 시도를 하기 때문에 다수의 세션이 Latch 대기를 하게되면 그만큼 CPU 사용률이 증가하게 도비니다. 그래서 Latch를 해결해야하는데 Simulator lru latch는 쿼리가 수행됐을 때, 해당하는 쿼리에 대해서 일종의 Simulation을 수행해보는 것이 아니라 latch free(simulator lru latch)를 해소하기 위해서는 DB_CACHE_ADVISOR 기능을 OFF 시키면 해당 이벤트 대기현상이 해소됩니다. 만약 운영시스템이 CPU에 민감하다면 이 기능을 OFF하는 것이 좋습니다.
DB_CACHE_ADVICE
oracle 9i 부터는 SGA 영역 크기를 온라인 상태에서 바꿀 수 있습니다. 이를 Dynamic SGA 기능이라고 합니다. 이렇게 바꿀 수 있는 메모리 영역은 Shared Pool, Buffer Cache, Large Pool 이렇게 세 가지입니다. 이 중 Buffer Cache 크기를 조절했을 때의 성능을 예측하는 Advisory 기능을 DB_CACHE_ADVICE 파라미터를 통하여 제공합니다. DB_CACHE_ADVICE = ON인 경우 Buffer Cache Advisory 기능이 enable 되며 V$DB_Cache_Advice 뷰를 통하여 내용을 확인할 수 있습니다. V$DB_Cache_Advice View에는 buffer cache 별로 현재 크기의 10%에서 200%까지 20개의 크기에 대한 simulation 정보를 기록합니다. 각 크기별로 기존 block 참조 정보를 이용해서 예상되는 물리ㅏ적 일기 수를 제공합니다.
* Buffer Cache Advisory 기능 사용은 다음 두가지의 오버헤드를 일으킵니다.
1) Advisory 기능은 buffer cache 별로 bookkeeping을 위한 아주 약간의 CPU 오버헤드가 필요하다.
2) MEMORY: Advisory 기능은 buffer block 당 Shared Pool에서 약 700 byte 정도의 메모리를 할당한다.
* parameter는 ON, OFF, READY 세 가지 값을 가질 수 있는데, 각 상태의 의미는 다음과 같습니다.
1) OFF: Advisory 기능이 disable 되고, CPU나 MEMORY 오버헤드가 없음
2) ON: Advisory 기능이 enable 되고, CPU나 MEMORY 오버헤드가 발생
3) READY: Advisory 기능은 disable되나, Shared Pool의 메모리는 할당
READY나 ON의 경우, Shared Pool의 Contention이 발생하므로 오버헤드가 될 수 있습니다. 충분한 여유공간을 확인한 후 작업해야 합니다.
V$DB_CACHE_ADVICE 뷰
id: Buffer Cache의 id(1~8)
name: Buffer Cache의 이름
block size: Buffer Cache의 block 크기
advice_status: Buffer Cache Advisory 기능의 상태(ON or OFF: Ready 상태도 OFF로 표시)
size_for_estimate: simulation에 사용한 Buffer Cache의 크기(KB)
buffers_for_estimate: simulation에 사용한 Buffer Cache의 개수(blocks)
estd_physical_read_factor: 물리적 읽기 예상#/Buffer Cache 일기#
estd_physical_reads: 물리적 읽기 예상치
estd_physical_read_factor는, 실제 Buffer Cache Advisory 기능을 enable 시킨 이후, Buffer Cache에 실제 발생한 physical read number 대비, Buffer Cache의 크기를 V$DB_CACHE_ADVICE 뷰의 row에 나와 있는 크기로 조정했을 때 예상되는 physical read number(estd_physical_reads)의 비율을 의미합니다.
출처: https://12bme.tistory.com/313 [길은 가면, 뒤에 있다.]
3.12 분석함수의 튜닝 고려사항[편집]
3.12.1 min/max 함수를 Ranking 함수 변경[편집]
- 최종일자에 해당하는 데이터를 구할 때, MAX(최종일자) 분석함수를 사용하지 말고 Ranking 분석 함수 사용.
- WINDOW BUFFER를 WINDOW NOSORT로 바꾸어 SORTING 부하를 줄여 줌.
SELECT /*+ LEADING(A) USE_NL(B) */ A.*, B.AMOUNT_SOLD
FROM ( SELECT /*+ INDEX_DESC(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID,
RANK() OVER(PARTITION BY CUST_ID, CHANNEL_ID ORDER BY TIME_ID DESC) RNK,
ROWID AS RID
FROM SALES_T T
WHERE PROD_ID = 30 ) A,
SALES_T B
WHERE A.RNK = 1
AND A.RID = B.ROWID;3.12.2 ORDER BY 절에 NULL FIRST나 LAST를 삭제 검토[편집]
- 분석함수의 ORDER BY 절에 NULL FIRST나 LAST를 삭제할 수 있는지 검토.
- 인덱스 사용에 의한 Sort 유지 되도록 하여 추가적인 sort를 방지.
- 1) Index ASC로 사용 + 분석함수의 ORDER BY절에 NULL FIRST 는 추가적인 sort발생
- 2) Index DESC로 사용 + 분석함수의 ORDER BY절에 NULL LAST 는 추가적인 sort발생
3.12.3 여러 개의 분석함수를 하나로 통합[편집]
- 분석함수를 여러 개 사용할 때, 가능하면 OVER절의 Partition By와 Order By절을 일치 하도록 검토.
- 분석함수를 하나만 실행하는 효과를 얻어서 실행시간을 단축하도록 검토 . 이때 ORDER BY는 완전히 같지 않아도 Operation은 통합 가능
- 1) WINDOW NOSORT + WINDOW SORT => WINDOW SORT
- 2) WINDOW NOSORT + WINDOW BUFFER => WINDOW BUFFER
- 3) WINDOW BUFFER + WINDOW SORT => WINDOW SORT
3.12.4 Ranking 분석함수 이용 TOP SQL의 Sort 최소화[편집]
- Ranking 분석함수를 인라인뷰 외부에서 Rownum 처럼 Filter로 사용 시 불필요한 Partition By 절 삭제 검토 .
- FULL SCAN을 하거나 혹은 OVER절의 NULL FIRST나 LAST등의 원인으로 sort가 발생될 때 .
- Rownum과는 달리 STOPKEY가 발생되지 않으므로 비효율은 존재.
- 이 때 발생되는 오퍼레이션 은 WINDOW SORT PUSHED RANK
- 적절한 인덱스가 있어서 sort가 발생되지 않는 경우, Rownum 처럼 STOPKEY를 발생시켜 부분범위 처리의 효과.
- 분석함수를 Rownum 처럼 사용. WINDOW NOSORT STOPKEY 오퍼레이션 발생.
- FULL SCAN을 하거나 혹은 OVER절의 NULL FIRST나 LAST등의 원인으로 sort가 발생될 때 .
- 1) Partition By절 전체를 제거해야 한다는 것.
- 만약 Partition By절에 컬럼이 하나라도 있으면 Sort가 대량으로 발생.
3.12.5 그룹 분석함수 NO-SORT[편집]
- Sort를 방지하고, STOPKEY 작동, sum/min/max/avg등의 Group 분석함수를 사용할 경우 명시적으로 WINDOW의 범위를 지정.
- WINDOW BUFFER Operation을 WINDOW NOSORT로 바꾸어 불필요한 sort를 방지.(현재 row 까지의 누적집계 시 )
- 예시)
SUM(AMOUNT_SOLD) OVER(ORDER BY CUST_ID,CHANNEL_ID,TIME_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
- 1) Ranking 함수를 사용하여 WINDOW STOPKEY가 발생하는 경우는 SORT가 발생하지 않는 경우(NOSORT)뿐.
- 그룹분석함수에 의해서 추가적인 SORT를 해야 한다면, 전체범위로 처리됨으로 STOPKEY가 발생하지 않음.
3.13 병렬 쿼리 튜닝[편집]
3.13.1 병렬처리 핵심은?[편집]
3.13.1.1 그래뉼[편집]
android The basic unit of work in parallelism is a called a granule.
Oracle Database divides the operation executed in parallel (for example, a table scan, table update, or index creation) into granules.
- 병렬로 처리할때 일의 최소 단위
- 병렬 서버는 한번에 하나의 그래뉼씩 처리 함
- 그래뉼 갯수와 크기는 병렬도와 관련되고 분산처리에 영향을 미침
- 블록 그래뉼 과 파티션 그래뉼로 나뉨
- 병렬 쿼리 granule
3.13.1.1.1 블록 그래뉼[편집]
- PX BLOCK ITERATOR 라고 표시
- QC는 테이블로부터 읽어야할 범위의 블록 GRANULE로서 각 병렬 서버에게 할당
- 파티션 여부,파티션 갯수 와 무관하게 병렬도 지정이 가능
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
==========> 블록 이터레이터로 표시됨
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------3.13.1.1.2 파티션 그래뉼[편집]
- PX PARTITION RANGE ALL
- 전체 파티션을 읽을때 표시
- PX PARTITION RANGE ITERATOR 라고 표시
- 일부 파티션만 읽을 때 표시
- 사용되는 시기
- Partition-Wise 조인 시
- 파티션 인덱스를 병렬로 스캔할 시
- 파티션 인덱스를 병렬로 갱신할 때
- 파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
- 병렬도는 파티션 갯수 이하로만 지정 할수 있음(튜닝 요소)
- 1개 파티션을 2개의 프로세스가 함께 처리 할수 없음
- 예시) WHERE 조건에 파티션 컬럼이 1개만 타도록 제한된 경우 아래 예시 참조
- 병렬 서버가 한 파티션 처리를 끝마치면 다른 파티션을 할당 받아서 진행 함(병렬도가 파티션 갯수 보다 적을때)
---------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000| 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
==========> 파티션 RANGE ... 로 표시됨
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES| 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST|26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
---------------------------------------------------------------------------------------------------3.13.1.2 파티션-와이즈 조인 Partition-wise Join[편집]
- 기본적인 원리는 커다란 하나의 조인을 분할하여 여러개의 작은 조각으로 나누는것
- 머지조인, 해시조인시 적용하는 최적화 기법
- 파티션 와이즈 조인은 파티션 테이블이 필수 임
- 조인처리에 사용되는 cpu,memory,네트워크 리소스를 줄이는 방법임
- '-wise' 의미 [1]
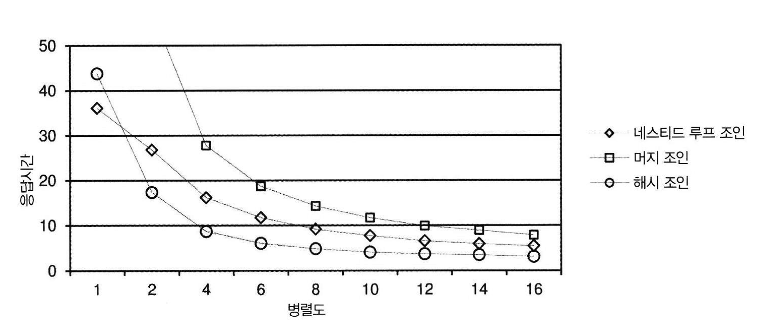
- 조인 과 병렬도 성능 비교
3.13.1.2.1 풀 파티션-와이즈 조인[편집]
- Full Partition-Wise Join (완전 동등하게 조인)
- 동등하게 파티션된 2개 테이블을 조인 함
- 대규모 조인이 예상되는 테이블은 동등한 파티션으로 설계할것을 모델링 단계에서 고려할것
- (주의사항) 리스트 파티션은 동일 갯수,동일 순서가 맞도록 파티션 되어야 함
- 서브파티션과도 조인 가능
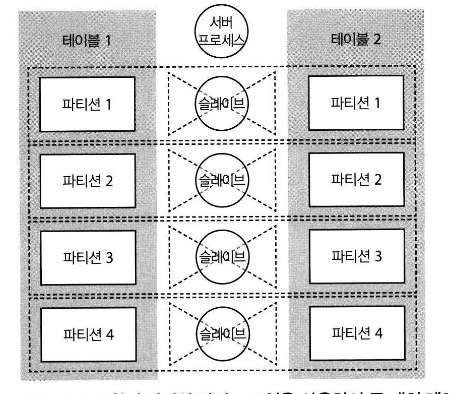
3.13.1.2.2 부분 파티션-와이즈 조인[편집]
- Patial Partition-Wise Join (부분)
- 병렬로만 수행이 가능함
- 한쪽 테이블만 조인키 기준으로 파티션 된 경우임
- 부분 파티션 조인시 일반 조인보다는 빠르지만 큰 성능 향상을 기대하기는 어렵다.(오히려 성능이 나빠질수도 있다)

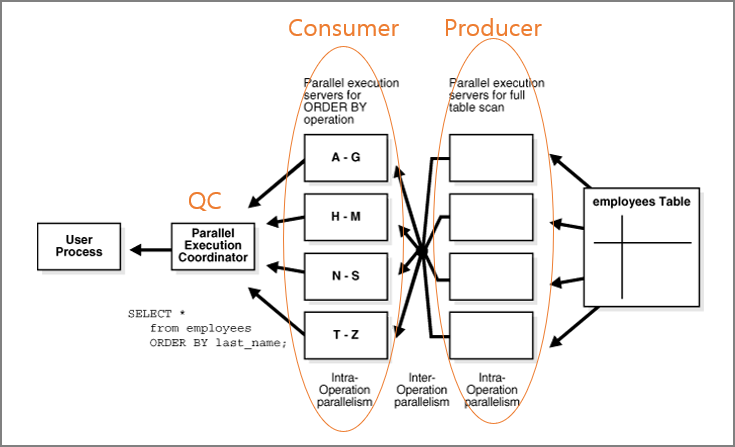
3.13.1.4 DOP 많을수록 좋을까?[편집]
3.13.1.4.1 DOP 32 => DOP 16 으로 줄여서 성능개선[편집]
- 튜닝 전
MERGE /*+ENABLE_PARALLEL_DML PARALLEL(32) FULL(T) USE_HASH(T)*/
INTO TB_TEST1 T
USING (
SELECT PLAN_ID
, GRFNLID
, IDMB_ID
, SBWDC_ID
.... 생략 ....
- 튜닝 후
- - 분배 방식 및 ACCESS 방식 변경을 위한 힌트 추가.
- 약 1천 9백만건 이상 MERGE 되는 대량 DML 문으로 원본도 병렬 처리가 잘되고 있어 크게 개선 될 포인트는 없음.
- parallel degree는 16으로 내렸으며 약 583초(8분23초) 수행.(변경전 700초)
- SQL 변경
MERGE /*+ ENABLE_PARALLEL_DML PARALLEL(T 16) LEADING(S) FULL(T) USE_HASH(T) PQ_DISTRIBUTE(T HASH HASH) */
INTO TB_TEST1 T
USING (
SELECT PLAN_ID
, GRFM_ID
, IDM8_ID
.... 생략 ....3.13.1.6 병렬 PLAN 해석하는 방법[편집]
- XPLAN 조회 ( ‘+PARTITION +PARALLEL +OUTLINE' )
-- 병렬 쿼리 확인
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST ADAPTIVE PARTITION PARALLEL OUTLINE'));--------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1638 | 7 (29)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
----------[3] 서버집합(Q1,02)은 전송받은 레코드를 정렬하고 나서 QC에게 전송한다.
| 2 | PX SEND QC (ORDER) | :TQ10002 | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | P->S | QC (ORDER) |
| 3 | SORT ORDER BY | | 14 | 1638 | 7 (29)| 00:00:01 | Q1,02 | PCWP | |
------------[소비자]
| 4 | PX RECEIVE | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,02 | PCWP | |
-------------[2] 1번째 서버집합(Q1,01)은 EMP테이블을 병렬로 읽으면서 QC에서 받은 DEPT테이블과 조인하고,조인에 성공한 레코드는 2번째 서버집합(Q1,02)에게 전송한다.
-------------[생산자]
| 5 | PX SEND RANGE | :TQ10001 | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | P->P | RANGE |
|* 6 | HASH JOIN | | 14 | 1638 | 6 (17)| 00:00:01 | Q1,01 | PCWP | |
| 7 | BUFFER SORT | | | | | | Q1,01 | PCWC | |
----------------[소비자]
| 8 | PX RECEIVE | | 4 | 120 | 3 (0)| 00:00:01 | Q1,01 | PCWP | |
-----------------[생산자]
| 9 | PX SEND BROADCAST | :TQ10000 | 4 | 120 | 3 (0)| 00:00:01 | | S->P | BROADCAST |
------------------[1] QC가 DEPT 읽어서 1번째 서버집합(Q1,01)에게 전송 한다
| 10 | TABLE ACCESS FULL| DEPT | 4 | 120 | 3 (0)| 00:00:01 | | | |
| 11 | PX BLOCK ITERATOR | | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWC | |
| 12 | TABLE ACCESS FULL | EMP | 14 | 1218 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
--------------------------------------------------------------------------------------------------------------------
3.13.1.6.1 SQL 플랜상 튜닝 검토 사항[편집]
android # broadcast 는 소량테이블에 적합(임시로 생성한 테이블에 통계정보가 있는지 확인필요)
- hash 는 대량 테이블에 적합
- S->P 는 튜닝 대상임. P->P로 바꿀수 있는 방법을 검토.sql수정도 좋다.
- round-robin 은 튜닝 대상임
- merge 나 insert ,delete문에만 주로 Parallel 힌트 사용. 하위 select 문에서는 가급적 지양 , 1:1 관계를 지향한다
- part key 플랜도 튜닝 대상. pq_disiribute(A hash hash) 힌트로 변경 검토
- 오라클은 내부적 으로 어떤 힌트를 사용하고 있는지 볼까 ?
- OUTLINE

3.13.2 슬기로운 병렬처리 사용법[편집]
- 병렬도를 같게 지정하는 것이 바람직 함.
- 테이블별 개별 힌트- PARALLEL(A 8) 보다 글로벌 힌트- PARALLEL(8)로 적용
3.13.2.1 병렬 힌트를 어디에 어떻게 써야 하나?[편집]
3.13.2.1.1 SELECT 절 병렬 힌트[편집]
- 조인 순서 지정 - leading() , ordered 힌트사용
- 조인 방식 지정 - use_nl(),use_hash(),use_merge()
- * hash 조인일때 - SWAP_JOIN INPUTS() , NO_SWAP_JOIN INPUTS() - Build Input 지정
- FULL() 힌트 사용 - 옵티마이저가 인덱스 스캔을 선택하면 parallel 힌트가 무시됨
- PO_DISTRIBUTE() 분산 방식 지정
SELECT
-- 튜닝 전
/* FULL(BA) FULL(BB) FULL(BC) FULL(BD)
PARALLEL(BA 16)
PARALLEL(BB 16)
PARALLEL(BC 16)
PARALLEL(BD 16) */
-- 튜닝 후
/*+ PARALLEL(16)
LEADING(BB) USE HASH(BA BB BC BD )
FULL(BA) PO_DISTRIBUTE(BA HASH HASH) NO_SWAP_JOIN INPUTS(BA)
FULL(BB) PO_DISTRIBUTE(BB HASH HASH) SWAP_ JOIN_INPUTS(BB)
FULL(BC) PQ_DISTRIBUTE(BC HASH HASH) NO_SWAP_JOIN_INPUTS(BC)
FULL(BD) PQ_DISTRIBUTE(BD HASH HASH) NO_SWAP_JOIN_INPUTS (BD)
*/
....
FROM TB_MB. BA -- 20G
, TB_FM BB -- 5G
, TB_FMBR BC -- 8G
, TB_IDM BD -- 13G
WHERE 1 = 1
AND BA.Q_ID IN (
SELECT DISTINCT O_ID
......3.13.2.1.2 INSERT 절 병렬 힌트 위치[편집]
INSERT /*+ PARALLEL (4) ENABLE_PARALLEL_DML */ -- PQ_DISTRIBUTE(T NONE)
INTO TB_WM_DTLS T3.13.2.1.3 INSERT 절 병렬 힌트 적용 안되는 경우[편집]
-- insert 앞에 힌트
/*+ PARALLEL (4) ENABLE_PARALLEL_DML*/ -- PQ_DISTRIBUTE(T NONE)
INSERT INTO
TB_XM_DTLS T
....
-- into 뒤에 힌트
INSERT INTO /*+ PARALLEL (4) ENABLE_PARALLEL_DML */ -- PQ_DISTRIBUTE(T NONE)
TB_XM_DTLS T
....3.13.2.1.4 UPDATE/ DELETE / MERGE 힌트 위치[편집]
UPDATE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ 테이블명 ~
DELETE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ FROM 테이블 ~
MERGE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ INTO 테이블명 ~
3.13.2.2 DDL 병렬 처리[편집]
SQL> alter session enable parallel ddl;3.13.2.2.1 CREATE 예시[편집]
-- 테이블 생성
CREATE TABLE name ( column1 [data-type], ... )
Parallel 8;
-- 인덱스 생성 DOP 32
CREATE INDEX CYKIM.IX_TBL_X01
ON (MY_TABLE)
TABLESPACE TS_CY PARALLEL 32 NOLOGGING;
ALTER INDEX CYKIM.IX_TBL_X01 NOPARALLEL LOGGING;3.13.2.2.2 ALTER 예시[편집]
ALTER TABLE name Parallel 8 ;3.13.2.3 DML 병렬 처리[편집]
- DML 작업에서는 Paralle 힌트를 주어도 QC 가 작업 담당
- 병렬 DML 가능하도록 처리
- 12c 이전 에는 세션에 적용
SQL> alter session enable parallel dml;- 12c 부터는 힌트로 적용
/*+ ENABLE_PARALLEL_DML */


3.13.2.3.2 DML 병렬 처리시 주의사항[편집]
android *DML 병렬 처리시 주의사항
- 테이블 전체에 Exclusive 모드로 Lock 획득하므로 주의
- 커밋/롤백을 해야 SELECT 가능 함.
- DML 처리시 플랜에서 항상 QC 아래에 INSERT/UPDATE/DELETE 가 존재 해야 한다. (QC가 아닌 병렬서버에서 처리 토록 해야 한다.)
3.13.2.4 동일 테이블에 병렬로 입력 하는 방법[편집]
- Oracle에서 파티션 테이블을 이용하여 데이터를 병렬로 입력하는 방법
- 파티션 테이블은 데이터를 물리적 또는 논리적 파티션으로 분할한 테이블입니다.
- 아래 예시에서 INSERT INTO ... SELECT 문을 사용하여 병렬로 데이터를 입력하는 방법을 보여줍니다.
-- 파티션 테이블 생성
CREATE TABLE sales (
sale_id NUMBER,
sale_date DATE,
product_id NUMBER,
quantity NUMBER
)
PARTITION BY RANGE (sale_date) (
PARTITION sales_202301 VALUES LESS THAN (TO_DATE('2023-02-01', 'YYYY-MM-DD')),
PARTITION sales_202302 VALUES LESS THAN (TO_DATE('2023-03-01', 'YYYY-MM-DD'))
);
-- 병렬로 데이터 입력
-- 세션 1에서 데이터 입력
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(sales, 4) */ INTO sales
SELECT sale_id, TO_DATE('2023-01-15', 'YYYY-MM-DD'), product_id, quantity FROM sales_data_january;
commit; -- 커밋을 해야 다른세션에서도 커밋이 가능하다
-- 세션 2에서 데이터 입력
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(sales, 4) */ INTO sales
SELECT sale_id, TO_DATE('2023-02-15', 'YYYY-MM-DD'), product_id, quantity FROM sales_data_february;
commit;- ORA-12838 : 병렬로 수정한 후 객체를 읽거나 수정할 수 없습니다. 오류 발생시 커밋 여부를 확인할것. 같은 세션에서도 커밋하지 않으면 조회도 불가능하다.
3.13.3 병렬 처리 진행 사항 모니터링[편집]
3.13.3.1 진행 사항 모니터링 관련 뷰[편집]
- DISK I/O 확인
- - V$SESS_IO
- LONG OPS
- - V$SESSION_LONGOPS
- CURRENT STATMENT
- - V$PX_SESSION
- Session Wait Event
- - V$SESSSION_EVENT
3.13.3.2 REAL MONITOR[편집]
- 사용법
SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR('5yfzxpu5593jw') FROM DUAL;



- html 포멧으로 출력
select dbms_sqltune.report_sql_monitor(sql_id=>'5yfzxpu5593jw',type=>'html', report_level=>'ALL') from dual;
3.13.3.3 병렬_쿼리_모니터링[편집]
3.13.3.3.1 병렬 세션 조회[편집]
select c.sid as qcsid
, s.sid as slasid
, p.server_name
from v$session c
, v$px_session s
, v$px_process p
where c.sid = s.qcsid
and c.sid = &SID_OF_SESSION_1
and p.sid = s.sid;3.13.3.3.2 병렬 처리 데이터 전송 통계 확인[편집]
select tq_id,server_type,process,num_rows,bytes,waits
from V$PQ_TQSTAT
order by dfo_number
, tq_id
, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3)
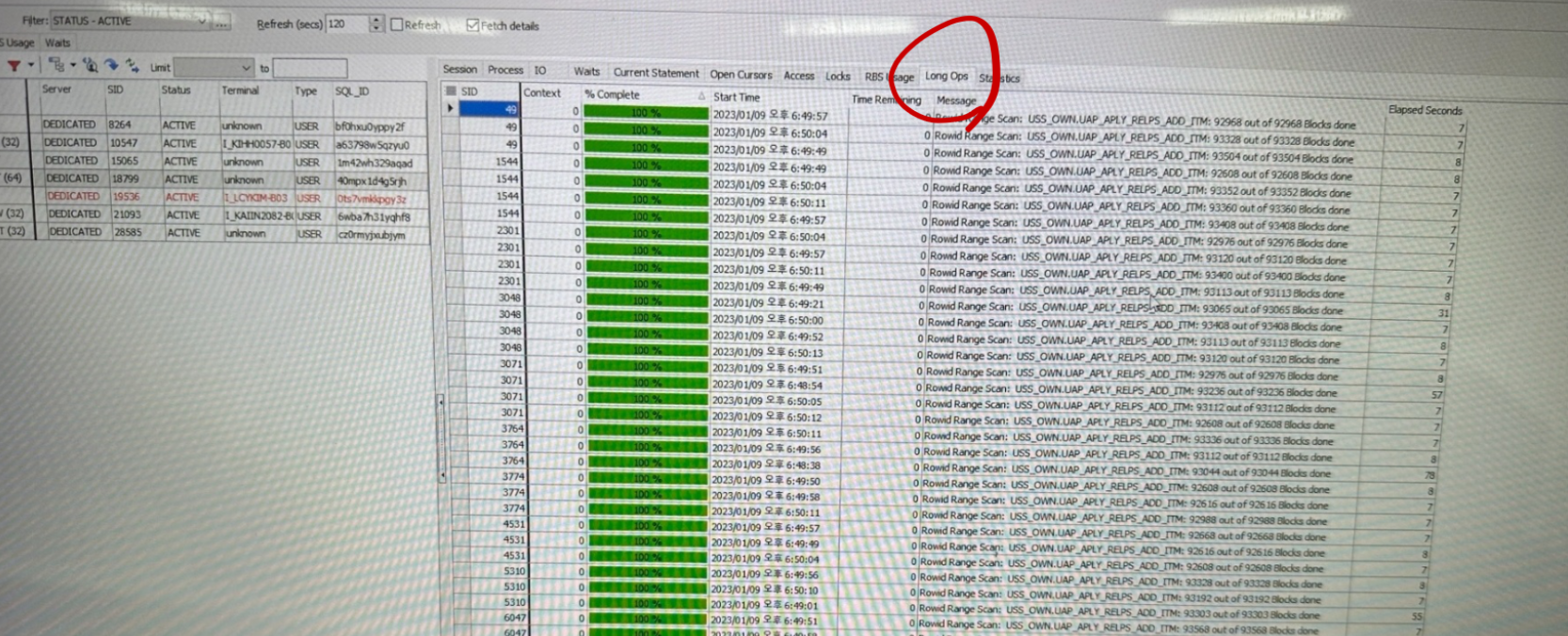
, process;3.13.3.4 토드에서 모니터링 하는 방법[편집]
- Database - Session Browser
- IO 탭
- Waits 탭
- Current Statsment 탭
- Long Ops 탭
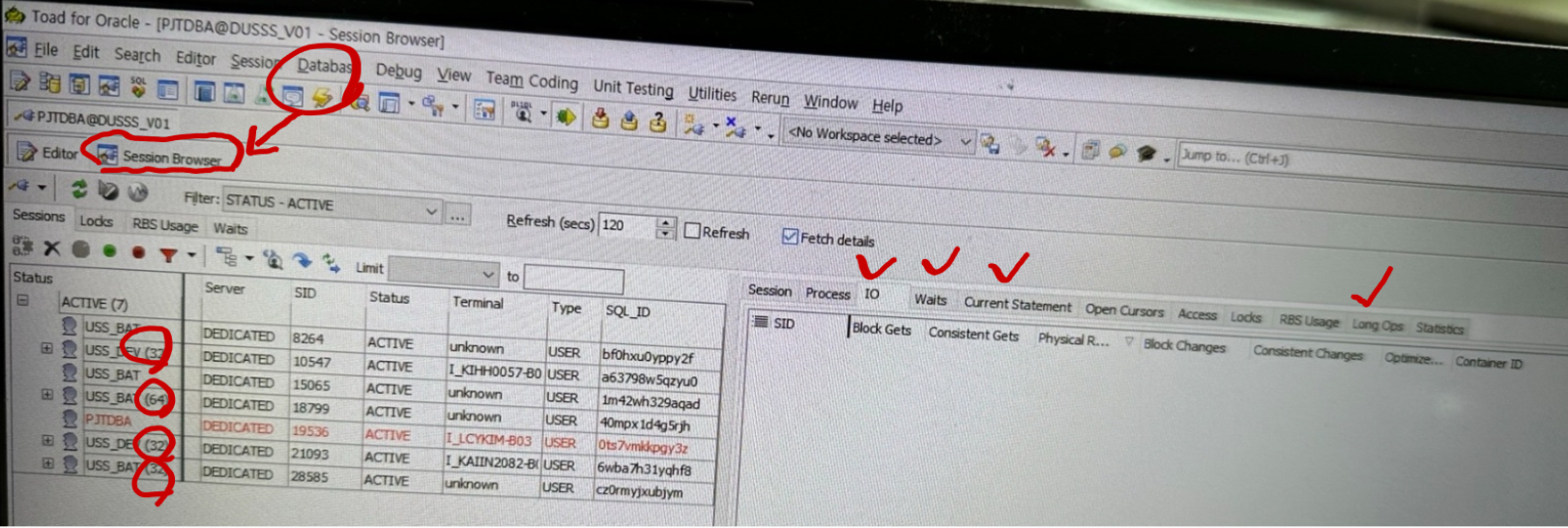

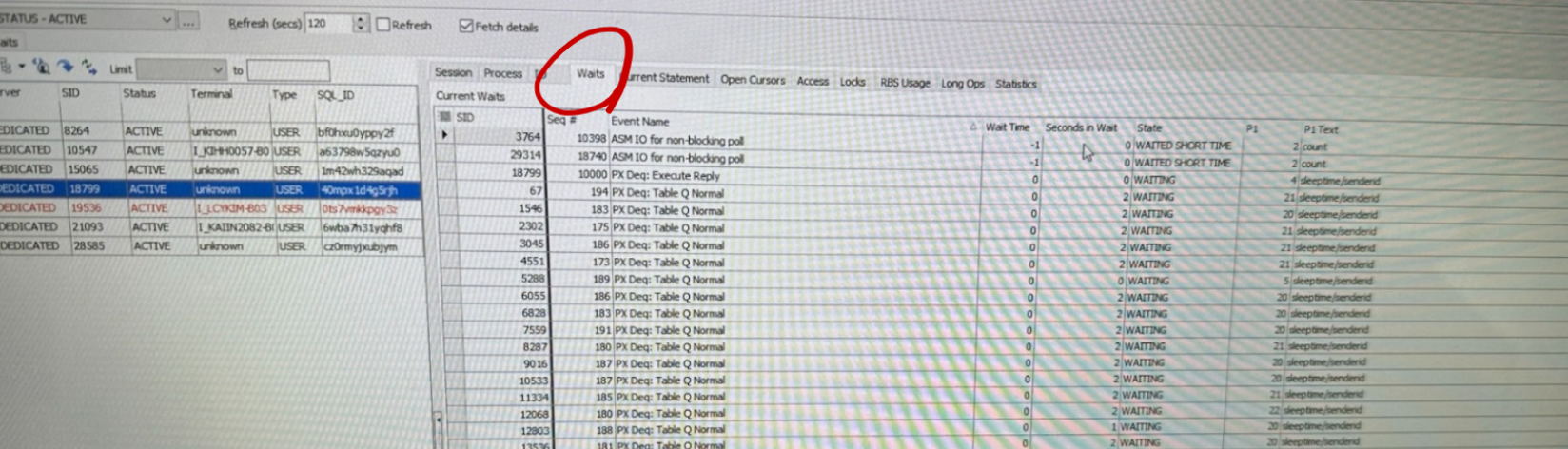

3.13.3.5 병렬 처리 WAIT EVENT 확인 방법[편집]
3.13.3.5.1 병렬 처리 대기 이벤트 발생 순서[편집]
- PX Deq: Execute Replay,작업 끝날때까지 대기중
- SQL*Net message from client, 클라이언트로 부터 추가 Fetch Call이 오기를 기다리고 있음을 의미함.
3.13.3.5.2 병렬 처리 대기이벤트 종류[편집]
- PX Deq: Parse Reply
- - PEC 가 PES 에게 파싱 요청을 한 후 응답이 올 때까지 대기하는 이벤트
- - 10G 에서 도입된 PSC(Parallel Single Cursor) 모델에서는 PEC가 생성한 커서를 공유하기 때문에 이러한 과정은 생략된다.
- - 단. RAC 에서는 여전히 PEC 와 다른 노드에 존재하는 PES는 PEC가 생성한 SQL문을 파싱하는 역할을 수행
- PX Deq: Execute Reply
- - QC가 각 병렬 서버에게 작업을 배분하고 작업이 완료 되기를 기다리는 대기이벤트.
- PX Deq Credit : need buffer
- - 데이터를 전송하기 전에 수신 병렬서버 또는 QC로 부터 credit 비트를 얻으려고 대기하는 상태
- - PX Deq Credit:send blkd(로컬 시스템) 과 PX Deq Credit:need buffer(RAC 에서)은 거의 같은 대기 이벤트임.
- - 오라클은 두 프로세스 중 한 순간에 오직 하나의 프로세스만이 테이블 큐에 데이터를 집어넣을 수 있도록 보장한다.
- - 테이블 큐에 데이터를 집어넣을 수 있는 자격을 확보할 때까지 기다리는 이벤트다.
- PX Deq: Execution Msg
- - 병렬서버가 자신의 작업을 마치고 다른 병렬서버가 일을 끝나기를 기다리는 이벤트.
- - QC 또는 소비자 병렬 서버에게 데이터 전손을 완료했을때 나타남
- PX Deq: Table Q Normal
- - 테이블 큐에 데이터가 들어오기를 기다리는 이벤트
- direct path read
- - 버퍼 캐시를 경유하지 않고 데이터 파일로부터 직접 데이터를 읽는 과정에서 발생하는 이벤트
- - 테이블로부터 데이터를 페치하는 작업은 대부분 데이터 파일에서 직접 데이터를 읽는 방식을 사용.
- enq: TC Contention
- - QC가 Direct Path I/O를 수행하려면, 해당 테이블에 대한 체크 포인트(Checkpoint)작업이 선행 되어야 한다.
- - 버퍼 캐시의 더티 버퍼가 모두 데이타 파일에 기록되어야 버퍼 캐시를 경유하지 않고 데이터 파일에서 직접 데이터를 읽을 수 있기 때문이다.
- - 작업을 지시하기 전에 체크포인트 요청을 하고 작업이 끝날 때 까지 기다려야 하며 그 동안 enq: TC Contention 이벤트 대기
3.13.3.5.3 병렬 세션 대기,대기 이벤트,대기 클래스 조회[편집]
- V$PX_SESSION + V$SESSION
SELECT DECODE(A.QCSERIAL#, NULL, 'PAREMT', 'CHILD') ST_LVL,
A.SERVER_SET "SET",
A.SID,
A.SERIAL#,
STATUS,
EVENT,
WAIT_CLASS
FROM V$PX_SESSION A,
V$SESSION B
WHERE A.SID = B.SID
AND A.SERIAL# = B.SERIAL#
ORDER BY A.QCSID,
ST_LVL DESC,
A.SERVER_GROUP,
A.SERVER_SET
;3.13.3.5.4 WAIT EVENT - 상세 대기시간 확인[편집]
- V$SESSION + V$SESSSION_EVENT
SELECT S.INST_ID, S.SID, S.SQL_ID
, S.MACHINE, S.PROGRAM, S.EVENT
, S.BLOCKING_SESSION_STATUS
, SE.EVENT AS EVENT_DTL
, SE.WAIT_CLASS , SE.TIME_WAITED
, SE.MAX WAIT , SE.TOTAL_TIMEOUTS
FROM GV$SESSION S
, GV$SESSION_EVENT SE
WHERE S.SID = SE.SID
AND S.INST ID = 1
AND S SID=8281
-- AND SE.EVENT = 'gc current grant busy'
-- AND S.SQL ID = ''
AND SOL_ID IS NOT NULL
ORDER BY SE.TIME_WAITED DESC3.13.3.5.5 대기항목별 WAIT CLASS 확인[편집]
- V$SESSION_WAIT + V$SESSSION_WAIT_CLASS
SELECT A.SID, A.SEQ#, A.EVENT,P1TEXT
, A.STATE , A.WAIT_TIME_MICRO
, A.TIME_REMAINING_MICRO
, B.WAIT_CLASS#, B.WAIT_CLASS
, B.TOTAL_WAITS, B. TIME_WAITED
FROM GV$SESSION WAIT A
, GV$SESSION_WAIT_CLASS B
WHERE A.INST_ID = B.INST_ID
AND A.INST_ID =1
AND A.SID = B.SID
AND A.SID = :SID -- 1510
AND A.SERIAL# = B.SERIAL#3.13.4 PARALLEL 힌트를 사용해도 병렬 처리가 안되는 경우[편집]
3.13.4.1 병렬 처리 갯수 확인[편집]
3.13.4.1.1 병렬처리 제약 조건[편집]
SELECT * FROM V$PARAMETER
WHERE NAME IN ('parallel_degree_limit') ; -- CPU- CPU
- 최대 병렬 처리 갯수가 시스템의 CPU 수에 따라 제한(기본값)
- 제한을 계산하는 데 사용되는 공식은 PARALLEL_THREADS_PER_CPU * CPU_COUNT * 사용 가능한 인스턴스 수입니다(기본적으로 클러스터에서 열려 있는 모든 인스턴스이지만 PARALLEL_INSTANCE_GROUP 또는 서비스 사양을 사용하여 제한할 수 있음).
- AUTO
- CPU 값과 동일
- IO
- 옵티마이져가 사용할 수 있는 최대 병렬 처리 갯수은 시스템의 I/O 용량에 따라 제한
- 이 값은 전체 시스템 처리량을 프로세스당 최대 I/O 대역폭으로 나누어 계산
- IO 설정을 사용하려면 시스템에서 DBMS_RESOURCE_MANAGER.CALIBRATE_IO 프로시저를 실행해야 하고 이 절차에서는 전체 시스템 처리량과 프로세스당 최대 I/O 대역폭을 계산함
- 숫자
- 이 파라메터의 숫자값은 자동 병렬 처리 수준이 활성화된 경우 최적화 프로그램이 SQL 문에 대해 선택할 수 있는 최대 병렬 처리 수준을 지정 함
- 자동 병렬 처리 갯수는 PARALLEL_DEGREE_POLICY가 ADAPTIVE, AUTO 또는 LIMITED로 설정된 경우에만 활성화 됨
- DOP 최대 갯수 = parallel_threads_per_cpu * cpu_count
SELECT *
FROM V$PARAMETER
WHERE NAME in ('parallel_threads_per_cpu','cpu_count')3.13.4.2 병렬 환경 파리미터 상세 조회[편집]
SELECT *
FROM V$PARAMETER
WHERE NAME LIKE '%parallel%'
3.13.4.3 병렬처리가 안되는경우[편집]
- 병렬 요청/할당 확인
select sid,serial#
, server_group,server_set
, degree , req_degree
from v$PX_SESSION:3.13.4.3.1 서버에서 프로세스를 할당 받지 못할때[편집]
3.13.4.3.2 insert ~ select 의 병렬도가 다를때[편집]
3.13.4.3.3 파티션닝 테이블에 1개파티션만 타는경우[편집]
- 튜닝 전
- LINK_ID 가 파티션키임.
- 플랜


- 튜닝 후
- 튜닝 후 플랜



3.13.4.3.4 LOB 컬럼 포함시[편집]
- lob 컬럼 포함시 => 오라클 19c 부터기능
3.13.4.3.5 DB 링크[편집]
3.13.4.3.6 기타 요소[편집]
- 할당된 process 갯수가 작을때 (오라클 파라미터 확인,v$parameter)
- OS상 디스크 I/O가 너무 느릴때
3.13.5 병렬 힌트 활용[편집]
3.13.5.1 PQ_DISTRIBUTE[편집]

3.13.5.1.1 가능한 조합[편집]
- HASH - HASH : OUTER, INNER 크기가 비슷할 때
- BROADCAST - NONE : OUTER 테이블이 작을때
- NONE - BROADCAST : INNER 테이블이 작을때
- PARTITION - NONE : INNER 테이블 파티션 기준으로 OUTER 테이블을 파티션 하여 분배
- NONE - PARTITION : OUTER 테이블 파티션 기준으로 INNER 테이블을 파티션 하여 분배
- NONE - NONE : 두 테이블이 조인컬럼 기준으로 파티션 되어 있을때
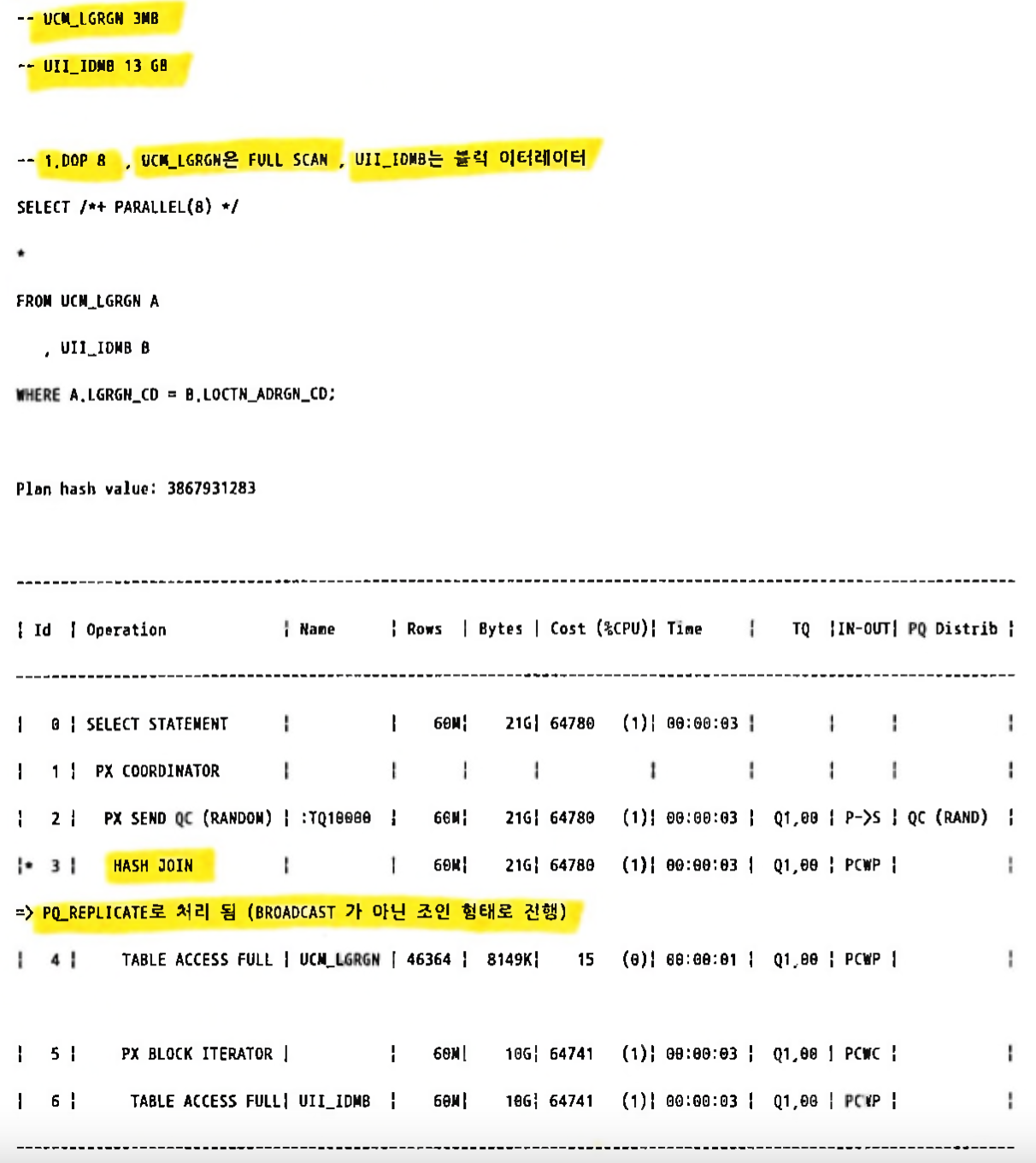
3.13.5.2 PQ_REPLICATE / NO_PQ_REPLICATE(대량테이블명)[편집]
- 각각 병렬서버에서 테이블 전체를 읽음
- BROADCAST 문제점을 보완 하는 힌트
- BROADCAST처럼 분산 하여 읽지 않음(병렬도가 많을수록 BROADCAST 방식은 분배시 부하 발생)
- 로컬 캐시(SGA) 에서 빠르게 읽는 방식
- 복제라기보다는 조인처럼 생각
- 매우 작은 테이블 처리시 유리
- 튜닝 예시 (소량테이블(3MB)이 BROADCAST 가 아닌 조인 형태로 병렬 처리됨)
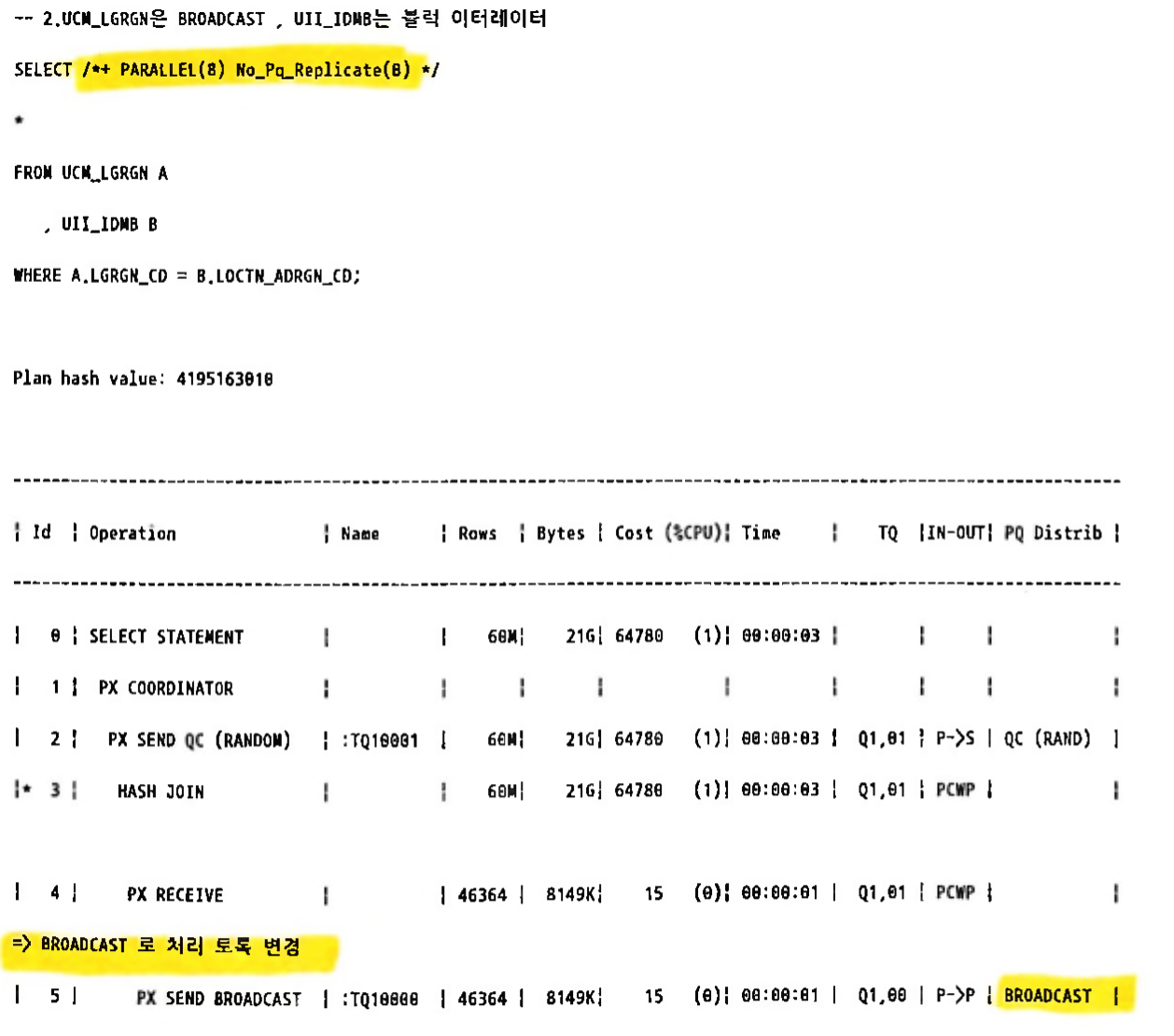
- 소량테이블(3MB)이 BROADCAST 처리 하도록 힌트 추가 (NO_PQ_REPLICATE)
- 힌트 사용시 NO_PQ_REPLICATE(소량테이블명) 이 아닌 NO_PQ_REPLICATE(대량테이블명) 임을 주의
3.13.5.3 PQ_SKEW/NO_PQ_SKEW[편집]
- 다수의 로우가 같은 조인키값을 가지고 있어서 조인키의 분산값이 한쪽으로 치우친 경우
- 오라클에서 히스토그램을 생성해야 하지만 자동으로 병렬조인시 SKEW를 핸들링함
- 제약사항
- INNER 조인시
- 단일 컬럼 조인시만 가능, 여러개 컬럼은 안됨
- 병렬 HASH JOIN만 가능
- MERGE JOIN 은 안됨
- SKEW테이블은 일반 테이블만 (뷰, 결과셋은 기능제한됨)
- PQ_SKEW 힌트는 옵티마이저에게 병렬 조인에 대한 조인 키 값의 분포가 매우 왜곡되어 있다고 조언합니다.
- 즉, 높은 비율의 행이 동일한 조인 키 값을 가지고 있습니다.
- Tablespec에 지정된 테이블은 해시 조인의 프로브 테이블이다.
3.13.5.4 BF 블름필터(Bloom Filter)[편집]
- 어떤값이 어떤 집합에 속해 있는가를 검사하는 필터
- 패러럴 조인시 소비자간의 커뮤니케이션 데이터량 과 해시조인시 부하를 감소하기 위해 사용됨
- JOIN FILTER PRUNNING , RESULT CACHE
- 플랜에서 JOIN FILTER CREATE / USE
- :BF0000
3.13.5.4.1 블름필터 제어 힌트 ( PX_JOIN_FILTER / NO_PX_JOIN_FILTER )[편집]
- 사용 조건
- 해시/머지 조인시
- 파티션 조인시
- 병렬 PARALLEL 쿼리시
- 파티션/PARALLEL 둘다 아닌경우, 인라인뷰의 GROUP BY
- 선행 테이블의 상수조건이 없는 경우 오라클은 블름필터를 사용하지 않는다.
- 블름 필터를 만들때 선행 테이블은 필터집합을 만들때 사용.
3.13.5.5 PQ_DISTRIBUTE_WINDOW[편집]
- PQ_DISTRIBUTE_WINDOW 힌트는 윈도우 함수에 의해 생성된 행을 분배하는 방법에 대해 옵티마이져에게 지시함.
- PQ_DISTRIBUTE_WINDOW(@Query_block N) => N=1 for hash, N=2 for range, N=3 for list(예전 방식 9i)
- PQ_DISTRIBUTE_WINDOW 힌트는 아직 문서화되지 않았으며 MOS(내 oracle 지원)에는 참조가 없습니다.
select /*+parallel PQ_DISTRIBUTE_WINDOW(1)*/ table_name
, count(1) over (partition by table_name) cnt
from t_tab t\;Plan hash value: 4185789934
----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2426 | 46094 | 4 (25)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | WINDOW SORT | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | P->P | HASH |
| 6 | PX BLOCK ITERATOR | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWC | |
| 7 | INDEX FAST FULL SCAN| T_TAB_IDX1 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWP | |
----------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
PQ_DISTRIBUTE_WINDOW(@"SEL$1" 1)
INDEX_FFS(@"SEL$1" "T"@"SEL$1" ("T_TAB"."OWNER" "T_TAB"."TABLE_NAME"))
OUTLINE_LEAF(@"SEL$1")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/select /*+parallel PQ_DISTRIBUTE_WINDOW(2)*/ table_name
, count(1) over (partition by table_name) cnt
from t_tab tPlan hash value: 1125815052
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2426 | 46094 | 4 (25)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | WINDOW CONSOLIDATOR BUFFER| | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,00 | P->P | HASH |
| 6 | WINDOW SORT | | 2426 | 46094 | 4 (25)| 00:00:01 | Q1,00 | PCWP | |
| 7 | PX BLOCK ITERATOR | | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWC | |
| 8 | INDEX FAST FULL SCAN | T_TAB_IDX1 | 2426 | 46094 | 3 (0)| 00:00:01 | Q1,00 | PCWP | |
------------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
PQ_DISTRIBUTE_WINDOW(@"SEL$1" 2)
INDEX_FFS(@"SEL$1" "T"@"SEL$1" ("T_TAB"."OWNER" "T_TAB"."TABLE_NAME"))
OUTLINE_LEAF(@"SEL$1")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/3.13.5.6 PQ_EXPAND_TABLE / NO_PQ_EXPAND_TABLE[편집]
- PQ_EXPAND_TABLE
- 파티션테이블인 경우 한곳에 편중된 파티션이 있을때, 옵티마이저가 UNION 절로 변경하여 편중된 파티션과 다른 파티션을 나누어 병렬처리로 수행함.
- (예) 인라인뷰내 파티션테이블을 (GROUP BY하는 경우)발생함
- 19c New Feature
- 튜닝 사례 1 : 한곳에 치중된 파티션을 UNION ALL 로 분리
SELECT *
FROM
(SELECT /*+ PQ_EXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....
- 튜닝 사례 2 : 한곳에 치중된 파티션을 UNION ALL 로 분리 하지 않음.
SELECT *
FROM
(SELECT /*+ NO_PQ_EXPAND_TABLE(A2) */
AZ.SRV_INSTLID
, A2.CYKIM_TIMPL_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
, MIN(A2.DCRY_LNNO) AS DCRY_LNNO
FROM TB_BIG_PART A2 -- 파티션테이블의 한곳의 파티션에 치중됨, 예를 들어 2000년 이전 데이터는 PT_2001파티션에 1억건 존재 , 나머지는 1백만건
WHERE SUBSTR(A2.CYKIM_TMPL_ID, 0, 2) = 'am'
GROUP BY A2.SRV_INST_ID
, A2.CYKIM_TMP_ID
, A2.CYKIM_WRT_YMD
, A2.CYKIM_WRT_DGR
) A
, TB_CYKIM_SPRV B
.....3.13.5.7 PQ_CONCURRENT_UNION[편집]
- UNION ALL 성능향상
- UNION은 각각 SQL을 1개씩 SERIAL 하게 처리하는게 기본방식임
- 12C 부터 병렬쿼리 실행시 동시(CONCURRENT)에 처리토록 함
- 전체데이터 처리시 유리
- 부분범위 처리시 비추
- DEFAULT
select /*+PQ_CONCURRENT_UNION*/ * from (select * from t_obj union all select * from t_obj1)
Plan hash value: 1664138491
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 184K| 64M| 863 (1)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 184K| 64M| 863 (1)| 00:00:01 | Q1,00 | P->S | QC (RAND) |
| 3 | VIEW | | 184K| 64M| 863 (1)| 00:00:01 | Q1,00 | PCWP | |
| 4 | UNION-ALL | | | | | | Q1,00 | PCWP | |
| 5 | PX SELECTOR | | | | | | Q1,00 | PCWP | |
| 6 | TABLE ACCESS FULL| T_OBJ | 92299 | 10M| 431 (1)| 00:00:01 | Q1,00 | PCWP | |
| 7 | PX SELECTOR | | | | | | Q1,00 | PCWP | |
| 8 | TABLE ACCESS FULL| T_OBJ1 | 92299 | 10M| 431 (1)| 00:00:01 | Q1,00 | PCWP | |
----------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$2" "T_OBJ"@"SEL$2")
FULL(@"SEL$3" "T_OBJ1"@"SEL$3")
PQ_CONCURRENT_UNION(@"SET$1")
NO_ACCESS(@"SEL$1" "from$_subquery$_001"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
OUTLINE_LEAF(@"SET$1")
OUTLINE_LEAF(@"SEL$3")
OUTLINE_LEAF(@"SEL$2")
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
OPT_PARAM('_px_concurrent' 'false')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/3.13.5.8 PQ_FILTER[편집]
/*+ PQ_FILTER(SERIAL | NONE | HASH | RANDOM) */ -- 4개중 택1- 병렬서버에서 서브쿼리를 필터링할수 있는 기능.
- 서브쿼리 필터링은 일반적으로 메인쿼리가 모두 수행된 후 수행함.
- HASH방식과 RANDOM방식은 추가적인 버퍼링이 필요하므로 특별한 경우가 아니면 NONE 방식으로 사용하는것이 일반적일것으로 판단함.
- 다수의 서브쿼리 수행시 2개의 서브쿼리 모두 병렬서버에서 필터링됨.
- PQ_FILTER 사용예시 (with NO_UNNEST 힌트)
select /*+parallel PQ_FILTER(HASH)*/ * from t_obj1 o
where created in (select /*+ NO_UNNEST */last_analyzed
from t_tab t
where tablespace_name like :A)
;Plan hash value: 2440581449
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 110 | 12650 | 22159 (1)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | BUFFER SORT | | 110 | 12650 | | | Q1,01 | PCWP | |
|* 4 | FILTER | | | | | | Q1,01 | PCWP | |
| 5 | PX RECEIVE | | 92299 | 10M| 240 (1)| 00:00:01 | Q1,01 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | P->P | HASH |
| 7 | PX BLOCK ITERATOR | | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | PCWC | |
| 8 | TABLE ACCESS FULL| T_OBJ1 | 92299 | 10M| 240 (1)| 00:00:01 | Q1,00 | PCWP | |
|* 9 | TABLE ACCESS FULL | T_TAB | 2 | 30 | 26 (0)| 00:00:01 | | | |
------------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$2" "T"@"SEL$2")
PQ_FILTER(@"SEL$1" HASH)
FULL(@"SEL$1" "O"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
OUTLINE_LEAF(@"SEL$2")
SHARED(2)
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'true')
OPT_PARAM('_px_filter_parallelized' 'false')
DB_VERSION('12.1.0.2')
OPTIMIZER_FEATURES_ENABLE('12.1.0.2')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
- 서브 쿼리가 2개일 때 순서 조정 예시
- => ORDER_SUBQ 힌트(12c 이후) 로 서브쿼리의 수행순서 조정가능함.
SELECT /*+ PARALLEL(2) PQ_FILTER(NONE)
ORDER_SUBQ(@MAIN @SUB2 @SUB1) QB_NAME(MAIN) */
*
FROM T1 A
WHERE EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB1) */
1
FROM T2 B
WHERE B.C1 = A.C1)
AND EXISTS (SELECT /*+ NO_UNNEST QB_NAME(SUB2) */
1
FROM T3 C
WHERE C.C1 = A.C1)
3.13.5.9 파티션에 사용 힌트[편집]
3.13.5.9.1 USE_PARTITION_WISE_DISTINCT[편집]
- 12c 이상
- USE_PARTITION_WISE_DISTINCT 힌트를 사용하면 파티션 그래뉼로 중복 값을 제거
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_DISTINCT */ DISTINCT c1, c2 FROM t1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
----------- [!!!]
| 4 | HASH UNIQUE | | 0 | | | Q1,00 | PCWP | |
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------3.13.5.9.2 USE_PARTITION_WISE_GBY[편집]
- USE_PARTITION_WISE_GBY 힌트를 사용하면 파티션 그래뉼로 그룹핑 수행 할 수 있음
- 병렬 서버 간의 데이터가 분배가 발생하지 않음 (P->P 분배가 없음)
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_GBY */ c1, COUNT(c2) FROM t1 GROUP BY c1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
----------> [!!!]
| 4 | HASH GROUP BY | | 0 | | | Q1,00 | PCWP | |
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------3.13.5.9.3 USE_PARTITION_WISE_WIF[편집]
- 18c 이상
- USE_PARTITION_WISE_WIF 힌트를 사용하면 파티션 그래뉼로 분석 함수 수행
SELECT /*+ PARALLEL(T1 2) USE_PARTITION_WISE_WIF */ ROW_NUMBER () OVER (PARTITION BY c1 ORDER BY c2) FROM t1;
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | | |
| 1 | PX COORDINATOR | | 1 | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 0 | | | Q1,00 | P->S | QC (RAND) |
| 3 | PX PARTITION RANGE ALL| | 0 | 1 | 3 | Q1,00 | PCWC | |
| 4 | WINDOW SORT | | 0 | | | Q1,00 | PCWP | | -- !
| 5 | TABLE ACCESS FULL | T1 | 0 | 1 | 3 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------3.13.6 병렬 쿼리 튜닝 포인트[편집]
3.13.6.1 테이블 정보를 수집 하라[편집]
- 테이블 사이즈 조사
- 테이블 파티셔닝 여부
- 파티션 키
- 병렬처리가 가능한 인덱스(index_ffs , 파티션 로컬 인덱스)
3.13.6.2 스칼라퀴리는 인라인뷰로 변경을 검토하라[편집]
- 쿼리 결과를 전송하는 단계에서 수행되는 스칼라 서브쿼리는 QC가 담당
- 스칼라 쿼리를 인라인뷰로 변경 => lateral 쿼리 활용법
- 스칼라쿼리
- 인라인뷰로 변경
- 스칼라쿼리


3.13.6.3 플랜에서 QC(Query Cordinator) 위치를 확인 하라[편집]
3.13.6.3.1 DELETE 구문[편집]
- 튜닝전
- 튜닝 후


3.13.6.3.2 MERGE 구문[편집]
- 튜닝 전
- 튜닝 후



3.13.6.4 BROADCAST 테이블을 찾아라[편집]
- 대용량 임시/템프 테이블에 주의하라
- - 데이터 전환 이나 인터페이스를 위한 중간(임시) 테이블 생성시 반드시 중간 테이블에 대한 통계정보를 생성토록 한다.
- - 임시테이블은 주로 통계 정보가 생성되어 있지 않아. 통계정보 오류로 인해 브로드캐스트로 처리되는 경우가 많음.
- TEMP테이블 스페이스가 Full 차서 중지(ORA-01652 에러) 되는 경우가 많음
3.13.6.5 SQL/PLAN에서 튜닝 대상을 찾아라[편집]
- rownum => row_number() 윈도우 함수로 변경
- S->P 분산 프로세스
- round - robin

- 플랜

- - NL조인으로 round - robin 으로 처리중
- 튜닝 조치

- - HASH 조인 으로 변경
- 튜닝 결과 플랜 정보

3.13.6.6 조인이 효율적인지 검토 하라[편집]



3.13.6.7 심플하게 튜닝 하는 방법은 없을까?[편집]
- opt_param('_parallel_broadcast_enabled','false')
- pq_distribute(A hash hash)

3.13.7 입력/수정 성능저하시 검토 사항[편집]
3.13.7.1 INSERT 처리가 느릴때(SELECT~INSERT시 SELECT는 빠른데 INSERT가 느린경우)[편집]
3.13.7.2 시퀀스를 사용하는경우[편집]
- sequence cache size 증가 검토
- default 20 => 2000이상
3.13.7.3 DB링크 병렬처리 체크사항[편집]
- 소스디비의 프로세스 최대갯수 확인 필요
- 옵티마이져가 쿼리 변형을 수행함
- 쿼리 변형 방지 힌트 /*+ no_query_transformation */
- dblink로 가져올때는 병렬처리 불가
3.13.8 데이터 전환시 사용하는 병렬처리[편집]
3.13.8.1 데이터 전환을 위한 최적 세션 옵션[편집]
-- 세션에서 병렬 쿼리 작업 절차
ALTER SESSION ENABLE PARALLEL DML;
ALTER SESSION SET HASH_AREA_SIZE = 1024000000;
ALTER SESSION SET SORT_AREA_SIZE = 2147483647; -- 최대 2기가
ALTER SESSION SET SORT_AREA_RETAINED_SIZE = 2147483647;
ALTER SESSION SET WORKAREA_SIZE_POLICY = MANUAL;
-- 사용자가 지정한 sort_area_size가 모든 병렬 서버에게 적용.
-- sort_area_size를 크게 설정한 상태에서 지나치게 큰 병렬도를 지정하면
-- OS 레벨에서 페이징이 발생하고 심할 경우 시스템을 마비시킬 수 있음.
ALTER SESSION SET SKIP_UNUSABLE_INDEXES = TRUE;
ALTER SESSION SET DB_FILE_MULTIBLOCK_READ_COUNT=256; -- AIX는 최대 512
ALTER SESSION SET "_sort_multiblock_read_count" = 256;
ALTER SESSION SET "_db_file_optimizer_read_count" = 256;
ALTER SESSION SET "_db_file_exec_read_count" = 256;
ALTER SESSION SET "_serial_direct_read" = TRUE;
-- 병렬 실행 메시지 사이즈 32K
alter system set parallel_execution_message_size = 32768; -- 16384 -- 기본3.13.8.2 대량 테이블 건수 조회시 index_ffs,parallel_index 힌트[편집]
- index fast full scan은 병렬 조회 가능
- parallel_index 힌트는 는 index_ffs, index 힌트와 같이 사용
- 파티션 인덱스이면 병렬 조회 가능
select /*+ parallel_index(A TB_XXX_PK 8) index_ffs(A TB_XXX_PK) */ count(*)
from TB_XXX3.14 쿼리 변환 종류[편집]
filter_1 "서브쿼리 Unnesting" 과 "뷰 Merging" 이 비용기반 쿼리 변환으로 전환됨
filter_2 조건절 Pushing 중 "조인 조건 PushDown" 도 비용기반 쿼리 변환으로 전환
filter_3 나머지는 변환된 쿼리가 항상 더 나은 성능을 제공하므로 비용기반으로 전환이 불필요
3.14.1 서브쿼리 Unnesting[편집]
- UNNEST_SUBQUERY 세션 매개변수를 TRUE로 설정하면 하위 쿼리 중첩 해제가 활성화됩니다.
- 서브 쿼리의 중첩을 해제하여 메인쿼리에 병합토록 지시하여 옵티마이저가 액세스 경로 및 조인을 평가할 때 이들을 함께 고려할 수 있도록 합니다.
3.14.1.1 UNNEST 힌트[편집]
/*+ UNNEST */- 서브쿼리를 Unnesting 함을써 조인방식으로 최적화하도록 유도.
- 즉,서브쿼리를 메인쿼리절의 FROM절로 올리도록 쿼리를 변형한다.
3.14.1.3 옵티마이저가 중첩해제를 못하는 경우[편집]
- ROWNUM 가상컬럼
- 집합 연산자 중 하나
- 중첩집계함수,서브쿼리의 외부(바깥) 쿼리 블록이 아닌 쿼리블록에 상호연관함수가 포함 된 계층적 서브쿼리(connect by ) 및 서브쿼리가 포함됩니다.
3.14.1.4 옵티마이저가 자동 중첩해제(UNNEST) 하는 경우[편집]
- 연관관계가 없는 IN 절의 하위 쿼리
- IN 과 EXISTS 의 연관된 서브쿼리, 집계 함수 또는 GROUP BY 절을 포함하지 않는 경우
- 옵티마이저에 추가서브쿼리 유형의 중첩을 해제하도록 지시하여 확장 서브쿼리 중첩해제를 활성화 할 수 있습니다.
- 서브쿼리에 HASH_AJ 또는 MERGE_AJ 힌트를 지정하여 상관되지 않은 NOT IN 서브쿼리의 중첩을 해제 할 수 있음.
- 서브쿼리에 UNNEST 힌트를 지정하여 다른 서브쿼리를 중첩 해제 할 수 있습니다.
- 반대로 NO_UNNEST 힌트는 기존 서브쿼리 형태를 유지 하고 필터방식으로 실행계획이 수립되도록 하는 힌트임.
- WHERE절에 사용되는 서브쿼리를 중첩 서브쿼리(Nested Subquery)라고 하며 IN, EXISTS 관계없이 메인쿼리에서 읽히는 FILTER방식으로 처리되어 메인레코드 하나 읽을 때마다 서브쿼리를 반복적으로 수행하면서 조건에 맞는 데이터를 추출하는 것이다.
- 이러한 필터방식이 최적의 성능을 보장하지 않으므로 옵티마이저는 조인문으로 변경후 최적화(Unnesting) 하거나 메인과 서브쿼리를 별도의 SUB PLAN으로 분리하여 각각 최적화를 수행하는데 이때 서브쿼리에 FILTER 연산이 나타난다.
- 서브 쿼리를 Unnesting 하지 않는다면 메인쿼리의 건 마다 서브쿼리를 반복 수행하는 FILTER 연산자를 사용하기에 Unnesting 힌트는 효율적으로 사용한다면 성능 향상을 가져온다.
3.14.1.5 UNNEST 같이 쓰는 힌트[편집]
- SWAP_JOIN_INPUTS : 해쉬테이블로 올릴 테이블 지정
- NO_SWAP_JOIN_INPUTS : 해쉬테이블로 올리지 않을 테이블 지정
- NL_SJ : NL SEMI JOIN 으로 수행 되도록 지시
- HASH_SJ SWAP_JOIN_INPUTS : HASH SEMI JOIN 으로 수행 되도록 지시 하고 서브쿼리를 먼저수행(해시테이블로) 되도록 지시함.
- HASH_SJ NO_SWAP_JOIN_INPUTS : HASH SEMI JOIN 으로 수행 되도록 지시 하고 서브쿼리를 먼저수행(해시테이블로) 되지 않도록 지시함.
- NL_AJ : NOT EXISTS 쿼리를 NL JOIN ANTI 로 수행 되도록 함.
- HASH_AJ : NOT EXISTS 쿼리를 HASH JOIN ANTI 로 수행 되도록 함.
3.15 뷰 머징(View Merging)[편집]
3.15.1 뷰 머징 이란?[편집]
emoji_objects 옵티마이저는 최적화 쿼리 수행을 위해 서브 쿼리블록을 풀어서 메인 쿼리와 결합(MERGE) 하려는 특성이 있음
arrow_downward SQL 원본
SELECT *
FROM ( SELECT * FROM EMP WHERE JOB = 'SALESMAN' ) A
, ( SELECT * FROM DEPT WHERE LOC = 'CHICAGO' ) B
WHERE A.DEPTNO = B.DEPTNO;- 서브쿼리나 인라인 뷰처럼 쿼리를 블록화 할 시, 가독성이 더 좋기 때문에 습관적으로 사용
arrow_downward View Merging 으로 오라클 내부에서 아래 형태로 SQL 변환
SELECT *
FROM EMP A
, DEPT B
WHERE A.DEPTNO = B.DEPTNO
AND A.JOB = 'SALESMAN'
AND B.LOC = 'CHICAGO';- View Merging 이유 : 옵티마이저가 더 다양한 액세스 경로를 조사대상으로 삼을 수 있음
3.15.2 View Merging 제어 힌트[편집]
- /*+ MERGE */
- /*+ NO_MERGE */
3.15.3 단순 뷰(Simple View) Merging[편집]
- 가능한 조건
- 조건절과 조인문만을 포함하는 단순 뷰(Simple View)일 경우, no_merge 힌트를 사용하지 않는 한 언제든 Merging 발생
- group by, distinct 연산을 포함하는 복합뷰(Complex View)는 파라미터 설정 또는 힌트 사용에 의해서만 뷰 Merging 가능
- 불가능한 조건
- 집합 연산자, connect by, rownum 등을 포함한 복합 뷰(Non-mergeable Views)는 뷰 Merging 불가능
-- Simple View 예제
create or replace view emp_salesman as
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where job = 'SALESMAN';3.15.3.1 Simple View 뷰 No Merging 최적화[편집]
SQL> select /*+ no_merge(e) */ e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp_salesman e, dept d
3 where d.deptno = e.deptno
4 and e.sal >= 1500 ;
EMPNO ENAME JOB MGR SAL DNAME
---------- ---------- --------- ---------- ---------- --------------
7844 TURNER SALESMAN 7698 1500 SALES
7499 ALLEN SALESMAN 7698 1600 SALES
Execution Plan
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 156 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 156 | 4 (0)| 00:00:01 |
| 3 | VIEW | EMP_SALESMAN | 2 | 130 | 2 (0)| 00:00:01 |
|* 4 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 7 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("JOB"='SALESMAN')
5 - access("SAL">=1500)
6 - access("D"."DEPTNO"="E"."DEPTNO")3.15.3.2 Simple View 뷰 Merging 최적화[편집]
SQL> select /*+ merge(e) */ e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp_salesman e, dept d
3 where d.deptno = e.deptno
4 and e.sal >= 1500 ;
Execution Plan
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 84 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 84 | 4 (0)| 00:00:01 |
|* 3 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("JOB"='SALESMAN')
4 - access("SAL">=1500)
5 - access("D"."DEPTNO"="DEPTNO")arrow_downward 일반 조인문
SQL> select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
2 from emp e, dept d
3 where d.deptno = e.deptno
4 and e.job = 'SALESMAN'
5 and e.sal >= 1500;
Execution Plan
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 84 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 2 | 84 | 4 (0)| 00:00:01 |
|* 3 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 58 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_SAL_IDX | 8 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 13 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("E"."JOB"='SALESMAN')
4 - access("E"."SAL">=1500)
5 - access("D"."DEPTNO"="E"."DEPTNO")* 단순 뷰를 Merging 할 경우, 파라미터 or 힌트 설정을 하지 않을 경우 일반 조인문과 똑같은 형태로 변환 후 처리
3.15.4 복합 뷰(Complex View) Merging[편집]
- group by절 , select-list에 distinct연산자 포함하는 복합 뷰
- _complex_view_merging 파라미터 값이 true로 설정할 때만 Merging 발생
- 10g에서는 복합 뷰 Merging을 일단 시도하지만, 원본 쿼리에 대해서도 비용을 같이 계산해 Merging했을 때의 비용이 더 낮을 때만 그것을 채택 (비용기반 쿼리 변환)
- 10g 이전 _complex_view_merging 파라미터 기본 값 (8i : false, 9i : true)
- complex_view_merging 파라미터를 true로 설정해도 Merging 될 수 없는 복합 뷰
- 집합(set)연산자( union, union all, intersect, minus )
- connect by절
- ROWNUM pseudo 컬럼
- select-list에 집계 함수(avg, count, max, min, sum)사용 : group by 없이 전체를 집계하는 경우를 말함
- 분석 함수
- 복합뷰를 포함한 쿼리 (뷰 머징 발생 시)
SQL> select d.dname, avg_sal_dept
2 from dept d
3 ,(select deptno, avg(sal) avg_sal_dept from emp group by deptno) e
4 where d.deptno = e.deptno
5 and d.loc='CHICAGO';
DNAME AVG_SAL_DEPT
-------------- ------------
SALES 1566.66667
Execution Plan
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 81 | 5 (20)| 00:00:01 |
| 1 | HASH GROUP BY | | 3 | 81 | 5 (20)| 00:00:01 |
| 2 | NESTED LOOPS | | | | | |
| 3 | NESTED LOOPS | | 5 | 135 | 4 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | DEPT | 1 | 20 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_IDX_DEPTNO | 5 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 35 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("D"."LOC"='CHICAGO')
5 - access("D"."DEPTNO"="DEPTNO")
arrow_downward 복합뷰를 일반 조인절로 변경한 쿼리
SQL> select d.dname,avg(sal)
2 from dept d,emp e
3 where d.deptno=e.deptno
4 and d.loc='CHICAGO'
5 group by d.rowid,d.dname;
DNAME AVG(SAL)
-------------- ----------
SALES 1566.66667
Execution Plan
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 5 (20)| 00:00:01 |
| 1 | HASH GROUP BY | | 1 | 27 | 5 (20)| 00:00:01 |
| 2 | NESTED LOOPS | | | | | |
| 3 | NESTED LOOPS | | 5 | 135 | 4 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | DEPT | 1 | 20 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | EMP_IDX_DEPTNO | 5 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 35 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("D"."LOC"='CHICAGO')
5 - access("D"."DEPTNO"="E"."DEPTNO")
- 뷰머징이 발생 할 경우
- dept테이블에서 loc컬럼이 'CHICAGO'인 데이터를 먼저 필터링하고 조인, 조인대상 집합만 group by 실행
- 뷰머징이 발생되지 않을 경우
- emp 테이블의 모든 테이블을 group by 한 후 필터링하게 되면서 불필요한 레코드 엑세스 발생
3.15.5 비용기반 쿼리 변환의 필요성[편집]
9i : 복합 뷰를 무조건 머징 => 대부분 더 나은 성능 제공하지만 복합뷰 머징 시 그렇지 못할 때가 많음
- no_merge 힌트 등 뷰안에 rownum 을 넣어주는 튜닝 기법 활용
10g 이후 비용기반 쿼리 변환 방식으로 처리
- _optimizer_cost_based_transformation 파라미터 사용 → 설정값 5가지 (on, off, exhaustive, linear, iteraive)
on : 적절한 것을 스스로 선택 exhaustive : cost가 가장 저렴한 것 선택 linear : 순차적 비교 후 선택 literation : 변환이 수행 유무에 따른 cost를 비교하기 위한 경우의 수로 listeration 정의
opt_param 힌트 이용으로 쿼리 레벨에서 파라미터 변경가능 (10gR2부터 제공)
3.15.6 Merging 되지 않은 뷰의 처리방식[편집]
- 1단계 : 뷰머징 시행 시 오히려 비용이 증가된다고 판단(10g이후) 되거나, 부정확한 결과 집합 가능성이 있을 시 뷰머징 포기
- 2단계 : 뷰머징이 포기 할 경우 조건절 Pushing 시도
- 3단계 : 뷰 쿼리 블록을 개별적으로 최적화된 개별 플랜을 전체 실행계획에 반영 (즉, 뷰 쿼리 수행 결과를 엑세스 쿼리에 전달)
SQL> select /*+ leading(e) use_nl(d) */ *
2 from dept d
3 ,(select /*+ NO_MERGE */ * from emp) e
4 where e.deptno = d.deptno;
14 개의 행이 선택되었습니다.
Execution Plan
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1498 | 17 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 14 | 1498 | 17 (0)| 00:00:01 |
| 3 | VIEW | | 14 | 1218 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 20 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("E"."DEPTNO"="D"."DEPTNO")
※ 실행계획의 "VIEW" 로 표시된 오퍼레이션 단계가 추가 되었을 시, 실제로 다음 단계로 넘어가기 전 중간집합을 생성하는 것은 아님3.15.7 조건절 Pushing[편집]
3.15.8 조건절 이행[편집]
- 새로운 필터 조건이 추가되면서 조인 조건이 사라진다.
- 새로운 필터 조건으로 인하여 조인 조건이 필요가 없어졌다고 생각하고 옵티마이저가 중복 산정하는 것을 방지하기 위함
- 만약 조건절 이행이 작용해 조인 조건이 사라지고 이로 인해 비용이 잘못 계산되는 문제가 발생되면 사용자가 명시적으로 새로운 필터조건을 추가하거나 조인문을 가공하는 방법 사용
- 조인문 가공 방법 예시 )
d.deptno = e.deptno + 0- 조건절 이행이 효과적인 사례
- 내부적으로 조건절 이행이 여러 곳에서 일어나고 있다. - 선분 이력을 between 조건으로 조회할 때는 인덱스 구성과 검색 범위에 따라 인덱스 스캔 효율에 많은 차이가 생긴다. 아래와 같은 쿼리에서도 범위를 더 제한적으로 줄일 수 있다.
- SQL 예시)
select *
from 상품이력 a. 주문 b
where b.거래일자 between '20090101' and '20090131'
and a.상품번호 = b.상품번호
and b.거래일자 between a.시작일자 and a.종료일자- 위의 쿼리에서는 아래와 같이 조건절을 명시적으로 추가하여 튜닝 진행
● 상품이력.시작일자 <= '20090131'
● 상품이력.종료일자 >= '20090101'
- 보통 옵티마이저가 이들 조건을 묵시적으로 추가하고 최적화를 수행하지만 명시적으로 조건절을 추가하여 튜닝하는 방법도 고려 할것
- 튜닝사례 1
- 조인 조건은 아니지만 컬럼 간 관계 정보를 통해 추가적인 조건절이 생성되었다.
- 옵티마이저에게 많은 정보를 제공할수록 SQL 성능이 더 좋아진다.
- 튜닝사례 2
- 최적의 조인순서를 결정하고 그 순서에 따라 조인문을 기술해주는 것이 매우 중요함
3.15.9 공통 표현식 제거[편집]
- 같은 조건식이 여러 곳에서 반복 사용될 경우 해당 조건식이 각 로우당 한 번씩만 평가되도록 오라클이 쿼리를 변환
- _eliminate_common_subexpr 파라미터로 제어
- 예시) 필터조건이 중복으로 기술 되어 비교연산이 두 번씩 일어나는 경우
select /* + no_expand * / * from emp e, dept d
where (e.deptno=d.deptno and e.job='CLERK' and d.loc='DALLAS')
or
(e.deptno=d.deptno and e.job='CLERK' and e.sal >= 1000)===> 옵티마이져가 아래와 같이 변환
select * from emp e, dept d
where e.deptno = d.deptno
and e.job = 'CLERK'
and (d.loc='DALLAS' or e.sal >= 1000)filter_1 비교 연산을 줄여서 성능개선
filter_2 새로운 인덱스 엑세스 조건을 사용할수 있도록 함.
-- 인덱스 생성
create index emp_job_idx on emp(job);
select * from emp e, dept d
where (e.deptno=d.deptno and e.job='CLERK' and d.loc='DALLAS')
or
(e.deptno=d.deptno and e.job='CLERK' and e.sal >=1000);
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 150 |
| 1 | NESTED LOOPS | | 3 | 150 |
| 2 | TABLE ACCESS BY INDEX ROWID | EMP | 3 | 96 |
|* 3 | INDEX RANGE SCAN | EMP_JOB_IDX | 3 | |
|* 4 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 18 |
|* 5 | INDEX UNIQUE SCAN | DEPT_PK | 1 | |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("E"."JOB"='CLERK')
4 - filter("D"."LOC"='DALLAS' OR "E"."SAL">=1000)
5 - access("E"."DEPTNO"="D"."DEPTNO")3.15.10 outer 조인을 Inner 조인으로 변환[편집]
3.15.11 실체화 뷰 쿼리로 재작성[편집]
3.15.12 star 변환[편집]
3.15.13 outer 조인 뷰에 대한 조인 조건 Pushdown[편집]
3.15.14 OR 절 튜닝 (OR-Expansion)[편집]
- WHERE절에서 OR 구문 사용시 옵티마이저가 UNION ALL로 분리 하는 작업을 대신해 주는 경우를 'OR-Expansion'이라 함.
- OR절에 사용된 컬럼이 인덱스에 있어야 함
- 힌트
- USE_CONCAT(OR-Expansion 유도)
- NO_EXPAND(OR-Expansion 방지)
- OR-Expansion 일어났을 때의 실행계획과 Predicate 정보
-----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 7 | 224 |
| 1 | CONCATENATION <== 여기 | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 3 | 96 |
|* 3 | INDEX RANGE SCAN | EMP_JOB_IDX | 3 | |
|* 4 | TABLE ACCESS BY INDEX ROWID| EMP | 4 | 128 |
|* 5 | INDEX RANGE SCAN | EMP_DEPTNO_IDX | 5 | |
-----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("JOB"='CLERK')
4 - filter(LNNVL("JOB"='CLERK'))
5 - access("DEPTNO"=20)3.15.14.1 NVL()/DECODE() 조건식에 대한 OR-Expansion[편집]
select * from emp
where deptno = nvl(:deptno, deptno)
and ename like :ename || '%'
또는
select * from emp
where deptno = decode(:deptno, null, deptno, :deptno)
and ename like :ename || '%'- :deptno 변수 값 입력 여부에 따라 다른 인덱스를 사용 함
- :deptno에 null값을 입력했을 때(위쪽 브랜치)는 EMP_ENAME_IDX 사용, null값이 아닌 경우(아래쪽 브랜치) EMP_DEPTNO_IDX 사용
----------------------------------------------------------------------
| Id | Operation |Name |Rows | Bytes |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 111 |
| 1 | CONCATENATION | | | |
| 2 | FILTER | | | |
| 3 | TABLE ACCESS (BY INDEX ROWID)|EMP | 2 | 74 |
| 4 | INDEX (RANGE SCAN) |EMP_ENAME_IDX | 2 | |
| 5 | FILTER | | | |
| 6 | TABLE ACCESS (BY INDEX ROWID)|EMP | 1 | 37 |
| 7 | INDEX (RANGE SCAN) |EMP_DEPTNO_IDX | 5 | |
----------------------------------------------------------------------- _or_expand_nvl_predicate 파라미터로 제어
- nvl,decode를 여러 컬럼에 사용한 경우 그 중 변별력이 가장 좋은 컬럼 기준으로 한번만 분기가 일어나기 때문에 옵션조건이 복잡할 때는 수동으로 union all 분기를 해 줘야만 한다.
3.16 쿼리 변환 두 가지 방식[편집]
3.16.1 휴리스틱 쿼리 변환[편집]
: 결과만 보장된다면 무조건 쿼리 변환을 수행
3.16.2 비용기반 쿼리 변환[편집]
: 변환된 쿼리의 비용이 더 낮을 때만 그것을 사용하고, 그렇지 않을 때는 원본 쿼리 그대로 두고 최적화를 수행한다.
3.17 DB LINK를 사용한 분산 쿼리의 튜닝[편집]
3.17.1 Nested Loop을 피하고, Hash Join 처리 하여, Network Round Trip 을 줄인다[편집]
- 네트웍을 통한 분산 SQL 튜닝에서,로컬 DB에서만 수행되는 SQL과 튜닝포인트가 다른 점
- 분산 DB QUERY의 NESTED LOOP 조인은 조인 건수만큼의 네트웍 RoundTrip이 발생
- 조인건수가 많을 경우 네트웍 Round Trip 에 대량 시간 발생
- 가급적 Sort-Merge나 Hash Join으로 수행되도록 PLAN을 조정하여, 조인으로 인한 Network Roundtrip을 줄이도록 유도
3.17.2 Driving_Site 힌트를 이용하여, 리모트 DB가 SQL 수행의 주체가 되도록 한다.[편집]
3.17.3 바인드변수나 문자열값의 직접 사용은 PLAN을 고정 시키게 된다.[편집]
3.17.3.1 Driving_Site 힌트로 리모트DB를 지정하여, PLAN을 조정 하는 경우,[편집]
- SQL에 바인드 변수 나 직접적인 문자열 값이 있는 경우 힌트가 원하는대로 적용되지 않음.
3.17.3.2 SQL에 SELECT-LIST에 문자열값 이나 바인드 변수 값이 있으면,[편집]
- PLAN상 Remote에서 수행이 되지 않고 항상 로컬에서 수행 됨.
- 이 경우 문자열이나 바인드 변수값을 제외한 SQL을 인라인 뷰에서 수행하게 하여 , Remote DB에서 해당 SQL이
- 수행되도록 하고, 인라인 뷰 밖에서 필요한 문자열 값을 주고, NO_MERGE 힌트를 사용하도록 합니다.
- * 변경 전 (DRIVING_SITE 힌트가 반영 되지 않음 )
INSERT INTO T3
SELECT /*+ DRIVING_SITE(T1) */
‘ADD_COLUMN’, T1.*, T2.*
FROM T1@LINK1 T1, T1@LINK1 T2
WHERE A.COL1 = B.COL2;- * 변경 후 (DRIVING_SITE 힌트 반영)
INSERT INTO T3
SELECT /*+ NO_MERGE(A) DRIVING_SITE(A) */ 'ADD_COLUMN', A.*
FROM (
-- 리모트DB 에서 조인이 이루어 지도록
SELECT T1.*, T2.*
FROM T1@LINK1 T1, T1@LINK1 T2
WHERE A.COL1 = B.COL2) A;- DRIVING_SITE 힌트를 줘도 리모트 DB에서 T1과 T2테이블을 로컬 DB로 읽어와서 로컬에서 조인.
- 리모트DB에서 조인해서 결과값만 받는 것이 일반적으로 유리함.
- 문자열값을 밖으로 뺀 인라인뷰와 NO_MERGE 힌트를 이용하여 원하는 PLAN으로 수정 가능.
- 뷰를 이용하여, PLAN 조정
- REMOTE 사이트의 테이블 여러개 RK 조인될 경우 해당 SQL을 해당 리모트사이트에 뷰를 만들어 놓는다면, 한번의 Remote Operation 만이 이루어질 것입니다.
- 즉, Driving_site 힌트가 제대로 수행이 되지 않는 경우 수행의 주체가 되기를 원하는 Remote DB상에 View를 생성하여 해당 View 를 SELECT 하여 PLAN을 조정
3.17.4 dblink로 가져올때는 병렬처리 불가[편집]
- 단일 dblink 통해 "병렬"을 수행할 수 없으며 dblink의 remote서버 병렬을 수행할 수 있지만 로컬로 가져올때는 네트워크 파이프가 하나만 있으므로 직렬로 연결됨
- 작업을 더 작은 조각으로 나누어야 함
- 가장 쉬운 방법은 각 파티션에 대한 작업(dbms_job, dbms_scheduler)을 설정하고 해당 작업에서 로드를 수행하는 것. 로컬 테이블이 같은 방식으로 분할된 경우 - 각 작업은 다음과 같이 동적 SQL을 사용하여 파티션을 로드합니다.
insert /*+ append */ into localtable partition( PNAME )
select * from remotetable@dblink partition(PNAME)3.18 디비링크 네트워크 사용량 모니터링[편집]
3.18.1 수신된 바이트 수[편집]
-- total number of bytes received
select s.value
from v$sysstat s
, v$statname n
where n.name='bytes received via SQL*Net from dblink'
and n.statistic#=s.statistic#;3.18.2 송신한 바이트 수[편집]
-- total number of bytes sent
select s.value
from v$sysstat s
, v$statname n
where n.name='bytes sent via SQL*Net to dblink'
and n.statistic#=s.statistic#;3.18.3 송/수신 정보[편집]
--SQL*Net bytes sent for a session.
select *
from gv$sesstat
join v$statname
on gv$sesstat.statistic# = v$statname.statistic#
-- You probably also want to filter for a specific INST_ID and SID here.
where lower(display_name) like '%sql*net%';--SQL*Net bytes sent for the entire system.
select *
from gv$sysstat
where lower(name) like '%sql*net%'
order by value desc;4.1 파이썬 설치[편집]
4.2 파이썬 언어[편집]
4.3 파이썬 모듈[편집]
- 확장 모듈
- 판다스(Pandas)
- 파이썬 멀티프로세싱
- 파이썬 메모리 쉐어
- 챠트
- DB 접속
- 메시징 처리
- CONFIG 설정
- 스케줄러
- 파이썬 파일복사 자동스케줄러
- 로깅
- 데몬
- 자동화
- 머신러닝
- 케라스 인공지능
6.1 UNIX/LINUX[편집]
6.1.2 우분투[편집]
6.2 윈도우[편집]
6.2.2 윈도우 명령어[편집]
이용자 수 : 16
- ↑ -wise : (접미사)~방식으로 뜻